linux内核分析———SLAB原理及实现
Slab原理及实现
1. 整体关系图
!
注:SLAB,SLOB,SLUB都是内核提供的分配器,其前端接口都是一致的,其中SLAB是通用的分配器,SLOB针对微小的嵌入式系统,其算法较为简单(最先适配算法),SLUB是面向配备大量物理内存的大规模并行系统,通过也描述符中未使用的字段来管理页组,降低SLUB本身数据结构的内存开销。
2. 相关数据结构
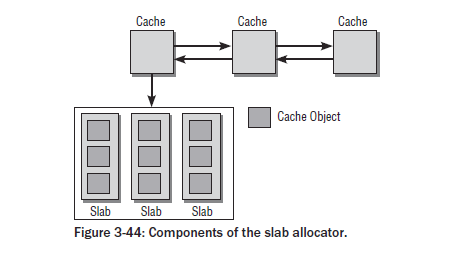
2.1 缓存kmem_cache (/mm/slab.c)
struct kmem_cache {
struct array_cache *array[NR_CPUS];
unsigned int batchcount;//从本地高速缓存交换的对象的数量
unsigned int limit;//本地高速缓存中空闲对象的数量
unsigned int shared;//是否存在共享CPU高速缓存
unsigned int buffer_size;//对象长度+填充字节
u32 reciprocal_buffer_size;//倒数,加快计算
unsigned int flags;/*高速缓存永久性的标志,当前只CFLGS_OFF_SLAB*/
unsigned int num;/*封装在一个单独的slab中的对象数目*/
unsigned int gfporder;/*每个slab包含的页框数取2为底的对数*/
gfp_t gfpflags;/* e.g. GFP_DMA分配页框是传递给伙伴系统的标志*/
size_t colour; /* cache colouring range缓存的颜色个数free/aln*/
unsigned int colour_off;
/*slab的基本对齐偏移,为aln的整数倍,用来计算left_over*/
struct kmem_cache *slabp_cache;
//slab描述符放在外部时使用,其指向的高速缓存来存储描述符
unsigned int slab_size;//单个slab头的大小,包括SLAB和对象描述符
unsigned int dflags; /*描述高速缓存动态属性,目前没用*/
/*构造函数*/
void(*ctor)(struct kmem_cache *, void *);
const char *name;
struct list_head next;//高速缓存描述符双向链表指针
/*统计量*/
#if STATS
unsigned long num_active;
unsigned long num_allocations;
unsigned long high_mark;
unsigned long grown;
unsigned long reaped;
unsigned long errors;
unsigned long max_freeable;
unsignedlong node_allocs;
unsigned long node_frees;
unsigned long node_overflow;
atomic_t allochit;
atomic_t allocmiss;
atomic_t freehit;
atomic_t freemiss;
#endif
#if DEBUG
into bj_offset;//对象间的偏移
int obj_size;//对象本身的大小,
#endif
//存放的是所有节点对应的相关数据。每个节点拥有各自的数据;
struc tkmem_list3 *nodelists[MAX_NUMNODES];/
}
2.2 array_cache本地高速缓存,每个CPU对应一个该结构
/*
* struct array_cache
*
*Purpose:
* - LIFO ordering, to hand out cache-warm objectsfrom _alloc
* - reduce the number of linked list operations
* - reduce spinlock operations
*
* The limit is stored in the per-cpu structure toreduce the data cache
* footprint.
*
*/
struct array_cache {
unsigned int avail;//可用对象数目
unsigned int limit;//可拥有的最大对象数目,和kmem_cache中一样
unsigned int batchcount;//同kmem_cache
unsigned int touched;//是否在收缩后被访问过
spinlock_t lock;
void *entry[]; /*伪数组,没有任何数据项,其后为释放的对象指针数组*/
};
2.3 kmem_list3管理slab链表的数据结构
/*
* The slab lists for all objects.
