CSDN资讯 2015-07-07 14:15
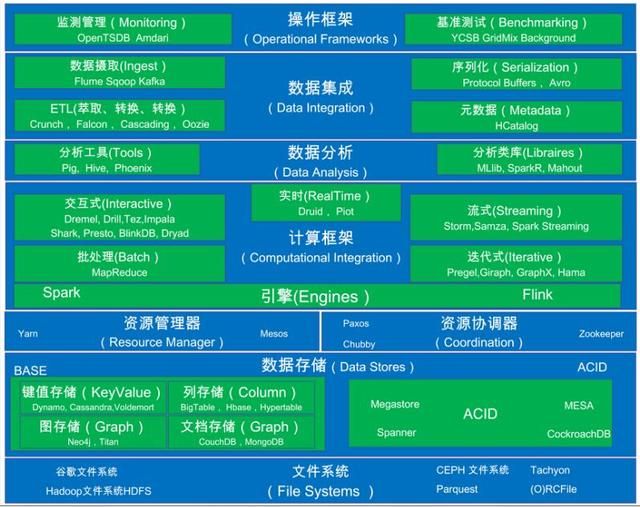
图1大数据处理的关键架构层
数据存储层
宽泛地讲据对一致性consistency要求的强弱不同分布式数据存储策略可分为ACID和BASE两大阵营。ACID是指数据库事务具有的四个特性原子性Atomicity、一致性Consistency、隔离性Isolation、持久性Durability。ACID中的一致性要求比较强事务执行的结果必须是使数据库从一个一致性状态变到另一个一致性状态。而BASE对一致性要求较弱它的三个特征分别是基本可用Basically Available, 软状态/柔性事务Soft-state即状态可以有一段时间的不同步, 最终一致性Eventual consistency。BASE还进一步细分基于键值的基于文档的和基于列和图形的 – 细分的依据取决于底层架构和所支持的数据结构注BASE完全不同于ACID模型它以牺牲强一致性获得基本可用性和柔性可靠性并要求达到最终一致性。
在数据存储层还有很多类似的系统和某些系统的变种这里我仅仅列出较为出名的几个。如漏掉某些重要系统还请谅解。
BASE
键值存储Key Value Stores
Dynamo【29】– 这是由亚马逊工程师们设计的基于键值的高可用的分布式存储系统注Dynamo放弃了数据建模的能力所有的数据对象采用最简单的Key-value模型存储可简单地将Dynamo理解为一个巨大的Map。Dynamo是牺牲了部分一致性来换取整个系统的高可用性。
Cassandra【30】– 这是由Facebook工程师设计的一个离散的分布式结构化存储系统受亚马逊的Dynamo启发Cassandra采用的是面向多维的键值或面向列的数据存储格式注Cassandra可用来管理分布在大量廉价服务器上的巨量结构化数据并同时提供没有单点故障的高可用服务。
Voldemort【31】–这又是一个受亚马逊的Dynamo启发的分布式存储作品由全球最大的职业社交网站LinkedIn的工程师们开发而成注Voldemort这个在《哈利·波特》中常被译作“伏地魔”的开源数据库支撑起了LinkedIn的多种数据分析平台。
面向列的存储Column Oriented Stores
BigTable【32】–这是一篇非常经典的学术论文阐述了面向列的分布式的数据存储方案由谷歌荣誉出品。注Bigtable是一个基于Google文件系统的分布式数据存储系统是为谷歌打拼天下的“三驾马车”之一另外两驾马车分别是分布式锁服务系统Chubby和下文将提到的MapReduce。
HBase【33】–目前还没有有关Hbase的定义性论文这里的文献提供了一个有关HBase技术的概述性文档注Hbase是一个分布式的、面向列的开源数据库。其设计理念源自谷歌的 BigTable用Java语言编写而成。文献【33】是一个有关Hbase的幻灯片文档。
Hypertable【34】-文献是一个有关“Hypertable”的技术白皮书对该数据存储结构做了较为详细的介绍注Hypertable也是一个开源、高性能、可伸缩的数据库它采用与Google的Bigtable类似的模型。
面向文档的存储Document Oriented Stores
CouchDB【35】– 这是一款面向文档的、开源数据存储管理系统注文献【35】是一本Apache CouchDB的400多页的官方文档。
MongoDB【36】–是目前非常流行的一种非关系型(NoSQL)数据库注文献【36】是一个有关MongoDB的白皮书对MongoDB结构做了很不错的介绍。
面向图Graph的存储
Neo4j【37】–文献是Ian Robinson等撰写的图书《Graph Databases图数据库》注Neo4j是一款目前最为流行的高性能NoSQL 图数据库它使用图来描述数据模型把数据保存为图中的节点以及节点之间的关系。这是最流行的图数据库。
