前言
在前端领域,目前不断地有 design2code 工具涌现。即给定视觉稿识别出里面的元素并将其转换成代码。它们底层技术都离不开深度学习中的「目标检测」。最近有幸接触到这块的内容,实践下来发现深度学习也并不那么的高深莫测,这里用一篇文章带大家快速入门目标检测技术。并提供一个开箱即用的目标检测框架。
「【划重点!!】目标检测通俗地来说就是识别出给定视图中的物体,并将其定位。」

准备
团队这边的目标检测是基于tensorflow提供的object detection API。整个训练的过程可以简要概括为训练集的准备和训练。
训练集准备:
- 人工标注图片,并转成
xml格式 - 将
xml转成tf能识别的数据格式即tfrecord
训练过程:
-
配置训练参数,这里需要配置
- 目标检测算法类型
- 目标类别数量
- 训练步长
- 训练部署训练集路径
- 模型输出路径
- *以及可以基于前人训练好的模型微调
- 基于
slim模块实现模型训练
过程
环境配置
我们需要准备好python的环境。系统内置的python一般为2.7.x,而训练需要的版本为3+。这里推荐使用pyenv进行python的版本控制与切换。
$ brew install pyenv
$ brew install pyenv-virtualenv
$ pyenv virtualenv 3.6.5
$ pyenv activate 环境配置完成后,就可以着手开始我们的训练了。
训练集准备
首先我们需要准备大量的训练集,可以针对自己的需求手动标注。我们用的是labelImg这个python工具。
(PS:如果只是想体验下目标检测过程,可以从网上下载已经标注好的训练集和测试集。目标检测训练数据集资料汇总。
本文的测试范例用的是扑克牌训练集,来源于github上的大佬 >>> 仓库地址。)
labelImg安装使用具体参考文档。简要步骤如下:
# 基于上步切换到python3环境
# 安装
$ pip install labelImg
# 启动
$ labelImg手动框选出目标,并储存为xml文件。
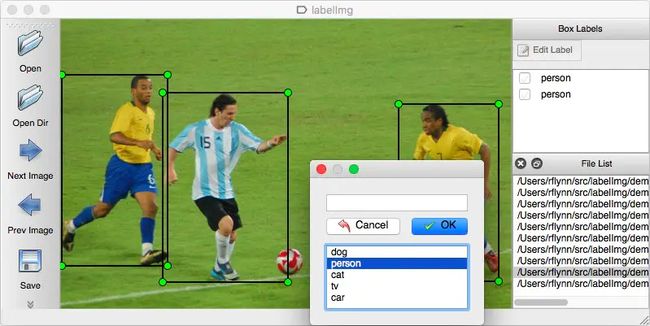
最后会得到image和对应的xml(annotations)两个目录。(建议分目录存储)

训练配置
tf object detection API已经为我们准备了部分已经训练好的模型。我们可以对基于它们做fine-tuning(微调)从而来训练我们的模型。
Tensorflow detection model zoo
这里包含了SSD/Faster RCNN/RCNN等目标检测常用算法,比较遗憾的是没有Yolo的。如果有一定深度学习基础的同学可以基于tf训练自己的Yolo模型。
先看一下目录的基本结构
- resources:文件转换、训练、模型导出目标代码
- config:配置文件,包括label_map 和 算法配置文件
- model:fine_tuning模型
- object_detection:tf object detection api
- slim:tf slim目标代码
- train_assets:训练集
- train_data:训练过程中输出的文件
1、将xml转成tfrecord
在使用labelImg标注后我们会得到image和对应xml两份文件,要进行训练还需要将其转换成tf能识别的tfrecord格式文件。
tf object detection已经提供了相应的文件转换API。
tf/models中目标代码路径 >>>
object_detection/dataset_tools/create_pascal_tf_record.py
上面提供的框架中已经将其处理好了
# 根目录下调用
$ python resources/convert.py这时候就能得到train.record文件。
2、将slim路径添加到PATH中
这一步框架已经处理了,可以忽略,了解即可。
$ export PYTHONPATH=$PYTHONPATH:'pwd':'pwd'/slim3、模型选用
模型指的是用以fine-tuning的由前人训练好的模型。可以在上面的model zoo选择下载。这里采用的是SSD。上图model目录。
4、文件配置
训练前我们需要配置检测目标的类别,在config/label_map中定义
# config/label_map.pbtxt
item {
id: 1
name: 'nine'
}
item {
id: 2
name: 'ten'
}
...more同时需要配置算法文件(下载fine_tuning模型后对其xxx.config文件进行参数调整)重点配置如下
model {
ssd {
num_classes: 6 #用以目标检测的类别数量
box_coder {...}
fine_tune_checkpoint: "" #本地fine_tuning模型路径
num_steps: 10000 #训练步长
}
train_input_reader: {
tf_record_input_reader {
input_path: "" #tfrecord文件路径
}
label_map_path: "" #本地label_map路径
}完成配置后,在根目录中调用以下命令
$ python resources/train.py我们这边使用的训练api是tf/model/object_detection/legacy/train.py,tf/model/object_detection/model_main也可以提供相应的功能,但是在使用cpu训练下会报错,于是换成了legacy/train。
如果看到以下输出就说明已经成功进行模型训练了。
这里的step指的是当前训练的步数,loss指当前函数损失值,loss越小,说明模型越接近准确。