*/
struct kmem_list3 {
struct list_head slabs_partial; /* partial listfirst, better asm code */
struct list_head slabs_full;
struct list_head slabs_free;
unsigned long free_objects;//半空和全空链表中对象的个数
unsigned int free_limit;//所有slab上允许未使用的对象最大数目
unsigned int colour_next; /* 下一个slab的颜色*/
spinlock_t list_lock;
struct array_cache *shared; /* shared per node */
struct array_cache **alien; /* on other nodes */
unsigned long next_reap; /* 两次缓存收缩时的间隔,降低次数,提高性能*/
int free_touched; /* 0收缩1获取一个对象*/
};
2.4 slab对象
struct slab {
struct list_head list;//SLAB所在的链表
unsigned long colouroff;//SLAB中第一个对象的偏移
void *s_mem; /* including colour offset 第一个对象的地址*/
unsigned int inuse; /* num of objs active in slab被使用的对象数目*/
kmem_bufctl_t free;//下一个空闲对象的下标
unsigned short nodeid;//用于寻址在高速缓存中kmem_list3的下标
};
3. 相关函数
3.1 kmem_cache_create (mm/slab.c)
/**
* kmem_cache_create - Create a cache.
* @name: A string which is used in /proc/slabinfo toidentify this cache.
* @size: The size of objects to be created in thiscache.
* @align: The required alignment for the objects.
* @flags: SLAB flags
* @ctor: A constructor for the objects.
*
* Returns a ptr to the cache on success, NULL onfailure.
* Cannot be calledwithin a int, but can be interrupted.
* The @ctor is run when new pages are allocated bythe cache.
struct kmem_cache *
kmem_cache_create (const char *name, size_t size,size_t align,unsigned long flags,
void (*ctor)(struct kmem_cache *, void *))
{
size_t left_over, slab_size, ralign;
struct kmem_cache *cachep = NULL, *pc;
/*参数有效性检查,名字有效性,对象长度比处理器字长还短,或者超过了允许分配的最大值,不能处在中断上下文,可能导致睡眠*/
if (!name || in_interrupt() || (size KMALLOC_MAX_SIZE) {
printk(KERN_ERR "%s: Early error in slab%s\n", __FUNCTION__,
name);
BUG();
}
/*获得锁*/
mutex_lock(&cache_chain_mutex);
....
/*
将大小舍入到处理器字长的倍数
*/
if (size & (BYTES_PER_WORD - 1)) {
size += (BYTES_PER_WORD - 1);
size &= ~(BYTES_PER_WORD - 1);
}
/* 计算对齐值*/
//如果设置了该标志,则用硬件缓存行
if (flags & SLAB_HWCACHE_ALIGN) {
ralign = cache_line_size();//获得硬件缓存行
//如果对象足够小,则将对齐值减半,,尽可能增加单行对象数目
while (size <= ralign )
ralign /= 2;
} else {//否则使用处理器字长
ralign = BYTES_PER_WORD;
}
/*体系结构强制最小值*/
if (ralign < ARCH_SLAB_MINALIGN) {
ralign = ARCH_SLAB_MINALIGN;
}
/*调用者强制对齐值*/
if (ralign < align) {
ralign = align;
}
/*计算出对齐值.*/
align = ralign;
/*从cache_cache缓存中分配一个kmem_cache新实例*/
cachep = kmem_cache_zalloc(&cache_cache,GFP_KERNEL);
//填充cachep成员
cachep->obj_size = size;//将填充后的对象赋值,
//设置SLAB头位置
//如果对象大小超过一页的1/8则放在外部
if ((size >= (PAGE_SIZE >> 3)) &&!slab_early_init)
flags |= CFLGS_OFF_SLAB;//设置将SLAB放在外部
size = ALIGN(size, align);//按对齐大小对齐
//计算缓存长度
//利用calculate_slab_order迭代来找到理想的slab长度,size指对象的长度
left_over = calculate_slab_order(cachep, size,align, flags);
if (!cachep->num) {//NUM指SLAB对象的数目
printk(KERN_ERR
"kmem_cache_create: couldn't createcache %s.\n", name);
kmem_cache_free(&cache_cache, cachep);
cachep = NULL;
goto oops;
}
//再次计算SLAB头存放位置
//计算slab头的大小=对象的数目x对象描述符的大小+slab描述符
slab_size = ALIGN(cachep->num *sizeof(kmem_bufctl_t)
+ sizeof(struct slab), align);