Titan【38】–文献是有关Titan的在线文档Titan是一款Apache许可证框架下的分布式的开源图数据库特别为存储和处理大规模图而做了大量优化。
ACID
我注意到现在很多开源社区正在悄悄发生变化它们开始“亦步亦趋”地跟随谷歌的脚步。这也难怪谷歌太牛跟牛人混近牛者牛 —— 下面4篇文献有3篇来自于谷歌的“神来之笔”他们解决了全球分布一致的数据存储问题。
Megastore【39】–这是一个构建于BigTable之上的、高可用的分布式存储系统文献为有关Megastore的技术白皮书注Megastore在被谷歌使用了数年之后相关技术信息才在2001年公布。CSDN网站亦有文献【39】的中文解读Google Megastore分布式存储技术全揭秘。
Spanner【40】–这是由谷歌研发的、可扩展的、全球分布式的、同步复制数据库支持SQL查询访问。注Spanner的“老爹”是Big Table可以说没有“大表”这个爹就不可能有这个强有力的“扳手” 儿子。它是第一个把数据分布在全球范围内的系统并且支持外部一致性的分布式事务。
MESA【41】–亦是由谷歌研发的、跨地域复制(geo-replicated)、高可用的、可容错的、可扩展的近实时数据仓库系统注在2014年的VLDB 大会上谷歌公布了他们的分析型数据仓库系统MESA该系统主要用于存储Google互联网广告业务相关的关键衡量数据。文献【41】是VLDB的会议论文。
CockroachDB【42】–该系统是由Google前工程师Spencer Kimball领导开发的Spanner 的开源版本注这个项目的绰号是“螳螂Cockroach”其寓意是“活得长久”因为蟑螂是地球上生命力最强的生物之一即使被砍下头颅依然还能存活好几天文献【42】是代码托管网站GitHub上对Cockroach的说明性文档。
资源管理器层Resource Managers
第一代Hadoop的生态系统其资源管理是以整体单一的调度器起家的其代表作品为YARN。而当前的调度器则是朝着分层调度的方向演进Mesos则是这个方向的代表作这种分层的调度方式可以管理不同类型的计算工作负载从而可获取更高的资源利用率和调度效率。
YARN【43】– 这是新一代的MapReduce计算框架简称MRv2它是在第一代MapReduce的基础上演变而来的注MRv2的设计初衷是为了解决第一代Hadoop系统扩展性差、不支持多计算框架等问题。对国内用户而言原文献下载链接可能会产生404错误这里提供一个新文献由2011年剥离自雅虎的Hadoop初创公司Hortonworks给出的官方文献【43】new阅读该文献也可对YARN有较为深入的理解。CSDN亦有对YARN详细解读的文章更快、更强——解析Hadoop新一代MapReduce框架Yarn。
Mesos【44】–这是一个开源的计算框架可对多集群中的资源做弹性管理注Mesos诞生于UC Berkeley的一个研究项目现为Apache旗下的一个开源项目它是一个全局资源调度器。目前Twitter、 Apple等国外大公司正在使用Mesos管理集群资源国内用户有豆瓣等。文献【44】是加州大学伯克利分校的研究人员发表于著名会议NSDI上的学术论文。
这些计算框架和调度器之间是松散耦合的调度器的主要功能就是基于一定的调度策略和调度配置完成作业调度以达到工作负载均衡使有限的资源有较高的利用率。
调度器Schedulers
作业调度器通常以插件的方式加载于计算框架之上常见的作业调度器有4种
计算能力调度器【45】Capacity Scheduler-该文献是一个关于计算能力调度器的指南式文档介绍了计算能力调度器的不同特性。
公平调度器【46】FairShare Scheduler -该文献是Hadoop的公平调度器设计文档介绍了公平调度的各项特征注公平调度是一种赋予作业资源的方法它提供了一个基于任务数的负载均衡机制其目的是让所有的作业随着时间的推移都能平均的获取等同的共享资源。
延迟调度【47】Delayed Scheduling –该文献是加州大学伯克利分校的一份技术报告报告介绍了公平调度器的延迟调度策略。
