本节内容实现对《海上牧云记》腾讯视频的评论进行批量爬取并自动加载新评论,然后将爬取到的评论内容存储到mongodb数据库。
分析网页
我们爬取的视频网址为:https://v.qq.com/x/cover/qg67m04ckextp6j.html,该页面为《海上牧云记》视频网址,可以看到每页只有20条评论,要看到新评论还需点击“加载更多”,则新评论会在当前页面中加载出来后显示。首先用Fiddler对该网址进行分析,可以在此处下载:https://www.telerik.com/download/fiddler。
打开Fiddler,将网页拖至评论处,点击“加载更多”。切换到Fiddler会话页面,找到触发的真实网址。


在Fiddler可以看到该会话头部请求详情。将触发的网址url复制出来,再次点击“加载更多”,截获下一页会话信息,复制url,将两次网址对比分析。
可以发现,commentid字段表示评论id,reqnum=20表示每次加载20条评论,2242304383为《海上牧云记》这部视频的编号,后续的字段“&tag=&callback=jQuery11240522367052619634_1511758225427&_=1511758225429”可以省略,省略后打开网址验证。
分析网页,有一些unicode编码后才会显示的内容。可以发现“content”即为评论内容,“nick”即为用户名。找到评论内容后就可以构造正则表达式来定向爬取评论内容了。


爬虫编写
首先因为一些发爬虫机制,要设置头信息伪装成浏览器进行爬取。在python中可以通过opener.addheaders为爬虫添加Headers信息,可以在Fiddler截获到的会话信息中查看Headers信息,也可以在浏览器中按F12,点进网址查看Headers信息。 "User-Agent"即为模拟浏览器所需的字段。
#导入所需库
import urllib.request
import http.cookiejar
import re
#视频编号
vid="2242304383"
#评论起始ID
comid="6340772257283452000"
#构造真实评论请求网址
url= "http://coral.qq.com/article/"+vid+"/comment?commentid="+comid+"&reqnum=20"
#设置头信息伪装成浏览器进行爬取
headers={ "Accept":" text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Encoding":" gb2312,utf-8",
"Accept-Language":" zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36",
"Connection": "keep-alive",
"referer":"qq.com"}
涉及到登录的操作,会用到Cookie。HTTP协议为无状态协议,无法维持会话之间的状态,如果涉及网页的更新就要反复登录,但是Cookie可以保存会话信息,在爬取网页时,设置好Cookie就会保持登录状态进行爬取。
#设置cookie,使用http.cookiejar.CookieJar()创建CookieJar对象
cjar=http.cookiejar.CookieJar()
#使用HTTPCookieProcessor创建cookie处理器,并以其为参数构建opener对象
opener = urllib.request.build_opener(urllib.request.HTTPCookieProcessor(cjar))
#建立空链表,以指定格式存储头信息
headall=[]
#构造出指定的headers信息
for key,value in headers.items():
item=(key,value)
headall.append(item)
#将opener安装为全局
opener.addheaders = headall
urllib.request.install_opener(opener)
建立一个自定义函数craw(vid,comid),实现自动抓取对应评论网页并返回抓取数据,然后构建爬取内容的正则表达式。
def craw(vid,comid):
url= "http://coral.qq.com/article/"+vid+"/comment?commentid="+comid+"&reqnum=20"
data=urllib.request.urlopen(url).read().decode("utf-8")
return data
#分别构建id、用户名、评论内容等信息的正则表达式
idpat='"id":"(.*?)"'
userpat='"nick":"(.*?)",'
conpat='"content":"(.*?)",'
实现爬取评论内容并存储到.txt文件,爬取共20页的评论内容。保存时因为有一些无用的特殊字符或者表情,在写入文件时会出现无法编译的错误,用errors='ignore'可以忽略这些错误,只保存文字。
f=open("D:\\Learn\\python\\web\\testresult\\commend.txt","w+",errors='ignore')
#第一层循环,代表抓取多少页,每一次外层循环抓取一页
for i in range(1,20):
data=craw(vid,comid)
#第二层循环,根据抓取的结果提取并处理每条评论的信息,一页20条评论
for j in range(0,20):
idlist=re.compile(idpat,re.S).findall(data)
userlist=re.compile(userpat,re.S).findall(data)
conlist=re.compile(conpat,re.S).findall(data)
#eval()将字符串str当成有效的表达式来求值并返回计算结果
print(eval('u"'+conlist[j]+'"'),file=f)
#将comid改变为该页的最后一条评论id,实现不断自动加载
comid=idlist[19]
f.close()
然后就可以爬取到评论内容了,生成的文件如下所示:

