MySQL 原理篇
MySQL 索引机制
MySQL 体系结构及存储引擎
MySQL 语句执行过程详解
MySQL 执行计划详解
MySQL InnoDB 缓冲池
MySQL InnoDB 事务
MySQL InnoDB 锁
MySQL InnoDB MVCC
MySQL InnoDB 实现高并发原理
MySQL InnoDB 快照读在RR和RC下有何差异
我们经常使用 MySQL 的执行计划来查看 SQL 语句的执行效率,接下来分析执行计划的各个显示内容。
EXPLAIN SELECT * FROM users WHERE id IN (SELECT userID FROMuser_address WHERE address = "湖南长沙麓谷") ;
![]()
执行计划的 id
select 查询的序列号,标识执行的顺序
- id 相同,执行顺序由上至下
- id 不同,如果是子查询,id 的序号会递增,id 值越大优先级越高,越先被执行
执行计划的 select_type
查询的类型,主要是用于区分普通查询、联合查询、子查询等。
- SIMPLE:简单的 select 查询,查询中不包含子查询或者 union
- PRIMARY:查询中包含子部分,最外层查询则被标记为 primary
- SUBQUERY/MATERIALIZED:SUBQUERY 表示在 select 或 where 列表中包含了子查询,MATERIALIZED:表示 where 后面 in 条件的子查询
- UNION:表示 union 中的第二个或后面的 select 语句
- UNION RESULT:union 的结果
对于 UNION 和 UNION RESULT 可以通过下面的例子展现:
EXPLAIN SELECT * FROM users WHERE id IN(1, 2) UNION SELECT * FROM users WHERE id IN(3, 4);

执行计划的 table
查询涉及到的表。
- 直接显示表名或者表的别名
由 ID 为 N 查询产生的结果
执行计划的 type
访问类型,SQL 查询优化中一个很重要的指标,结果值从好到坏依次是:system > const > eq_ref > ref > range > index > ALL。
- system:系统表,少量数据,往往不需要进行磁盘IO
- const:常量连接
- eq_ref:主键索引(primary key)或者非空唯一索引(unique not null)等值扫描
- ref:非主键非唯一索引等值扫描
- range:范围扫描
- index:索引树扫描
- ALL:全表扫描(full table scan)
下面通过举例说明。
system
explain select * from mysql.time_zone;

上例中,从系统库 MySQL 的系统表 time_zone 里查询数据,访问类型为 system,这些数据已经加载到内存里,不需要进行磁盘 IO,这类扫描是速度最快的。
explain select * from (select * from user where id=1) tmp;

再举一个例子,内层嵌套(const)返回了一个临时表,外层嵌套从临时表查询,其扫描类型也是 system,也不需要走磁盘 IO,速度超快。
const
数据准备:
CREATE TABLE `user` ( `id` int(11) NOT NULL, `NAME` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into user values(1,'shenjian'); insert into user values(2,'zhangsan'); insert into user values(3,'lisi');
explain select * from user where id=1;

const 扫描的条件为:
- 命中主键(primary key)或者唯一(unique)索引
- 被连接的部分是一个常量(const)值
如上例,id 是 主键索引,连接部分是常量1。
eq_ref
数据准备:
CREATE TABLE `user` ( `id` int(11) NOT NULL, `NAME` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into user values(1,'shenjian'); insert into user values(2,'zhangsan'); insert into user values(3,'lisi'); CREATE TABLE `user_ex` ( `id` int(11) NOT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into user_ex values(1,18); insert into user_ex values(2,20); insert into user_ex values(3,30); insert into user_ex values(4,40); insert into user_ex values(5,50);
EXPLAIN SELECT * FROM USER,user_ex WHERE user.id=user_ex.id;

eq_ref 扫描的条件为,对于前表的每一行(row),后表只有一行被扫描。
再细化一点:
- join 查询
- 命中主键(primary key)或者非空唯一(unique not null)索引
- 等值连接;
如上例,id 是主键,该 join 查询为 eq_ref 扫描。
ref
数据准备:
CREATE TABLE `user` ( `id` int(11) DEFAULT NULL, `name` varchar(20) DEFAULT NULL, KEY `id` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into user values(1,'shenjian'); insert into user values(2,'zhangsan'); insert into user values(3,'lisi'); CREATE TABLE `user_ex` ( `id` int(11) DEFAULT NULL, `age` int(11) DEFAULT NULL, KEY `id` (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into user_ex values(1,18); insert into user_ex values(2,20); insert into user_ex values(3,30); insert into user_ex values(4,40); insert into user_ex values(5,50);
EXPLAIN SELECT * FROM USER,user_ex WHERE user.id=user_ex.id;

如果把上例 eq_ref 案例中的主键索引,改为普通非唯一(non unique)索引。就由 eq_ref 降级为了 ref,此时对于前表的每一行(row),后表可能有多于一行的数据被扫描。
select * from user where id=1;