公平与能力调度器【48】Fair & Capacity schedulers –该文献是一篇关于云环境下的Hadoop调度器的综述性论文。
协调器Coordination
在分布式数据系统中协调器主要用于协调服务和进行状态管理。
Paxos【49】–文献【49】是经典论文“The Part-Time Parliament兼职的议会【50】” 的简化版。
注两篇文献的作者均是莱斯利·兰伯特Leslie Lamport此君是个传奇人物科技论文写作常用编辑器LaTex其中“La”就是来自其姓“Lamport”的前两个字母。Lamport目前是微软研究院首席研究员2013年因其在分布式计算理论领域做出的杰出贡献荣获计算机领域最高奖——图灵奖。
牛人的故事特别多Lamport亦是这样。就这两篇文献而言Lamport的奇闻轶事都值得说道说道。光看其经典论文题目“The Part-Time Parliament兼职的议会【50】”或许就让读者“一头雾水”这是一篇计算机科学领域的论文吗和读者一样感觉的可能还有期刊编辑。其实早在1990年时Lamport就提出Paxos算法他虚构了一个希腊城邦Paxos及其议会以此来形象比喻说明该算法的流程。论文投出后期刊编辑建议Lamport将论文用更加严谨的数学语言重新进行描述一下。可Lamport则认为我的幽默你不懂拒绝修改。时隔八年之后的 1998年Paxos算法才被伯乐期刊《ACM Transactions on Computer Systems》发表。由于Paxos算法本身过于复杂且同行不理解自己的“幽默” 于是2001年Lamport就用简易语言撰写这篇文章重新发表了该论文的简化版【49】即“Paxos made simplePaxos变得简单”。简化版的摘要更简单就一句话“Paxos算法用简易英语说明之很简单”如果去掉中间的那个无故紧要的定语从句就是“Paxos算法很简单”。弄得你都来不及做深思状摘要就完了。这…这…完全颠覆了我们常用的“三段论式提问题、解问题、给结论”的论文摘要写法啊。
后来随着分布式系统的不断发展壮大Paxos算法开始大显神威。Google的Chubby和Apache的Zookeeper都是用Paxos作为其理论基础实现的。就这样 Paxos终于登上大雅之堂它也为Lamport在2013年获得图灵奖立下汗马功劳。从Lamport发表Paxos算法的小案例我们可以看出彪悍的人生不需要解释。牛逼的论文就可以任性
Chubby【51】– 该文献的作者是谷歌工程师Mike Burrows。Chubby系统本质上就是前文提到的Paxos的一个实现版本主要用于谷歌分布式锁服务。注原文链接会出现404错误CSDN网站有Chubby论文的下载链接。
Zookeeper【52】–这是Apache Hadoop框架下的Chubby开源版本。它不仅仅提供简单地上锁服务而事实上它还是一个通用的分布式协调器其设计灵感来自谷歌的Chubby注众所周知分布式协调服务开发困难很大分布式系统中的多进程间很容易发生条件竞争和死锁。ZooKeeper的开发动力就是减轻分布式应用开发的困难使用户不必从零开始构建协调服务。
计算框架Computational Frameworks
运行时计算框架可为不同种类的计算提供运行时runtime环境。最常用的是运行时计算框架是Spark和Flink。
Spark【53】–因Spark日益普及加之其具备良好的多计算环境的适用性它已对传统的Hadoop生态环境形成了严峻的挑战注Spark是一个基于内存计算的开源的集群计算系统其目的在于让数据分析更加快速。Spark是由加州大学伯克利分校的AMP实验室采用Scala语言开发而成。Spark的内存计算框架适合各种迭代算法和交互式数据分析能够提升大数据处理的实时性和准确性现已逐渐获得很多企业的支持如阿里巴巴、百度、网易、英特尔等公司均是其用户。
Flink【54】–这是一个非常类似于Spark的计算框架但在迭代式数据处理上比Spark更给力注目前大数据分析引擎Flink已升级成为Apache顶级项目。