//如果有足够的空间,容纳SLAB头则将其放在SLAB上
if (flags & CFLGS_OFF_SLAB && left_over>= slab_size) {
flags &= ~CFLGS_OFF_SLAB;
left_over -= slab_size;
}
//如果标志仍然存在,则计算外部的slab头大小
if (flags & CFLGS_OFF_SLAB) {
/* 此处不用对齐了*/
slab_size =
cachep->num * sizeof(kmem_bufctl_t) +sizeof(struct slab);
}
//着色
cachep->colour_off =cache_line_size();//
/* Offset must be a multiple of the alignment. */
if (cachep->colour_off< align)
cachep->colour_off = align;
cachep->colour = left_over /cachep->colour_off;//获取颜色值
cachep->slab_size = slab_size;
cachep->flags = flags;
cachep->gfpflags = 0; //分配页框的标志
if (CONFIG_ZONE_DMA_FLAG && (flags &SLAB_CACHE_DMA))
cachep->gfpflags |= GFP_DMA;
cachep->buffer_size = size;
cachep->reciprocal_buffer_size =reciprocal_value(size);
//如果在SLAB头在外部,则找一个合适的缓存指向slabp_cache,从通用缓存中
if (flags & CFLGS_OFF_SLAB) {
cachep->slabp_cache= kmem_find_general_cachep(slab_size, 0u);
BUG_ON(ZERO_OR_NULL_PTR(cachep->slabp_cache));
}
cachep->ctor = ctor;
cachep->name = name;
//设置per-cpu缓存
if (setup_cpu_cache(cachep)){
__kmem_cache_destroy(cachep);
cachep = NULL;
goto oops;
}
/* 加入链表*/
list_add(&cachep->next, &cache_chain);
/*解锁*/
mutex_unlock(&cache_chain_mutex);
return cachep;
}
3.2 对象分配函数kmem_cache_alloc(kmem_cache_t* cachep, gfp_t flags)
static inline void *____cache_alloc(struct kmem_cache *cachep,gfp_t flags)
{
void *objp;
struct array_cache *ac;
check_irq_off();
ac = cpu_cache_get(cachep);//获得高速缓存中CPU缓存
if (likely(ac->avail)) {//如果CPU缓存中还有空间,则从中分配
STATS_INC_ALLOCHIT(cachep);
ac->touched = 1;
objp = ac->entry[--ac->avail];
} else {//否则要填充CPU高速缓存了
STATS_INC_ALLOCMISS(cachep);
objp = cache_alloc_refill(cachep,flags);
}
return objp;
}
//填充CPU高速缓存
static void *cache_alloc_refill(structkmem_cache *cachep, gfp_t flags)
{
int batchcount;
struct kmem_list3 *l3;
struct array_cache *ac;
int node;
ac = cpu_cache_get(cachep);//获得高所缓存所在本地CPU缓存
retry:
batchcount = ac->batchcount;
if (!ac->touched && batchcount > BATCHREFILL_LIMIT){
/*如果不经常活动,则部分填充*/
batchcount = BATCHREFILL_LIMIT;//16
}
l3 = cachep->nodelists[node];//获得相应的kmem_list3结构体
...
/* 先考虑从共享本地CPU高速缓存*/
if (l3->shared && transfer_objects(ac, l3->shared,batchcount))
goto alloc_done;
while (batchcount > 0) {//老老实实的从本高速缓存分配
struct list_head *entry;
struct slab *slabp;
/* Get slab alloc is to come from. */
entry = l3->slabs_partial.next;//半满的链表
if (entry == &l3->slabs_partial) {//如果半空的都没了,找全空的
l3->free_touched = 1;
entry = l3->slabs_free.next;
if (entry == &l3->slabs_free)//全空的也没了,必须扩充了
cache_grow(cachep, flags | GFP_THISNODE, node, NULL);
}
//此时,已经找到了一个链表(半空或者全空)
slabp = list_entry(entry, struct slab, list);//找到一个slab
check_slabp(cachep, slabp);
check_spinlock_acquired(cachep);
while (slabp->inuse < cachep->num &&batchcount--)
{//循环从slab中分配对象
ac->entry[ac->avail++] =slab_get_obj(cachep, slabp,node);
}
check_slabp(cachep, slabp);
/*将slab放到合适的链中:*/
list_del(&slabp->list);
if (slabp->free == BUFCTL_END)//如果已经没有空闲对象了,则放到满链表中
list_add(&slabp->list, &l3->slabs_full);
else//否则放在半满链表
list_add(&slabp->list, &l3->slabs_partial);
}
...