当 id 改为普通非唯一索引后,常量的连接查询,也由 const 降级为了 ref,因为也可能有多于一行的数据被扫描。
ref 扫描,可能出现在 join 里,也可能出现在单表普通索引里,每一次匹配可能有多行数据返回,虽然它比 eq_ref 要慢,但它仍然是一个很快的 join 类型。
range
数据准备:
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(20) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into user values(1,'shenjian'); insert into user values(2,'zhangsan'); insert into user values(3,'lisi'); insert into user values(4,'wangwu'); insert into user values(5,'zhaoliu');
explain select * from user where id between 1 and 4; explain select * from user where id in(1,2,3); explain select * from user where id > 3;
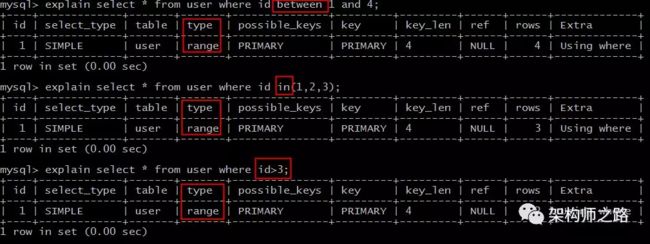
range 扫描就比较好理解了,它是索引上的范围查询,它会在索引上扫码特定范围内的值。
像上例中的 between,in,> 都是典型的范围(range)查询。
index
explain count (*) from user;

如上例,id 是主键,该 count 查询需要通过扫描索引上的全部数据来计数,它仅比全表扫描快一点。
ALL
数据准备:
CREATE TABLE `user` ( `id` int(11) DEFAULT NULL, `name` varchar(20) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into user values(1,'shenjian'); insert into user values(2,'zhangsan'); insert into user values(3,'lisi'); CREATE TABLE `user_ex` ( `id` int(11) DEFAULT NULL, `age` int(11) DEFAULT NULL ) ENGINE=InnoDB DEFAULT CHARSET=utf8; insert into user_ex values(1,18); insert into user_ex values(2,20); insert into user_ex values(3,30); insert into user_ex values(4,40); insert into user_ex values(5,50);
explain select * from user,user_ex where user.id=user_ex.id;