MongoDB数据库存储
可以把爬取到的评论内容保存到mongodb数据库中,MongoDB提供了一个面向文档存储的数据库,操作起来比较简单和容易。这里只爬取到约400条新评论做简单存储分析,读者自己写爬虫时可增加爬取页数,爬取千条评论样本作存储分析。
mongodb可以在官网下载,安装后将其设置为服务,可以参考该条经验。
import pymongo
client = pymongo.MongoClient('localhost',27017)
#给数据库命名
commend = client['commend']
#在文件下创建表单
sheet_tab = commend['sheet_tab']
#往数据库中写入数据
path = 'D:\\Learn\\python\\web\\testresult\\commend.txt'
with open(path,'r') as f:
lines=f.readlines()
for index,line in enumerate(lines):
data = {
'index':index,
'line':line,
'words':len(line.split())
}
sheet_tab.insert_one(data)
#展示数据库中的数据
for item in sheet_tab.find():
print(item)
情感分析
然后可以对评论做后续的处理和研究了,比如说情感分析。
import codecs
import matplotlib.pyplot as plt
import numpy as np
from snownlp import SnowNLP
from snownlp import sentiment
from snownlp.sentiment import Sentiment
comment=[]
path = 'D:\\Learn\\python\\web\\testresult\\commend.txt'
with open(path,'r') as f:
rows=f.readlines()
for row in rows:
if (row != '\n'):
if row not in comment:
comment.append(row.strip('\n'))
print(comment)
def snowanalysis(self):
sentimentslist = []
num=0
for li in self:
s = SnowNLP(li)
if(s.sentiments>0.5):
num+=1
sentimentslist.append(s.sentiments)
print(float(num/len(sentimentslist)))
plt.hist(sentimentslist,bins=np.arange(0,1,0.01))
plt.show()
snowanalysis(comment)
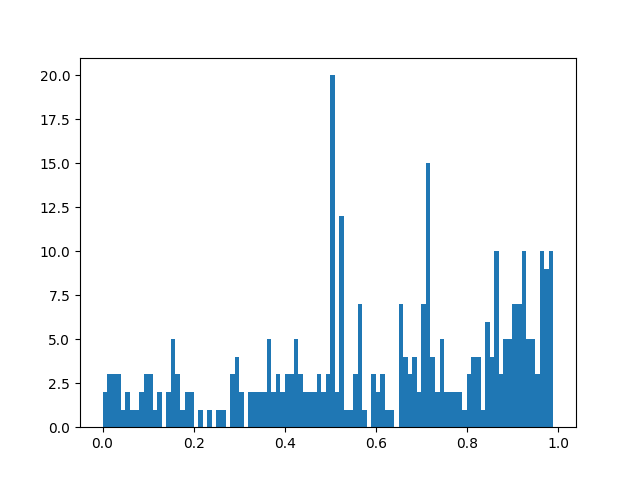
通过SnowNLP对短评进行积极和消极情感分类,该库可以在cmd下用“pip install snownlp”安装。读取每段评论依次进行分析,返回一个0~1之间的值,大于0.5代表句子的情感性偏向积极;小于0.5代表情感偏向消极。统计发现约有67.3%的评论偏向积极和好评。情感偏向分布如下图所示,可以看出偏向积极的评论多于消极评论,立场中位的评论明显突出。
同样方法读者可实现对其他腾讯视频的评论进行批量爬取并自动加载新评论,然后将爬取到的评论内容存储到mongodb数据库,或者自己作评论的情感分析啦。