ac->touched = 1;
return ac->entry[--ac->avail];
}
//按次序从SLAB中起初对象
static void *slab_get_obj(struct kmem_cache *cachep, struct slab*slabp,
int nodeid)
{
void *objp =index_to_obj(cachep, slabp, slabp->free);//找到要找的对象
kmem_bufctl_t next;
slabp->inuse++;//增加计数器
next =slab_bufctl(slabp)[slabp->free];
//获得slab_bufctl[slab->free]的值,为下一次锁定的空闲下标
slabp->free =next;//将锁定下标放到free中
return objp;
}
3.4 cache_grow
//增加新的SLAB
static int cache_grow(structkmem_cache *cachep, gfp_t flags, int nodeid, void *objp)
{
struct slab *slabp;
size_t offset;
gfp_t local_flags;
struct kmem_list3 *l3;
...
l3 = cachep->nodelists[nodeid];
...
/* 计算偏移量和下一个颜色.*/
offset = l3->colour_next;//计算下一个颜色
l3->colour_next++;//如果到了最大值则回0
if (l3->colour_next >= cachep->colour)
l3->colour_next = 0;
offset *= cachep->colour_off;//计算此SLAB的偏移
//从伙伴系统获得物理页
objp = kmem_getpages(cachep, local_flags, nodeid);
...
/* 如果slab头放在外部,则调用此函数分配函数*/
slabp = alloc_slabmgmt(cachep, objp, offset,
local_flags & ~GFP_CONSTRAINT_MASK, nodeid);
slabp->nodeid = nodeid;//在kmem_cache中数组的下标
//依次对每个物理页的lru.next=cache,lru.prev=slab
slab_map_pages(cachep, slabp, objp);
//调用各个对象的构造器函数,初始化新SLAB中的对象
cache_init_objs(cachep, slabp);
/* 将新的SLAB加入到全空链表中*/
list_add_tail(&slabp->list, &(l3->slabs_free));
STATS_INC_GROWN(cachep);
l3->free_objects += cachep->num;//更新空闲对象的数目
...
return 0;
}
3.5 释放对象kmem_cache_free
//真正的处理函数
static inline void __cache_free(struct kmem_cache *cachep, void*objp)
{
struct array_cache *ac = cpu_cache_get(cachep);
...
if (likely(ac->avail < ac->limit)){//如果CPU高速缓存还有位子,则直接释放
ac->entry[ac->avail++] = objp;
return;
} else {//否则需要将部分对象FLUSH到SLAB中了
STATS_INC_FREEMISS(cachep);
cache_flusharray(cachep, ac);
ac->entry[ac->avail++] = objp;
}
}
//将部分CPU高速缓存FLUSH到SLAB中
static void cache_flusharray(struct kmem_cache *cachep, structarray_cache *ac)
{
int batchcount;
struct kmem_list3 *l3;
int node = numa_node_id();
batchcount = ac->batchcount;//指定数量
l3 = cachep->nodelists[node];
if (l3->shared) {//如果共享CPU缓存存在,则将共享缓存填满,然后返回
struct array_cache *shared_array = l3->shared;
int max = shared_array->limit - shared_array->avail;
if (max) {//
if (batchcount > max)
batchcount = max;
//这里只是拷贝,并没有移除
memcpy(&(shared_array->entry[shared_array->avail]),
ac->entry, sizeof(void *) * batchcount);
shared_array->avail += batchcount;
goto free_done;
}
}
//否则需要释放到SLAB中了
free_block(cachep,ac->entry, batchcount, node);
free_done:
//对CPU高速缓存进行移除操作
spin_unlock(&l3->list_lock);
ac->avail -= batchcount;
memmove(ac->entry, &(ac->entry[batchcount]),sizeof(void *)*ac->avail);
}
//将nr_objects个对象释放到SLAB中,objpp指CPU缓存数组
static void free_block(struct kmem_cache *cachep, void **objpp,int nr_objects, int node)
{
int i;
struct kmem_list3 *l3;
for (i = 0; i < nr_objects; i++) {//对每一个对象处理,先从头部处理,LIFO
void *objp = objpp[i];
struct slab *slabp;
