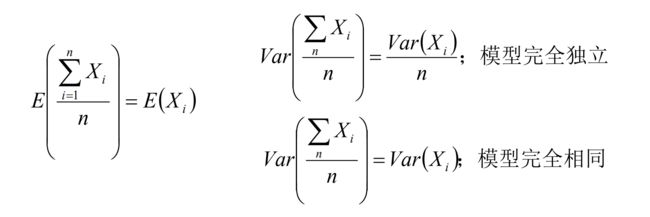05 集成学习 - Boosting - GBDT初探
十四、GBDT的构成
● GBDT由三部分构成:DT(Regression Decistion Tree-回归决策树)、GB(Gradient Boosting-梯度提升)、Shrinkage(衰减)
1、先构建回归决策树,然后用到提升的思想:ft(x) = ∑ ht(x);
2、梯度提升: 下一个模在拟合上一个模型的残差,其实就等价于在拟合上一个模型的梯度。
3、衰减: ft(x) = step × ∑ ht(x); 衰减指公式里的step值,上一章最后有详述。
● 由多棵决策树组成,所有树的结果累加起来就是最终结果。(上一章的例子中可以直观感受到这一点。)
● 迭代决策树和随机森林的区别:
1、随机森林使用抽取不同的样本,构建不同的子树。也就是说第m棵树的构建和前m-1棵树的结果是没有关系的。(所以人家可以同时构建所有的树)
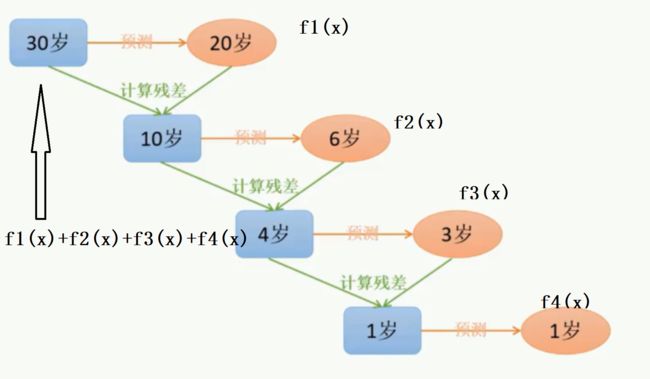
2、迭代决策树在构建子树的时候,使用之前子树构建结果后,形成的残差作为输入数据,再构建下一个子树;然后最终预测的时候按照子树构建的顺序进行预测,并将预测结果相加。(而你要看前面人的脸色行事)

十五、GBDT算法原理
1、 给定输入向量X和输出变量Y组成的若干训练样本(X1,Y1),(X2,Y2)...(Xn,Yn),目标是找到近似函数F(X),使得损失函数L(Y,F(X))的损失值最小。
其实机器学习这个领域,本质上都想达到这个目标。正如我在第一章里说的,我们尽可能想要找到一个模型,符合造物主公式。无论哪种机器学习的模型,我们都在追求损失函数最小。
2、 L损失函数一般采用最小二乘损失函数或者绝对值损失函数。
F(X)是常数。(参考第7步)
● 看左边最小二乘的公式,关于F(X)求偏导,得到F(X)-y 。F(X)是真实值y的均值的时候,该损失函数最小。
● 看右边的绝对值损失函数,当F(X)是中位数的时候损失最小。
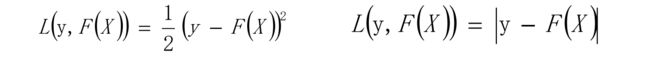
3、 最优解为:
比较最小二乘损失函数和绝对值损失函数,哪个更小就选哪个。
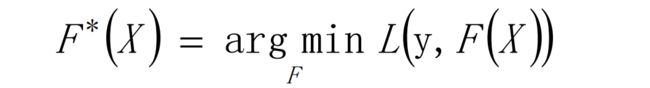
4、 假定F(X)是一组最优基函数 fi(X) 的加权和(即衰减的思想)

原本14,16,24,26,一下子变成-1,1,-1,1,变化幅度太大了,所以加上缩放系数。
