- 1 软件调研
- 1.1 体验报告
- 第一印象
- 功能体验
- 1.2 BUG反馈
- 功能性BUG:错误识别、重框、对格式的低鲁棒性
- 细节改进
- 1.3 量化评分
- 1.1 体验报告
- 2 分析
- 2.1 工程量预估
- 2.2 优缺点分析
- 2.3 团队的提高方面
- 3 建议与规划
- 3.1 市场分析
- 3.2 核心用户群分析
- 3.3 功能创新设计:基于判断游戏的模型在线学习
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2020春季计算机学院软件工程(罗杰 任建) |
| 这个作业的要求在哪里 | 个人博客作业-软件案例分析 |
| 我在这个课程的目标是 | 系统性地学习软件工程理论,并开展实践 |
| 这个作业在哪个具体方面帮助我实现目标 | 通过分析一个软件,了解如何科学地度量软件。 |
| 教学班级 | 006 |
1 软件调研
在课程提供的4个供分析的产品中,我选择使用智能表单信息抽取识别作为调研的对象。由于前两周中大部分时间都被结对项目占据了,因此只是借用了邹欣老师所提供的账号对平台进行了短期的体验。对于第一次使用OCR产品,当前的APP还是给我眼前一亮,但是在使用过程中,在细节上还是发现了不少的问题。下面我将从体验报告和BUG反馈两方面来对该软件进行评价。
1.1 体验报告
我要调研的软件是一个基于OCR技术的智能表单抽取识别软件,软件支持使用少量的样本(推荐5个),样本格式可以是PDF、JPG、PNG等格式,通过在这些少量样本上人工标注所需要的标签Label,即可对预训练得到的模型进行微调,当面临新的样本时能够自动化地提取用户所需要的内容并支持以Json文件的格式导出。
下图是使用软件过程中的照片:
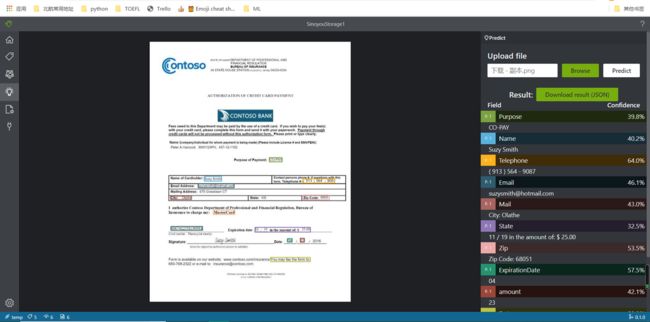
第一印象
由于网络连接因素是客观原因,我在此不做具体讨论。
产品的使用说明存在于Github上,并细心地配有中文的使用说明,在粗略阅读并进入APP网站的第一眼,觉得产品非常得简洁,在没有建立好项目前,仅有主页和连接两个窗口可供使用,作为一位刚接触OCR软件的小白,这种界面设置不会令人望而生畏,而作为有一些计算机编程思维的人,能够看得出是将开发时运行计算部分与存储部分实现了解耦。
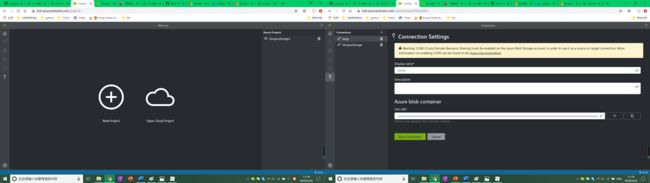
最初,我计划自行注册Azure账号,Form Recognizer注册比较顺利,但是在配置连接微软AZure的云存储服务时操作以字符复制接口和密钥的形式为主,并且由于先前没有得到老师提供的云存储账号,我在自行配置存储账号时遭遇了很大的困难,对于我认为是正确的配置输入,程序总是提示对Bolb连接的失败(我也尝试了学习CORS规则进行配置,但是并没有成功),因此目前挂在云存储所需要的精力是非常高的:
- 简化:简化使用连接挂在云存储的过程,例如使用授权方式。
- 软件有了依赖,第一印象就不仅仅取决于软件本身了:程序必须依赖
AZure存储,因此用户体验中必然包含对Azure这种相较而言复杂得多的平台,如果这些依赖链中某一环节出现问题,必然对整体印象影响很大。在现有基础上,应该尽可能简化用户在AZure平台上的操作复杂度(例如高级设置CORS、调整权限等)。
根据教材中在设计用户体验的5W1H要素方法,我在使用时也对软件进行了一些换位思考:
WHO & HOW:作为接触此类软件的小白,再加之细致地阅读过指导书,初次见面还是比较熟悉。但是,此类APP面向用户更多是有工作需求的用户(能够拥有五份以上的同样类型的表单也不是任何人随时都有的),因此不妨考虑一下,在用户进入网页后,只能看到新建项目和连接的选项,还需经过复杂的标记,而到最后一步Predict前都无法看到OUTPUT的感受。因此,建议能够增加一个能够无需用户配置连接甚至项目的DEMO,并且预置好人工标记的标签,从而将整个体验时长大幅降低至1-2分钟,这样后面的亮点才能显现出来。
WHAT & WHY:从功能角度上(忽略无法知晓的商业因素),相比于所提供的另一款轻量级OCR识别,本款APP的优势就凸显出来了:
- 首先是能够使用自定义的样本微调,提取自己所需要的信息,并在预测时提供置信度,在产品的通用性和定制性之间把握到位,能够把握到绝大部分OCR软件定制化需求的共性。
- 其次,微调所需的样本量很小,操作复杂度是用户以“体验”为目的的接受程度范围之内的。
- 最后是预测的内容可以以
Json通用格式进行导出,有益于后续的自定义处理,接口预留到位。
功能体验
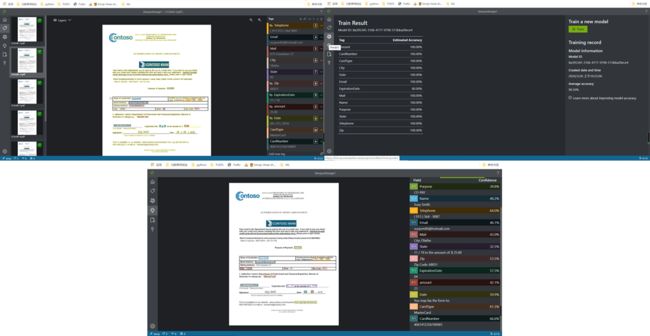
在成功建立项目进入操作后,和之前的同学评价一样,从可视化、操作简便性、识别准确性上来说给我的体验都是很不错的,下图展示了标记、训练和预测的三个窗口,其中给我惊喜的有一下几个方面:
- 快捷键:在标记页面提供了与标签映射的键盘快捷键,使得标记的鼠标操作可以完全专注于文档本身。(不过提醒一下,应该简单调查一下,这些数字和字母的顺序是否在绝大部分目标用户的键盘上都是一致的。)
- 高准确性和类型选择:对英文文本的准确性识别是很高的,并且对于邮件、签名、日期这些形式有特点的数据适应性很好,拿捏适度;此外,模型还提供了常见的数据类型供用户定义,可以进一步地提高模型预测的准确性。
当然,再好的产品也不可能是完美的,在一些细节上的问题我将放在BUG反馈章节进行。
1.2 BUG反馈
功能性BUG:错误识别、重框、对格式的低鲁棒性
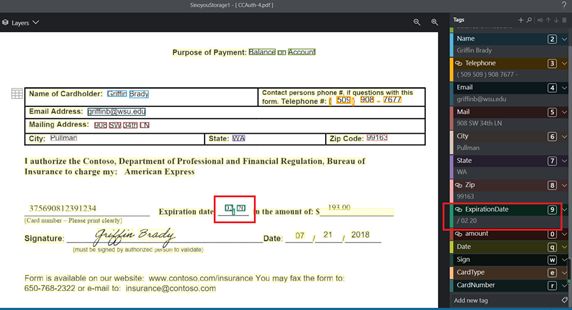
错误识别与重框问题:
-
描述:在对文档进行OCR元素识别时,在文档中的
Data日期栏中出现了很多错误。- 将$__________的下划线识别为一个元素。
- 对同样的一个日期元素重复识别,形成了重叠框。
- 在处理日期中的数字和/(斜线)时,出现了顺序颠倒的情况。
-
图片效果展示
-
下划线错误识别与重叠框

-
-
顺序颠倒
-
上述这些问题看起来是比较小的,但是设身处地地想一想场景:区分日期的/斜杠在识别时非常得小,用户在手工标注的时候可能会忽略这些斜杠,直接点数字,如果这些数字在预测时被重复预测或者漏测,那么整个日期预测就是残缺或者错位的,信息准确性就对不上了,在这里提供一些建议:
- 使用Intersect Over Union的技术对高度重合的框进行去重。
- 在用户手工标注时,提供拖动框进行批量选择。
图像预处理与分辨率造成的低鲁棒性:
-
描述:由于测试样例中仅提供5份同样格式的内容,因此在测试时选择第二份文档右键保存图片到本地,而后上传测试,虽然文档属于训练样本,但预测结果很不如人意。起初以为是因为加入了手写签名的标签导致错误,但后期发现是因为上传的图片样本没有与测试样本保持严格的一致格式:右键保存图片时取决于缩放窗口状态,图片清晰程度可能与原图不一致、图片可能出现透明的边框,我尝试了“分辨率差异”和“分辨率差异“+”透明边框“两种模式,结果都不佳。测试样本1,测试样本2
-
图片展示:红线所引出的都是表示分类错误的,而红框则表示没有识别到的。
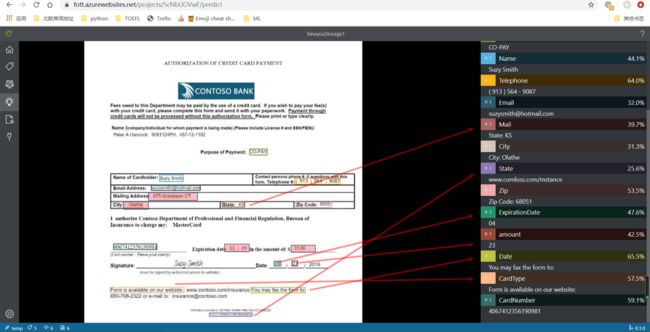
-
建议:
- 提升对不同分辨率的支持:这种在实际工作中很有可能遇到。
- 加强预处理:就像“文档扫描王”类似的软件一样,先利用边缘特征将文档本体提取出来。
不可复现的错误提示:
在使用时,共出现三次同样的错误框提示Can not read property 'getResolutionForZoon' of null,产生的情景在当在标记/测试页面,当文档处在一个放大(或缩小)状态时,在界面上进行其他操作所产生的。但是,由于该问题无法直接复现,也不排除是否因为网络原因,在此只做展示。
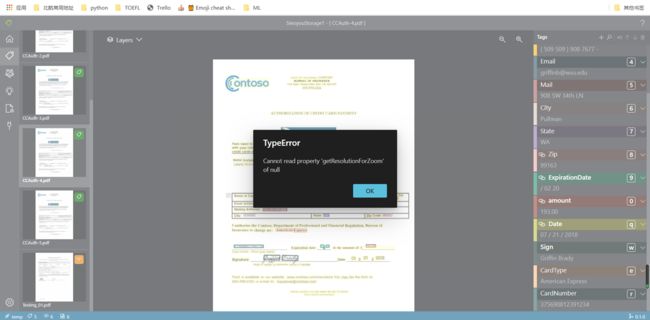
细节改进
- 用户设定的标签颜色,建议与默认的黄色区分开。
- 对于如何删除某个标签定义的快捷键,说明书中没有提到。
- 没有找到说明书中所说的,如何利用
ModelID对模型进行Reset。
1.3 量化评分
| 评分标准 | 评价 |
|---|---|
| 尽快提供可感触的反馈 | 优秀 |
| 系统界面符合用户的现实惯例 | 优秀 |
| 用户拥有控制权 | 优秀 |
| 一致性和标准化 | 优秀 |
| 适合各种类型的用户 | 良好 |
| 帮助用户识别、诊断和修复错误 | 一般 |
| 有必要的提示与帮助文档 | 优秀 |
因此我最后给出4-4.5分的评价——很好,推荐。
2 分析
2.1 工程量预估
使用此服务的所有功能,估计这个软件/网站/服务做到这个程度大约需要多少时间(团队人数6人左右,计算机大学毕业生,并有专业UI支持)。
假设:在有专业UI支持的情况下,重点在于设计后端的功能和前后端的配合调试
- 头脑风暴,调研定位用户需求,形成产品文档:1周。
- 设计文档编写与测试思路部署:1周。
- 检测模型:
psenet,crnn_lstm_lite等检测模型的功能调研与比对,在缩小范围后完成模型的训练与部署,2-3周。 - 自适应功能的开发:1-2周。
- 与前端协调与功能测试:1周。
因此我估计在1.5-2个月能够完成。
2.2 优缺点分析
分析这个软件目前的优劣(和类似软件相比),这个产品的质量在同类产品中估计名列第几?
优势:
- 控制性:定制化的识别效果。
- 可视化:简洁的操作过程和方法,界面友好,快捷键操作简便。
- 准确性:在英文文本上识别效果出色,给出模型的置信度。
劣势:
- 设计必须的个性化因素,用户需要花费更多时间看到效果。
- 不支持用户可以选择的不同种类内核模型。
- 云端数据的加载模式比较复杂。
- 对输入内容的格式要求苛刻,实际应用中需要自行加入预处理的内容。
综合上述情况,我认为微软的模型在实际中有较大的提升空间,但是其自定义的功能和交互体验已经是非常新颖的功能了,具有市场潜力,在同类产品中应该排名前列。
2.3 团队的提高方面
从各方面的问题,推理出这个软件团队在软件工程方面可以提高的一个重要方面。
该产品作为Form Recognizer中的一环也是第一个展示的环节,团队需要重点关注为接下来的产品链奠定良好的基础和参考标准,由此延伸出了两个方面:
- 首先是核心计算模块的性能和表现:让我简单上手体验时,时间与样本的限制让我更多关注其外部的可视化与交互特征。但是,作为一个投入实际运用的部署软件,其检测能力高低才是最需要关注的。使用者的心理是贪婪的,当用久了,再好的界面与交互都会适应,练好内功才能越用越好用。
- 其次是工程框架:总结好在开发
Form Recognizer的第一个功能时从内到外的框架,这样才能对外使用户拥有一致的流畅体验,对内能够完成高效的设计开发。
3 建议与规划
这个软件/网站/服务有很多可以提高的部分,如果你是新上任的项目经理,如何提高从而在竞争中胜出?