slabp = virt_to_slab(objp);//获得SLAB描述符
l3 = cachep->nodelists[node];
list_del(&slabp->list);//将SLAB从原来的链表中删除
check_spinlock_acquired_node(cachep, node);
check_slabp(cachep, slabp);
slab_put_obj(cachep, slabp, objp,node);//将objp放到slab中,和slab_get_obj相反
STATS_DEC_ACTIVE(cachep);
l3->free_objects++;//增加高速缓存的可用对象数目
check_slabp(cachep, slabp);
/*将SLAB重新插入链表*/
if (slabp->inuse == 0) {//如果SLAB是全空的
if (l3->free_objects > l3->free_limit)
{//并且高速缓存空闲对象已经超出限制,则需要将SLAB返回给底层页框管理器
l3->free_objects -= cachep->num;
slab_destroy(cachep, slabp);
} else {//直接插入空闲链表
list_add(&slabp->list, &l3->slabs_free);
}
} else {//直接插入部分空闲链表
list_add_tail(&slabp->list, &l3->slabs_partial);
}
}
}
3.5 高速缓存的销毁kmem_cache_destroy,此函数用在模块卸载时使用,释放以前分配的空间
4. 通用缓存
即kmalloc和kfree使用的,放在malloc_size表中,从32-33554432共21个成员。成员的结构如
/* Size description struct for general caches. */
struct cache_sizes {
size_t cs_size;//对象大小
struct kmem_cache *cs_cachep;//对应的高速缓存
struct kmem_cache *cs_dmacachep;//对应的DMA访问缓存
};
//通用高速缓存在/kmalloc_sizes.h
struct cache_sizes malloc_sizes[] = {
#define CACHE(x) { .cs_size = (x) },
#include
CACHE(ULONG_MAX)
#undef CACHE
};
Kmalloc_sizes.h
#if (PAGE_SIZE == 4096)
CACHE(32)
#endif
CACHE(64)
#if L1_CACHE_BYTES < 64
CACHE(96)
#endif
CACHE(128)
#if L1_CACHE_BYTES < 128
CACHE(192)
#endif
CACHE(256)
CACHE(512)
CACHE(1024)
CACHE(2048)
CACHE(4096)
CACHE(8192)
CACHE(16384)
CACHE(32768)
CACHE(65536)
CACHE(131072)
#if KMALLOC_MAX_SIZE >= 262144
CACHE(262144)
#endif
#if KMALLOC_MAX_SIZE >= 524288
CACHE(524288)
#endif
#if KMALLOC_MAX_SIZE >= 1048576
CACHE(1048576)
#endif
#if KMALLOC_MAX_SIZE >= 2097152
CACHE(2097152)
#endif
#if KMALLOC_MAX_SIZE >= 4194304
CACHE(4194304)
#endif
#if KMALLOC_MAX_SIZE >= 8388608
CACHE(8388608)
#endif
#if KMALLOC_MAX_SIZE >= 16777216
CACHE(16777216)
#endif
#if KMALLOC_MAX_SIZE >= 33554432
CACHE(33554432)
#endif
4.1 kalloc函数
//分配函数
static inline void *kmalloc(size_t size, gfp_t flags)
{
if (__builtin_constant_p(size))
{//是否用常数指定所需的内存长度
int i = 0;
//找到合适大小的i值
...
//按类型进行分配
#ifdef CONFIG_ZONE_DMA
if (flags & GFP_DMA)
return kmem_cache_alloc(malloc_sizes[i].cs_dmacachep,
flags);
#endif
return kmem_cache_alloc(malloc_sizes[i].cs_cachep, flags);
}//不使用常数指定
return __kmalloc(size, flags);
}
//大小不用指定的分配
static __always_inline void *__do_kmalloc(size_t size, gfp_tflags, void *caller)
{
struct kmem_cache *cachep;
cachep = __find_general_cachep(size, flags);//找一个合适大小的高速缓存
if (unlikely(ZERO_OR_NULL_PTR(cachep)))
return cachep;
return __cache_alloc(cachep, flags, caller);//分配函数
}
4.2 释放函数kfree
//kmalloc对应的释放函数
void kfree(const void *objp)
{
struct kmem_cache *c;
unsigned long flags;
...
c =virt_to_cache(objp);//获得高速缓存
debug_check_no_locks_freed(objp, obj_size(c));
__cache_free(c, (void*)objp);//调用此函数完成实质性的分配
local_irq_restore(flags);
}