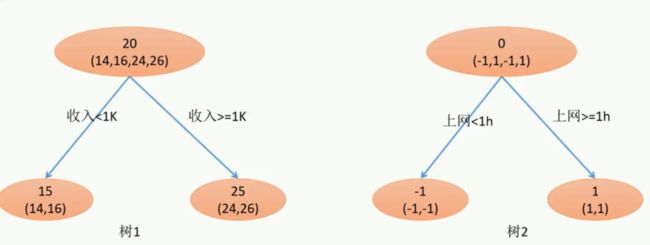
5、用贪心算法的思想扩展得到 Fm(X),求解最优 f 。
贪心算法(相邻两步的解最优):在当前的情况下,求解下一步的最优解。当算法包含若干步的时候,贪心算法只能保证下一步的算法是最优解,而不能保证在整个求解的过程中获得全局最优解。
使用贪心算法考虑GBDT问题:每求一步基模型,都是当前步骤的最优情况。如下图所示:第m步的强模型= 第m-1的强模型 + 使得损失函数达到最小时候的对应的基模型: fm(Xi) 。
但这个基模型 fm(Xi)不能保证在未来的全局中它是最优的模型。
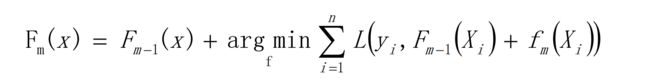
6、如果以贪心算法在每次选择最优基函数 f 时仍然困难,使用梯度下降法近似计算。
7、给定常数函数 F0(X) 第2步中提到的F(X)
即得损失函数L最小的时候,对应的yi和c,构成了常数函数 F0(X)。
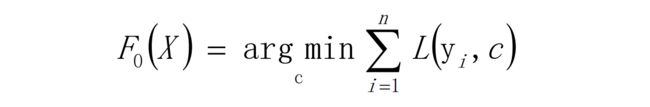
这个常数不是随便给的,比如当你选择使用最小二乘构建损失函数的时候,如果下图中的样本不是一个30岁,而是(14,16,24,26),那么我们预测的F(X)常数应该是均值,即F(X) = (14+16+24+26)/4 = 20。此时损失函数= (14-20)^2 + (16-20)^2 + (24-20)^2 + (26-20)^2 = 104。在相同标准下,如果这个损失函数值最小,那么用 F(X)=20作为常数作为这一步的基模型构建最优。此时yi和c分别为 (14,6) (16,4) (24,4) (26,6),下一步要预测的真实值(残差) = (6,4,4,6)
8、根据梯度下降计算学习率
在第7步我们得到了F(X)的值,作为这一步的输入。
这里将损失函数对F(X)进行求导,在第2步中我们可以看到,当对最小二乘进行求导后,得到 |y-F(X)| 。这是针对一个样本求导,如果是所有的样本求导并求和,得到的是 ∑|y-F(X)| ,这就是最小二乘损失函数的导函数。
这里的αim(第i个样本集的第m个模型对应的学习率) 就是下一步模型中的需要预测的真实值y,学习率αim可以近似看成是残差。(伪残差)
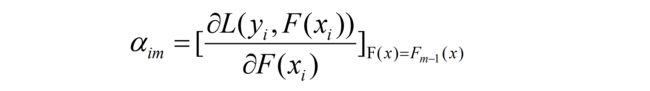
9、使用数据(xi,αim) (i=1……n )计算拟合残差找到一个CART回归树,得到第m棵树。
第m棵树是什么样的?