Spark和Flink都属于基础性的大数据处理引擎。具体的计算框架大体上可根据采用的模型及延迟的处理不同来进行分门别类。
批处理Batch
MapReduce【55】– 这是谷歌有关MapReduce的最早的学术论文注对于国内用户点击原文献链接可能会产生404错误CSDN网站有MapReduce论文的下载链接。
MapReduce综述【56】–这是一篇过时、但依然值得一读的、有关MapReduce计算框架的综述性文章。
迭代式BSP
Pregel【57】–这又是一篇谷歌出品的大手笔论文主要描述了大规模图处理方法注Pregel是一种面向图算法的分布式编程框架其采用的是迭代式的计算模型。它被称之为Google后Hadoop时代的新“三驾马车”之一。另外两驾马车分别是“交互式”大数据分析系统Dremel和网络搜索引擎Caffeine。
Giraph【58】– 该系统建模于谷歌的Pregel可视为Pregel的开源版本它是一个基于 Hadoop架构的、可扩展的分布式迭代图处理系统。
GraphX【59】–这是一个同时采用图并行计算和数据并行的计算框架注GraphX最先是加州大学伯克利分校AMPLab实验室的一个分布式图计算框架项目后来整合到Spark中成为其中的一个核心组件。GraphX最大的贡献在于在Spark之上提供一栈式数据解决方案可方便高效地完成图计算的一整套流水作业。
Hama【60】– 是一个构建Hadoop之上的基于BSP模型的分布式计算引擎注
Hama的运行环境需要关联 Zookeeper、HBase、HDFS 组件。Hama中最关键的技术就是采用了BSP模型(Bulk Synchronous Parallel即整体同步并行计算模型又名大同步模型)。BSP模型是哈佛大学的计算机科学家Viliant和牛津大学的BillMcColl在1990年联合提出的他们希望能像冯·诺伊曼体系结构那样架起计算机程序语言和体系结构间的桥梁故又称作桥模型(Bridge Model)。
开源图处理系统【61】Open source graph processing -这是滑铁卢大学的研究人员撰写的综述性文献文献【61】对类PregelPregel-like的、基于BSP模型的图处理系统进行了实验性的比较。
流式Streaming
流式处理【62】Stream Processing- 这是一篇非常棒的、有关面向大数据实时处理系统的综述性文章。
Storm【63】– 这是一个大数据实时处理系统注Storm有时也被人们称为实时处理领域的Hadoop它大大简化了面向庞大规模数据流的处理机制从而在实时处理领域扮演着重要角色。文献【63】是Twitter工程师们在2014年发表于SIGMOD上的学术论文。
Samza【64】-这是一款由Linkedin公司开发的分布式的流式数据处理框架注所谓流式数据是指要在处理单位内得到的数据这种方式更注重于实时性流式数据有时也称为快数据。
Spark流【65】Spark Streaming -该文献是加州大学伯克利分校的研究人员于2013年在著名操作系统会议SOSP上发表的学术论文论文题目是《离散流容错大规模流式计算》注这里的离散流是指一种微批处理构架其桥接了传统的批处理和交互式处理。Spark Streaming是Spark 核心API的一个扩展它并不会像Storm那样逐个处理数据流而是在处理前按时间间隔预先将其切分为很多小段的批处理作业。
交互式Interactive
Dremel【66】–这又是一篇由谷歌出品的经典论文论文描述了如何处理“交互式”大数据的工作负载。该论文是多个基于Hadoop的开源SQL系统的理论基础注文献【66】写于2006年“捂”藏4年之后于2010年公布于众。文章针对MR交互式查询能力不足提出了Dremel阐述了Dremel的设计原理并提供了部分测试报告。
Impala【67】–这是一个大规模并行处理MPP式 SQL 大数据分析引擎注