同时可以使用tf提供的命令行工具tensorboard实时查看训练结果。
$ tensorboard --logdir=train_data/ssd这里可以看到,losses波动特别大,显然这个模型训练得不是特别好。这里等后面模型调优我们再来讲。

模型导出
如果看到如下输出,说明模型已经训练完成。
我们此时需要对训练完成的数据进行模型导出。tf object detection也提供了相应的api,具体文件路径是tf/model/object_detection/export_inference_graph.py。
使用提供的框架可以直接调用
$ python resources/export.py正常的话会得到如下结构的文件,其中frozn_inference_graph.pb就是训练所得的模型了。

预测
在得到了训练好的模型之后,我们就能用它对我们的视图进行目标检测了。
预测这边tf提供的目标代码是tf/model/object_detection/object_detection_tutorial.py
可以自行参考,根据自己需求改写。
也可以在框架代码根目录下执行
$ python resources/detection.py完成后会在train_detections/ssd目录下生成被标记好的预测图。

评估
单看上图,我们的预测结果还是准确的,那对于目标物体模糊或者被遮挡的情况呢?我们单纯跑一张图预测的话其实还不足以评估模型的准确性,所以tf也提供了相应模型评估的函数。
具体可以参考tf/model/object_detection/legacy/eval
也可以在框架代码valid_assets/下配置测试集,包括images和对应的xml。完成之后需要:
- 将
xml转成tfrecord - 配置算法文件
xxx.config
eval_config: {
num_examples: 67 # 测试集数量
# Note: The below line limits the evaluation process to 10 evaluations.
# Remove the below line to evaluate indefinitely.
max_evals: 1 # 评估次数,1次即可
}
eval_input_reader: {
tf_record_input_reader {
input_path: "" # valid tfrecord文件路径
}
label_map_path: "" # label_map路径
shuffle: false
num_readers: 1
}配置完成后在根目录下依次执行
$ python resources/convert.py valid
$ python resources/eval.py控制台会输出该模型下每个类别的检测准确率。

微调
如果训练出的模型准确率不是很高,我们需要对配置进行微调。这里主要可以通过改变步长、算法、batch_size等方式。
算法
目标检测的明星算法是SSD/Faster RCNN/YOLO,有关这3个算法的区别可以参考一下这篇文章
【目标检测从放弃到入门】SSD / RCNN / YOLO通俗讲解
步长
步长指训练迭代的总长度,可以通过tensorboard实时观测。步长设置过大可能会带来过拟合的问题,设置不够则会是欠拟合。
batch_sizebatch_size指一次迭代使用的样本数量。如果训练集足够小,可以使用全数据集。而对于大数据集,可以使用一个适中的batch_size或者走向另一个极端就是每次只训练一个样本,即 batch_Size = 1。
对于ssd算法来说,使用小的batch_size貌似会造成losses波动大的情况而迟迟达不到一个稳定的losses值。
其他还待深入实践。后续再发一篇文章更新吧~~~