基本
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
安装与插件添加
一、安装 elasticsearch 成服务 es-root\bin>service.bat install
二、安装 head 插件 es-root\bin>plugin install mobz/elasticsearch-head
三、安装 bigdesk 插件 es-root\bin>plugin install lukas-vlcek/bigdesk
四、安装 IK Analysis Plugin
五、安装 Index Termlist Plugin
转载自:http://b1.qzone.qq.com/cgi-bin/blognew/blog_output_data?uin=16490307&blogid=1463105647&styledm=cm.qzonestyle.gtimg.cn&imgdm=cm.qzs.qq.com&bdm=b.qzone.qq.com&mode=2&numperpage=15×tamp=1463326261&dprefix=&blogseed=0.23445320974400174&inCharset=gb2312&outCharset=gb2312&ref=qzone&entertime=1463326251011
查询入门
第一节:match与term 查询
一、 match(单分词匹配查询)(任意)
match(单分词匹配查询),会对查询语句分词,比如"代表团参加审议"会被分词为"代表团 参加 审议", 那么对应查询字段上包含这三个分词中的一个或多个的所有文档就会被搜索出来,不要求完全匹配,但会按分词的匹配情况打分。
1、执行代码
http://localhost:9200/newooo/_search/ 【POST】
{
"query": {
"match": {
"content": {
"query": "代表团参加审议"
}
}
}
}
代表团参加审议——》代表团 参加 审议
2、 执行效果 (例句命中 参加 审议 2个分词,故选中!)
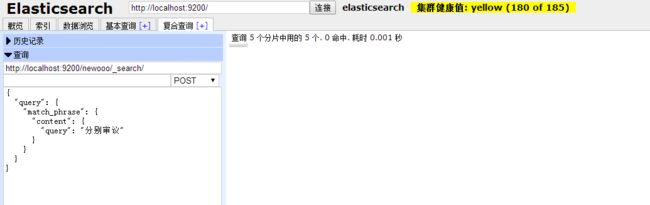
二、 match_phrase (多分词匹配查询) (精确)
1、执行代码
http://localhost:9200/newooo/_search/ 【POST】
{
"query": {
"match_phrase": {
"content": {
"query": "分别参加审议"
}
}
}
}
分别参加审议——>分别 参见 审议 ——》三个分词都必须包含,且三个分词间没有其他分词,否则落选。
2、执行效果 (上例中,分词包含 参加、 审议,但没有 分别 ,故未中选。)
三、match_phrase (多分词匹配查询)(宽松)
完全匹配可能比较严,我们会希望有个可调节因子,允许多分词间其他分词出现,那就需要用到slop,间距因子,即允许间隔的分词个数。体会下列加上slop间距因子的差异!
a.严格精确多分词匹配分别、审议,失败;
b.允许间距因子的多分词匹配,成功!————加上了slop=1

四、term 查询 (查询语句不分词,查询目标字段分词与否—随意)
term,不对查询语句分词。在对Analyzed 文档查询时,与bool查询(must、must_not、should)等组合,可以替代match==query_string使用。在对NotAnalyzed文档查询时,不是网上人云亦云的部分匹配方式!而是:term与目标字段内容完全相等才算匹配!
ELASTICSEARCH TERM OR TERMS QUERY NOT WORKING? START HERE.(与我的实验结果一致)
https://www.pmg.com/blog/elasticsearch-term-terms-query-not-working/
https://www.elastic.co/guide/en/elasticsearch/reference/current/query-dsl-term-query.html ;
————部分匹配(通配查询),请用下列方法:
prefix,不对查询语句分词。 http://blog.csdn.net/dm_vincent/article/details/42001851 ;
wildcard,不对查询语句分词。 http://blog.csdn.net/dm_vincent/article/details/42024799
regexp,不对查询语句分词。 http://blog.csdn.net/dm_vincent/article/details/42024799
第二节:bool查询与match查询的关系
一、match查询(默认or操作符)== bool查询组合起来的should查询
match查询,其实只是简单地将生成的term查询包含在了一个bool查询中。通过默认or操作符,每个term查询都以一个语句被添加,所以等效于一个should语句匹配(should语句,对于一个文档,只要有一个查询分词匹配,那么这个文档就被看成是匹配的。)。以下两个查询是等价的:
{
"query": {
"match": {
"title": {
"query": "上海奶粉"
}
}
},
"from": 0,
"size": 100,
"sort": {
"time": {
"order": "desc"
}
}
}
------------------------------------------
{
"query": {
"bool": {
"should": [
{"term": {"title": "上海"}},
{"term": {"title": "奶粉"}}
]
}
},
"size": 100
......
