SQL索引学习-索引结构
前一阵无意中和同事讨论过一个SQL相关的题(通过一个小问题来学习SQL关联查询),很惭愧一个非常简单的问题由于种种原因居然没有回答正确,数据库知识方面我算不上技术好,谈起SQL知识的学习我得益于2008年进的一家公司,有几个DBA技术相当专业,正好手上有一个项目遇到了一些数据库查询性能问题,就试着想办法优化,于是自己将相法和DBA沟通后,居然得到了他们的赞同,让我信心大增,后来一段时间我又主动找他们聊了一些其它的知识,所以在数据库索引这块我算是相对一般的.net程序员要更加有见解一些。当时我们部门由于分工的不同,部门20多人基本上工作中从来不和SQL打交道,后台的接口都由其它部门来完成了,我们注意的 业务逻辑,所以有一些完全不懂SQL的程序员。之后的四年我大部分都是做一些通用平台架构方面的工作,也比较少直接接触SQL,直到后来换了公司,特别是去年开始由于项目性质的变化,我开始慢慢又开始接触SQL。

工作时间的长短在某种程度上能决定一个人的技术水平,但往往技术水平和实际工作的产出不一定成正比。比如我上面提到那个SQL问题,很多有经验的程序员在第一个答案中往往回答错误,但他确实能将项目做好,因为大家平时观注的还是结果,只要结果出来了比什么都强,至于为什么出这样的结果一般也就不会多做分析研究。这种形式呢,对那些对技术提升没有强烈要求的人来讲,已经够用了,多试几次,只要最终能出结果也就万事大吉了,做的多了,后续遇到类似的问题也就轻车熟路了,这就是所谓的经验,只知道这样做就能出结果。

其实这种工作学习方式呢,有一个比较显著的问题,就是对自己写出来的东西没有足够的信心,因为靠的是以往的经验。是出现错误之后通过不断的尝试来取得的经验,有一种探索的味道,在工作效率上会存在问题,因为总有你以前没有遇到过的场景,这样你可能对第一方案做多次尝试才找到正解,反之的话,第一个方案可能花的时间稍长一些,但后续反复修改的次数会相当较少。
SQL索引目录
借这次机会呢,将SQL索引的理解整理出来,供大家一起学习提高,这是我的学习笔记,有错误的地方,欢迎大家批评指正。下面是预计的目录:

- 索引基础知识
- 聚集索引
- 非聚集索引
- 认识执行计划
- 灵活设计数据库
页和区
要想做好索引优化,知道索引的存储结构是至关重要的。谈到存储就需要了解SQL中的页和区的概念:
- SQL中存储数据的基础单位就是页,一个页大小为8K,数据库可以将数据从逻辑上分成页,磁盘的I/O操作就是在页级执行。页包信三项内容:
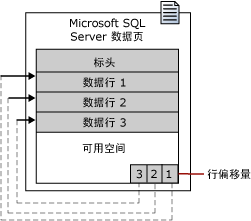
- 96字节大小的标头,存储统计信息,包括页码、页类型、页的可用空间以及拥有该页的对象的分配单元 ID。页类型我们知识如下三项基本就够用:
- 数据页,除了大型对象的数据列之外的数据存储页,比如int,float,varchar等。
- 索引页,存放索引的条目。
- 大型对象数据类型,比如text,image,nvarchar(max)等。
-
- 数据行
- 行偏移量
- 一个区包含8个页,它是管理空间的单位,分为如下两类
- 统一区,由单个对象所有。
- 混合区,最多可由八个对象共享。
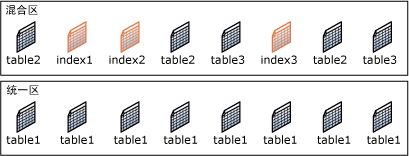
- 一般情况下,给表或者索引申请新的空间时,从混合区分配,当这个表或者索引的空间超过8个页大小时,会将原本在混合区的页转移到统一区管理。
表存储结构
知识了区以及页的概念,再看下数据表和这两者之间的联系, 表包含一个或多个分区,每个分区在一个堆或一个聚集索引结构中包含数据行。从下图的结构中,我们就看到了索引的重要结构B-树了。
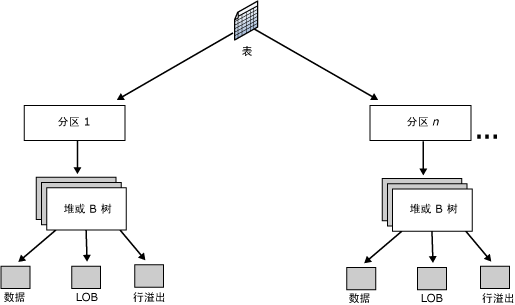
聚集索引结构
索引中的底层节点称为叶节点。根节点与叶节点之间的任何索引级别统称为中间级。在聚集索引中,叶节点包含基础表的数据页。根节点和中间级节点包含存有索引行的索引页。每个索引行包含一个键值和一个指针,该指针指向 B -树上的某一中间级页或叶级索引中的某个数据行。每级索引中的页均被链接在双向链接列表中。
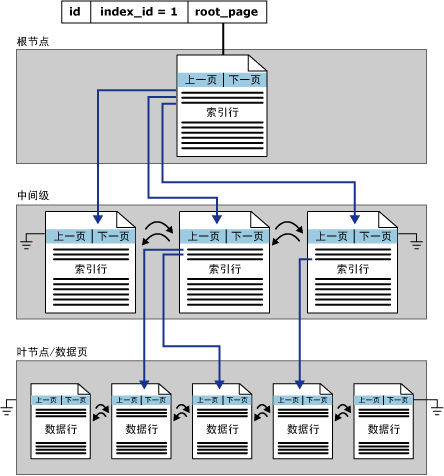
非聚集索引结构
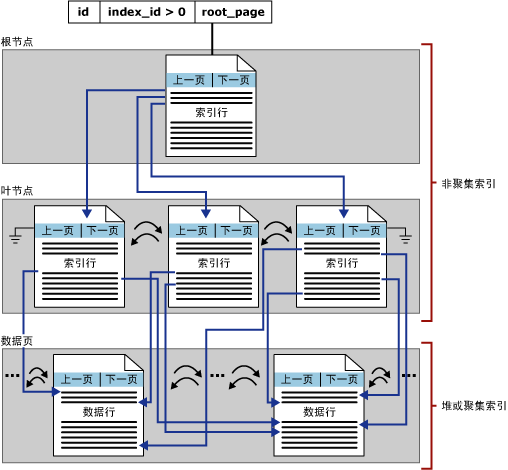
非聚集索引与聚集索引之间的显著差别在于以下两点:
- 基础表的数据行不按非聚集键的顺序排序和存储。
- 非聚集索引的叶层是由索引页而不是由数据页组成。

问题:
- 索引的结构到底分多少层?
我们先看下B-树,这种索引结构有一个重要的参数n,它决定了索引存储页的布局,每个存储页需要存放n个节点,以及n+1个指针。 这里我们来做个计算:比如我们的索引是一个整形数字,4个字节,指针需要8个字节,这里不考虑索引页标头信息的占用,算下最大的n,公式: 4n+8(n+1)<=8*1024 ,这个值是680,即最大可存放680个键,再按B-树充满度来取75%等于510,根结点有510个,那么它会有510*510个叶结点,这些叶结点会有510*510*510个指向最终记录的指针。这个数据足以说明绝多数情况下,只要三层就能够用。
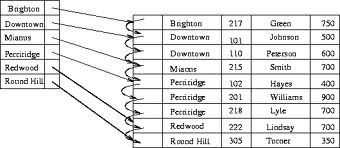
- 什么是稠密索引?
索引中的键顺序与数据文件中的排序顺序相同,所以我们的索引结构中,叶级均采用稿密索引。
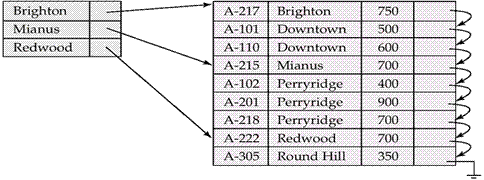
- 什么是稀疏索引?
它只为每个存储块设计键-指针对,比稿密索引节约空间,出现在叶级之上的结构中。
- 索引结构中会出现如下情况吗?
要想回答这个问题,就需要了解索引在维护过程中对于B-树的调整,SQL会通过一定的算法将B-树的充满度达到一定的平衡,这里就会涉及的节点的拆分以及合并,所以一般情况下无论对数据做怎样的更新,也不会出现下图中如此不平衡的情况。
注:如果问重建索引的好处时,如果你回答是为了平衡B-树,那么要谨慎回答。

总结:
数据存储的基础知识,索引结构对于我们后续理解聚集索引以及非聚集索引都非常重要,也才有可能快速准确的做出优化方案。
参考:http://technet.microsoft.com/zh-cn/library/ms180978(v=sql.105).aspx