- 首先,市场有多大?潜在的用户有多少?
- 目前市场上有什么样的产品了,它们的优势劣势在哪里?和它直接竞争的产品在那里?
- 作为新的项目经理,这个产品的核心用户群是什么样的人,典型用户长什么样?学历,年龄,专业,爱好,收入,表面需求,潜在需求都是什么?
- 功能:你要设计什么样的功能?为何要做这个功能,而不是其他功能?为什么用户会用你的产品/功能?你的创新在哪里?可以用NABCD分析.
- 如果你有钱可以招聘6个人,有4个月的时间,你作为项目经理,应该如何配置角色(开发,测试,美工等等)?描述你的团队在16周期间每周都要做什么,才能在第16周如期发布软件的改进版本,并取得预想中的成绩。
把上面几个部分都写清楚,并选择的回答其中三分之二的问题,发布一个个人博客。
3.1 市场分析
OCR识别的市场需求较大,从政府企业所需要的发票、快递面单、申请单填写、个人健康申报表、证件识别等;到个人终端的手写笔记自动转换、外文拍译功能,都围绕OCR技术。
“表单抽取识别”更多是面向前者的,如果技术成熟,面单的技术面向所有需要纸质凭据的行业(规模量相当大);此外,在偶尔一些情况下,例如问卷收集、投票等,也会短暂地使用这种软件。
3.2 核心用户群分析
商业软件不同于个人软件,功能是需要专业人士去研究和摸索的,我认为,使用表单抽取软件的用户具有:
- 高中以上的学历:计算机技术熟练,较强的软件操作能力。
- 年龄:20-35岁。
- 专业:财务、法律、警务、政务、行政。
- 收入:普通。
- 表面需求:具有高准确性的OCR识别,并且具备将PDF、图像等形式的表单转换为可编辑的结构化文本。(如Word表格)。
- 潜在需求:向所服务的对象提供一套完全自动化的申请/报销/识别的服务体系,并且能够统一地维护管理各类数据。
3.3 功能创新设计:基于判断游戏的模型在线学习
描述:在软件中提供一种机器学习的在线学习机制,能够使最初在仅用5份文本的模型随着样本数量的增多而识别愈加得好。具体操作时,定期将置信度高、中、低的按量投放在一个栏目中,以“XXX的类型是???吗”或者“XXX的格式正确吗?“,来让使用者做判断题;甚至可以加入挑战闯关机制/人机对战的游戏,“免费众包”——让业余人士从判断题中得到乐趣。人工结果用以改善模型的预测效果。
创新来源:
- 最初网站上用户输入的验证码是用来将纸质报纸文字转换为电子文字而设计的,其完美地综合了外界需求和内部需求。
- IOS系统中默认的相册软件,具有人物识别的功能,在点开某个人物的图像分类时,会出现"还有更多照片以供检查"的选项。
为什么做这个功能的原因:
- 提升产品实用价值:仅靠5份样本来实现准确化的定制性任务是不太现实的,我先前对OCR产品的直接体会就是“要不高度完全智能,要不就不用”,因为如果错误率不能足够低,反而要花更多的精力去检查纠错。
- 人更喜欢做判断题:虽然标注操作已经尽量简单,但终究还是一篇篇“精雕细琢”,用户也很难坚持下来。与其标注更多文档对着计算机灌水,不如让模型自己提问题。
NABCD分析:
- Need:需要尽量准确的表单识别抽取,减少人工核查的工作量和心情烦躁程度。
- Approach:让机器根据自身学习情况(置信度),有针对性地出判断题。
- Benefit:对模型预测能力持续性地提升;进入人力小消耗 -> 精准度更高 -> 人力更小消耗的正反馈过程。
- Competitors:目前没有在竞争对手里找到这种做法的,将标记任务开发成小游戏就更没有了。
- Delivery:寻找“刚需”且需求量适中的企业用户,同步开发在线小游戏,提升模型能力+娱乐大众两不误。