Impala像Dremel一样其借鉴了MPPMassively Parallel Processing大规模并行处理并行数据库的思想抛弃了MapReduce这个不太适合做SQL查询的范式从而让Hadoop支持处理交互式的工作负载。本文作者阿尼尔马丹在LinkedIn上的博客原文在此处的“MPI”系“MPP”笔误读者可参阅文献【67】发现此问题。
Drill【68】–这是谷歌 Dremel的开源版本注Drill是一个低延迟的、能对海量数据包括结构化、半结构化及嵌套数据实施交互式查询的分布式数据引擎。
Shark【69】–该文献是2012年发表于SIGMOD的一篇学术论文论文对Spark生态系统上的数据分析能力给出了很深入的介绍注Shark是由加州伯克利大学AMPLab开发的大数据分析系统。Shark即“Hive on Spark”的含义本质上是通过Hive的HQL解析把HQL翻译成Spark上的RDD操作。然后通过Hive的元数据获取数据库里的表信息。HDFS上的数据和文件最后会由Shark获取并放到Spark上运算。Shark基于 Scala语言的算子推导可实现良好的容错机制对执行失败的长/短任务均能从上一个“快照点Snapshot”进行快速恢复。
Shark【70】–这是另外一篇很棒的于2013年发表在SIGMOD的学术论文其深度解读在Apache Hive之上SQL访问机制注这篇文献描述了如何构建在Spark上构建SQL引擎——Shark。更重要的是文章还讨论了之前在 Hadoop/MapReduce上实施SQL查询如此之慢的原因。
Dryad【71】– 文献讨论了使用有向无环图(Directed Acycline GraphDAG)来配置和执行并行数据流水线的方法注Dryad是一个通用的粗颗粒度的分布式计算和资源调度引擎其核心特性之一就是允许用户自己构建DAG调度拓扑图。文献【71】是微软于2007年在EuroSys国际会议上发布的学术论文。
Tez【72】–其核心思想来源于Dryad可视为利用Yarn(即MRv2)对Dryad的开源实现注Apache Tez是基于Hadoop Yarn之上的DAG计算框架。由Hadoop的二东家Hortonworks开发并提供主要技术支持。文献【72】是一个关于Tez的简要介绍文档。
BlinkDB【73】–可在抽样数据上实现交互式查询其呈现出的查询结果附带有误差标识。
注BlinkDB 是一个用于在海量数据上运行交互式 SQL 查询的大规模并行查询引擎。BlinkDB允许用户通过适当降低数据精度对数据进行先采样后计算其通过其独特的优化技术实现了比Hive快百倍的交互式查询速度而查询进度误差仅降低2~10%。
BlinkDB采用的策略与大数据布道师维克托·迈尔-舍恩伯格在其著作《大数据时代》中提到的观点“要全体不要抽样”恰恰相反。
基于常识我们知道多了你就快不了。好了你就省不了。对大数据处理而言也是这样。英特尔中国研究院院长吴甘沙认为大体量、精确性和速度×××者不可兼得顶多取其二。如果要实现在大体量数据上的 “快”就得想办法减少数据而减少数据势必要适度地降低分析精确性。
事实上大数据并不见得越“大”越好有时候一味的追求“大”是没有必要的。例如在医疗健康领域如果来监控某个病人的体温可穿戴设备可以一秒钟采集一次数据也可以一分钟采集一次数据前者采集的数据总量比后者“大”60倍但就监控病人身体状况而言意义并不是太大。虽然后者的数据忽略了人体在一分钟内的变化监控的精度有所下降但对于完成监控病人健康状态这一目的而言是可以接受的。
实时系统RealTime
Druid【74】–这是一个开源的分布式实时数据分析和存储系统旨在快速处理大规模的数据并能做到快速查询和分析注文献【74】是2014年Druid创始人Eric Tschetter和中国工程师杨仿今等人在SIGMOD上发表的一篇论文。
Pinot【75】–这是由LinkedIn公司出品的一个开源的、实时分布式的 OLAP数据分析存储系统非常类似于前面提到的DruidLinkedIn 使用它实现低延迟可伸缩的实时分析。注文献【75】是在GitHub上的有关Pinot的说明性文档。