如果 id 上不建索引,对于前表的每一行(row),后表都要被全表扫描。
文章中,这个相同的 join 语句出现了三次:
- 扫描类型为 eq_ref,此时 id 为主键
- 扫描类型为 ref,此时 id 为非唯一普通索引
- 扫描类型为 ALL,全表扫描,此时id上无索引
有此可见,建立正确的索引,对数据库性能的提升是多么重要。
总结
- explain 结果中的 type 字段,表示(广义)连接类型,它描述了找到所需数据使用的扫描方式;
- 常见的扫描类型有:system>const>eq_ref>ref>range>index>ALL,其扫描速度由快到慢;
- 各类扫描类型的要点是:
- system 最快:不进行磁盘 IO
- const:PK 或者 unique 上的等值查询
- eq_ref:PK 或者 unique 上的 join 查询,等值匹配,对于前表的每一行,后表只有一行命中
- ref:非唯一索引,等值匹配,可能有多行命中
- range:索引上的范围扫描,例如:between、in、>
- index:索引上的全集扫描,例如:InnoDB 的 count
- ALL 最慢:全表扫描
- 建立正确的索引,非常重要;
- 使用 explain 了解并优化执行计划,非常重要;
执行计划 possible_keys
查询过程中有可能用到的索引。
执行计划 key
实际使用的索引,如果为 NULL ,则没有使用索引。
执行计划 rows
根据表统计信息或者索引选用情况,大致估算出找到所需的记录所需要读取的行数。
执行计划 filtered
表示返回结果的行数占需读取行数的百分比, filtered 的值越大越好。
执行计划 Extra
十分重要的额外信息。
- Using filesort:MySQL 对数据使用一个外部的文件内容进行了排序,而不是按照表内的索引进行排序读取。
- Using temporary:使用临时表保存中间结果,也就是说 MySQL 在对查询结果排序时使用了临时表,常见于order by 或 group by。
- Using index:表示 SQL 操作中使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高。
- Using index condition:表示 SQL 操作命中了索引,但不是所有的列数据都在索引树上,还需要访问实际的行记录。
- Using where:表示 SQL 操作使用了 where 过滤条件。
- Select tables optimized away:基于索引优化 MIN/MAX 操作或者 MyISAM 存储引擎优化 COUNT(*) 操作,不必等到执行阶段再进行计算,查询执行计划生成的阶段即可完成优化。
- Using join buffer (Block Nested Loop):表示 SQL 操作使用了关联查询或者子查询,且需要进行嵌套循环计算。
下面通过举例说明。
数据准备:
CREATE TABLE `user` ( `id` int(11) NOT NULL, `name` varchar(20) DEFAULT NULL, `sex` varchar(5) DEFAULT NULL, PRIMARY KEY (`id`), KEY `name` (`name`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; insert into user values(1, 'shenjian','no'); insert into user values(2, 'zhangsan','no'); insert into user values(3, 'lisi', 'yes'); insert into user values(4, 'lisi', 'no');
数据说明:
用户表:id 主键索引,name 普通索引(非唯一),sex 无索引。
四行记录:其中 name 普通索引存在重复记录 lisi。
Using filesort
explain select * from user order by sex;
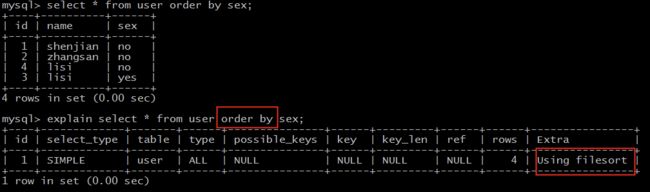
Extra 为 Using filesort 说明,得到所需结果集,需要对所有记录进行文件排序。
这类 SQL 语句性能极差,需要进行优化。
典型的,在一个没有建立索引的列上进行了 order by,就会触发 filesort,常见的优化方案是,在 order by 的列上添加索引,避免每次查询都全量排序。
Using temporary
explain select * from user group by name order by sex;
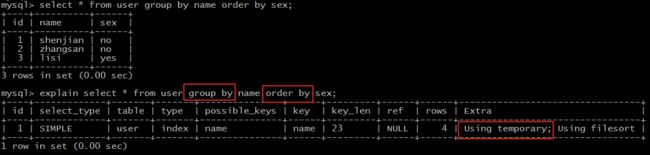
Extra 为 Using temporary 说明,需要建立临时表(temporary table)来暂存中间结果。
这类 SQL 语句性能较低,往往也需要进行优化。
典型的 group by 和 order by 同时存在,且作用于不同的字段时,就会建立临时表,以便计算出最终的结果集。
临时表存在两种引擎,一种是 Memory 引擎,一种是 MyISAM 引擎,如果返回的数据在 16M 以内(默认),且没有大字段的情况下,使用 Memory 引擎,否则使用 MyISAM 引擎。
Using index
EXPLAIN SELECT id FROM USER;
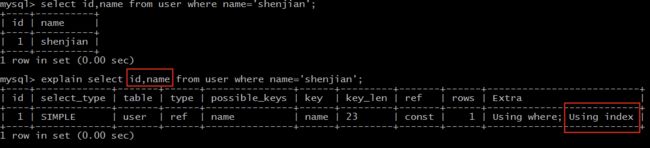
Extra 为 Using index 说明,SQL 所需要返回的所有列数据均在一棵索引树上,而无需访问实际的行记录。
这类 SQL 语句往往性能较好。
Using index condition
explain select id, name, sex from user where name='shenjian';
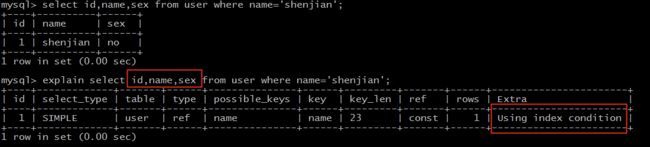
Extra 为 Using index condition 说明,确实命中了索引,但不是所有的列数据都在索引树上,还需要访问实际的行记录。
这类 SQL 语句性能也较高,但不如 Using index。
Using where
explain select * from user where sex='no';

Extra 为 Using where 说明,查询的结果集使用了 where 过滤条件,比如上面的 SQL 使用了 sex = 'no' 的过滤条件
Select tables optimized away
EXPLAIN SELECT MAX(id) FROM USER;
![]()
比如上面的语句查询 id 的最大值,因为 id 是主键索引,根据 B+Tree 的结构,天然就是有序存放的,所以不需要等到执行阶段再进行计算,查询执行计划生成的阶段即可完成优化。
Using join buffer (Block Nested Loop)
explain select * from user where id in (select id from user where sex='no');
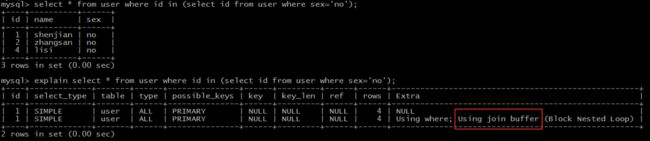
Extra 为 Using join buffer (Block Nested Loop) 说明,需要进行嵌套循环计算。内层和外层的 type 均为 ALL,rows 均为4,需要循环进行4*4次计算。
这类 SQL 语句性能往往也较低,需要进行优化。
典型的两个关联表 join,关联字段均未建立索引,就会出现这种情况。常见的优化方案是,在关联字段上添加索引,避免每次嵌套循环计算。
参考
《同一个SQL语句,为啥性能差异咋就这么大呢?(1分钟系列)》
《如何利用工具,迅猛定位低效SQL? | 1分钟系列》