}
二、match查询(and操作符)== bool查询组合起来的must查询
match查询,使用and操作符时,所有的term查询都以must语句被添加,因此所有的查询都需要匹配。以下两个查询是等价的:
{
"query": {
"match": {
"title": {
"query": "上海奶粉",
"operator": "and"
}
}
},
"from": 0,
"size": 100,
"sort": {
"time": {
"order": "desc"
}
}
}
-----------------------------------------------
{
"query": {
"bool": {
"must": [
{"term": {"title": "上海"}},
{"term": {"title": "奶粉"}}
]
}
},
"size": 100
......
}
三、match查询(minimum_should_match)
如果指定了minimum_should_match参数,它会直接被传入到bool查询中,下面两个查询是等价的:
{
"query": {
"match": {
"title": {
"query": "quick brown fox",
"minimum_should_match": "75%"
}
}
},
"size": 100
}
----------------------------------------------------------
{
"query": {
"bool": {
"should": [
{"term": {"title": "brown"}},
{"term": {"title": "fox"}},
{"term": {"title": "quick"}}
],
"minimum_should_match": 2
}
},
"size": 100
}
转载自:http://b1.qzone.qq.com/cgi-bin/blognew/blog_output_data?uin=16490307&blogid=1460552699&styledm=cm.qzonestyle.gtimg.cn&imgdm=cm.qzs.qq.com&bdm=b.qzone.qq.com&mode=2&numperpage=15×tamp=1463326270&dprefix=&blogseed=0.8164294279934445&inCharset=gb2312&outCharset=gb2312&ref=qzone&entertime=1463326277201
分词专题
一、为elasticsearch安装分词器
在elasticsearch.yml文件末,添加下列文字。
index.analysis.analyzer.ik.type : "ik"
index:
analysis:
analyzer:
ik:
alias: [ik_analyzer]
type: org.elasticsearch.index.analysis.IkAnalyzerProvider
ik_smart:
type: ik
use_smart: true
ik_max_word:
type: ik
use_smart: false
提示:不用去变动elasticsearch的default analyzer设置。
分词测试:http://localhost:9200/163/_analyze?analyzer=ik_smart&pretty=true&text=食品安全
————可以帮助确定目标是否可以视为一个分词,或者看看目标会分词成什么样。
二、自定义字典
config/ik/IKAnalyzer.cfg.xml
IK Analyzer 扩展配置
custom/mydict.dic;
custom/single_word_low_freq.dic;
custom/sougou.dic;
custom/ext_stopword.dic
(停留词,指文本中出现频率很高,但实际意义又不大的词,主要指副词、虚词、语气词等。如“是”、“而是”、“吗”等。建立停留词过滤字典,可以在为文本建立索引(分词)时,过滤(忽略)掉这些词。—可以自己丰富完善。)
location
location
三、热更新 IK 分词方法
IK插件支持热更新 IK 分词。
location
location
其中 location 是指一个 url,比如 http://yoursite.com/getCustomDict,该请求只需满足以下两点即可完成分词热更新。
1、该 http 请求需要返回两个头部(header),一个是 Last-Modified,一个是 ETag,这两者都是字符串类型,只要有一个发生变化,该插件就会去抓取新的分词进而更新词库。
2、该 http 请求返回的内容格式是一行一个分词,换行符用 \n 即可。
满足上面两点要求就可以实现热更新分词了,不需要重启 ES 实例。
可以将需自动更新的热词放在一个 UTF-8 编码的 .txt 文件里,放在web server 下,当 .txt 文件修改时,http server 会在客户端请求该文件时自动返回相应的 Last-Modified 和 ETag。可以另外做一个工具来从业务系统提取相关词汇,并更新这个 .txt 文件。
常见问题
1.自定义词典为什么没有生效? 请确保你的扩展词典的文本格式为 UTF8 编码 。
转载自:http://b1.qzone.qq.com/cgi-bin/blognew/blog_output_data?uin=16490307&blogid=1463108006&styledm=cm.qzonestyle.gtimg.cn&imgdm=cm.qzs.qq.com&bdm=b.qzone.qq.com&mode=2&numperpage=15×tamp=1463373088&dprefix=&blogseed=0.23974922925830322&inCharset=gb2312&outCharset=gb2312&ref=qzone&entertime=1463373077928
参考:http://wiki.jikexueyuan.com/project/elasticsearch-definitive-guide-cn/010_Intro/00_README.html