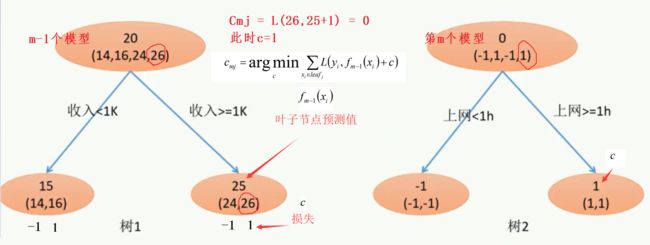
作为一个样本X,将X放入模型之后,最终会落到某个叶子节点中。这个叶子节点中对应了一个目标值。
左边 - 最优的单个叶子节点,决策树每次找到的都是一个常量。右边 - 第m棵树,公式含义:首先判断x是否属于叶子,属于返回1,不属于返回0。对于所有的leaf叶子,x最终只属于一个叶子。
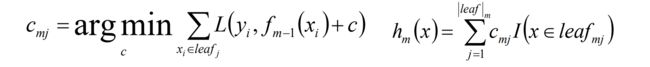
10、更新模型
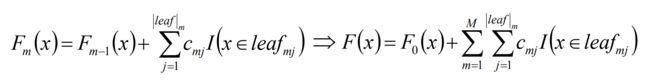
十六、GBDT回归算法和分类算法的区别
1、两者唯一的区别就是选择不同的损失函数。
2、回归算法选择的损失函数一般是均方差(最小二乘)或者绝对值误差;而在分类算法中一般的损失函数选择对数函数来表示。
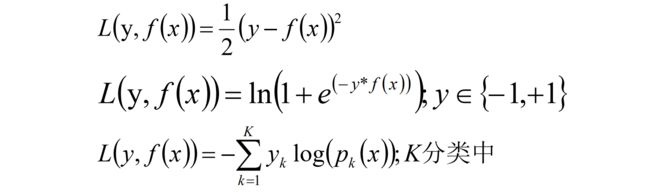
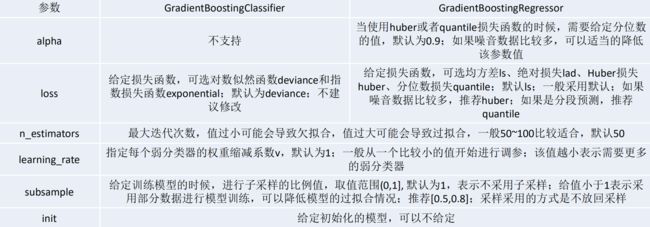
十七、GBDT scikit-learn相关参数
GBDT的代码和AdaBoosting类似,这里简单对其相关的参数进行介绍:
工作中对常用的参数如何选择会问得比较多。
比较关键的是n_estimators 和 learning_rate的设置。
当上面两个参数怎么调都调不好模型的时候,尝试使用subsample参数。
十八、GBDT总结
GBDT的优点如下:
1、可以处理连续值和离散值;
2、在相对少的调参情况下,模型的预测效果也会不错;
3、模型的鲁棒性比较强。
GBDT的缺点如下:
由于弱学习器之间存在关联关系,难以并行训练模型。
十九、Bagging、Boosting的区别
1、样本选择:Bagging算法是有放回的随机采样;Boosting算法是每一轮训练集长度不变,是训练集中的每个样例在分类器中的权重发生变化(Adaboost),而权重根据上一轮的分类结果进行调整;对于GBDT来说,目标值Y实际上发生了变化,基于梯度来确定新的目标Y。
2、样例权重:Bagging使用随机抽样,样例的权重相等;Boosting(Adaboost)根据错误率不断的调整样例的权重值,错误率越大则权重越大;
3、预测函数:Bagging所有预测模型的权重相等;Boosting(Adaboost)算法对于误差小的分类器具有更大的权重。
4、并行计算:Bagging算法可以并行生成各个基模型;Boosting理论上只能顺序生产,因为后一个模型需要前一个模型的结果;
5、Bagging是减少模型的variance(方差);Boosting是减少模型的Bias(偏度)。
6、Bagging里每个分类模型都是强分类器,因为降低的是方差,方差过高需要降低是过拟合;Boosting里每个分类模型都是弱分类器,因为降低的是偏度,偏度过高是欠拟合。
7、方差和偏差的问题:error = Bias + Variance
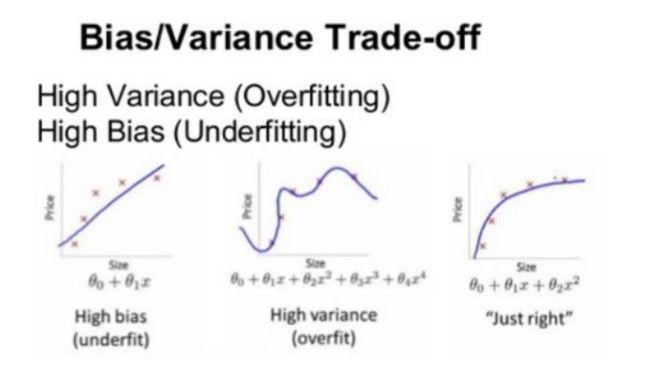
Bagging对样本重采样,对每一轮的采样数据集都训练一个模型,最后取平均。由于样本集的相似性和使用的同种模型,因此各个模型的具有相似的bias和variance;