数据分析层Data Analysis
数据分析层中的工具涵盖范围很广从诸如SQL的声明式编程语言到诸如Pig的过程化编程语言均有涉及。另一方面数据分析层中的库也很丰富可支持常见的数据挖掘和机器学习算法这些类库可拿来即用甚是方便。
工具Tools
Pig【76】–这是一篇有关Pig Latin非常不错的综述文章注Pig Latin原是一种儿童黑话属于是一种英语语言游戏形式是在英语上加上一点规则使发音改变让大人们听不懂从而完成孩子们独懂的交流。文献【76】是雅虎的工程师们于2008年发表在SIGMOD的一篇论文论文的题目是“Pig Latin并不是太老外的一种数据语言”言外之意他们发明了一种数据处理的“黑话”——Pig Latin一开始你可能不懂等你熟悉了就会发现这种数据查询语言的乐趣所在。
Pig【77】– 这是另外一篇由雅虎工程师们撰写的有关使用Pig经验的论文文章介绍了如果利用Pig在Map-Reduce上构建一个高水准的数据流分析系统。
Hive【78】–该文献是Facebook数据基础设施研究小组撰写的一篇学术论文介绍了Hive的来龙去脉注Hive是一个建立于 Hadoop 上的数据仓库基础构架。它用来进行数据的提取、转化和加载即Extract-Transform-Load ETL它是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。
Hive【79】–该文献是另外一篇有关Hive的值得一读的好论文。论文作者来自Facebook数据基础设施研究小组在这篇论文里可以帮助读者理解Hive的设计理念。
Phoenix【80】–它是 HBase 的 SQL 驱动注Phoenix可将 SQL 查询转成 HBase 的扫描及相应的动作。文献【80】是关于在Hbase上部署SQL的幻灯片文档。
Map Reduce上的连接join算法【81】–该文献介绍了在Hadoop环境下的各种并行连接算法并对它们的性能作出系统性评测。
Map Reduce上的连接算法【82】–这是威斯康星大学和IBM研究团队撰写的综述性文章文章对在Map Reduce模型下的各种连接算法进行了综合比较。
库Libraires
MLlib【83】–这是在Spark计算框架中对常用的机器学习算法的实现库该库还包括相关的测试和数据生成器注文献【83】是MLlib的一个幻灯片说明文档。
SparkR【84】–这是AMPLab发布的一个R开发包为Apache Spark提供轻量级的前端注R是一种广泛应用于统计分析、绘图的语言及操作环境。文献【84】是有关SparkR的幻灯片文档。
Mahout【85】–这是一个功能强大的数据挖掘工具是一个基于传统Map Reduce的分布式机器学习框架注Mahout的中文含义就是“驭象之人”而Hadoop的Logo正是一头小黄象。很明显这个库是帮助用户用好Hadoop这头难用的大象。文献【85】是有关Mahout的图书。
数据集成层Data Integration
数据集成框架提供了良好的机制以协助高效地摄取和输出大数据系统之间的数据。从业务流程线到元数据框架数据集成层皆有涵盖从而提供全方位的数据在整个生命周期的管理和治理。
摄入/消息传递Ingest/Messaging
Flume【86】–这是Apache旗下的一个分布式的、高可靠的、高可用的服务框架可协助从分散式或集中式数据源采集、聚合和传输海量日志注文献【86】是Apache网站上有关Flume的一篇博客文章。
Sqoop【87】–该系统主要用来在Hadoop和关系数据库中传递数据注Sqoop目前已成为Apache的顶级项目之一。通过Sqoop可以方便地将数据从关系数据库导入到HDFS或反之亦可。文献【87】是有关Sqoop的幻灯片说明文档。
Kafka【88】–这是由LinkedIn开发的一个分布式消息系统注由Scala编写而成的Kafka由于可水平扩展、吞吐率高等特性得到广泛应用。文献【88】是LindedIn的工程师们在2011年发表于NetDB的会议论文。
ETL/工作流
ETL是数据抽取Extract、清洗Cleaning、转换Transform、装载Load的过程是构建数据仓库的重要一环。
Crunch【89】–这是Apache旗下的一套Java API函数库它能够大大简化编写、测试、运行MapReduce 处理工作流的程序注文献【89】是有关Crunch的幻灯片解释文档。
Falcon【90】– 这是Apache旗下的Falcon大数据管理框架可以帮助用户自动迁移和处理大数据集合注文献【90】是一份关于Falcon技术预览报告。
Cascading【91】–这是一个架构在Hadoop上的API函数库用来创建复杂的可容错的数据处理工作流注文献【91】是关于Hadoop上的Cascading的概论和技术随笔。
Oozie【92】–是一个工作流引擎用来协助Hadoop作业管理注Oozie字面含义是驯象之人其寓意和Mahout一样帮助用户更好地搞定Hadoop这头大象。文献【92】是Apache网站上有关Oozie的官方文档。
元数据Metadata
HCatalog【93】– 它提供了面向Apache Hadoop的数据表和存储管理服务注Apache HCatalog提供一个共享的模式和数据类型的机制它抽象出表使用户不必关心数据怎么存储并提供了可操作的跨数据处理工具。文献【93】是Apache网站有关Hcatalog的官方说明文档。
序列化Serialization
Protocol Buffers【94】–由Google推广的一种与语言无关的、对结构化数据进行序列化和反序列化的机制注Protocol Buffers可用于通讯协议、数据存储等领域的语言及平台无关、可扩展的序列化结构数据格式。文献【94】是有关Protocol Buffers幻灯片文档。
Avro【95】–这是一个建模于Protocol Buffers之上的、Hadoop生态系统中的子项目注Avro本身既是一个序列化框架同时也实现了RPC的功能。
操作框架Operational Frameworks
最后我们还需要一个操作性框架来构建一套衡量标准和测试基准从而来评价各种计算框架的性能优劣。在这个操作性框架中还需要包括性能优化工具借助它来平衡工作负载。
监测管理框架Monitoring Frameworks
OpenTSDB【96】–这是构建于HBase之上的实时性能评测系统注文献【96】提供了OpenTSDB的简要概述介绍了OpenTSDB的工作机理。
Ambari【97】– 这是一款基于Web的系统支持Apache Hadoop集群的供应、管理和监控注文献【97】阐述了Ambari架构的设计准则。
基准测试Benchmarking
YCSB【98】–该文献是一篇使用YCSB对NoSQL系统进行性能评估的期刊论文注YCSB是雅虎云服务基准测试Yahoo! Cloud Serving Benchmark的简写。见名知意它是由雅虎出品的一款通用云服务性能测试工具。
GridMix【99】–该系统通过运行大量合成的作业对Hadoop系统进行基准测试从而获得性能评价指标注文献是Apache网站有关GridMix的官方说明文档。
最后一篇文献是有关大数据基准测试的综述文章【100】文章讨论了基准测试的最新技术进展以及所面临的几个主要挑战。
译者寄语
在你迈步于大数据的旅途中真心希望这些文献能助你一臂之力。但要知道有关大数据的文献何止千万由于个人精力、能力有限有些领域也不甚熟稔故难免会挂一漏万。如有疏忽漏掉你的大作还请你海涵。最后希望这些文献能给你带来“学而时习之不亦乐乎”的快感
译者介绍张玉宏博士。2012年毕业于电子科技大学现执教于河南工业大学。中国计算机协会CCF会员ACM/IEEE会员。主要研究方向为高性能计算、生物信息学主编有《Java从入门到精通》一书。
原文来自LinkeDin
学海无涯 学无止境 共勉
本文信息来自今日头条网址http://toutiao.com/a4666860026/?tt_from=mobile_qq&iid=2512939059&app=news_article