一、前言
本文只介绍将 JDBC Request 查询结果作为下一个接口参数的方法,下载 mysql-connector-java-5.1.42-bin.jar,怎么将jmeter连接数据库等等准备工作可以百度,下面直接进入正题。
二、需求
存在一个tieba_info 表,表结构如下图
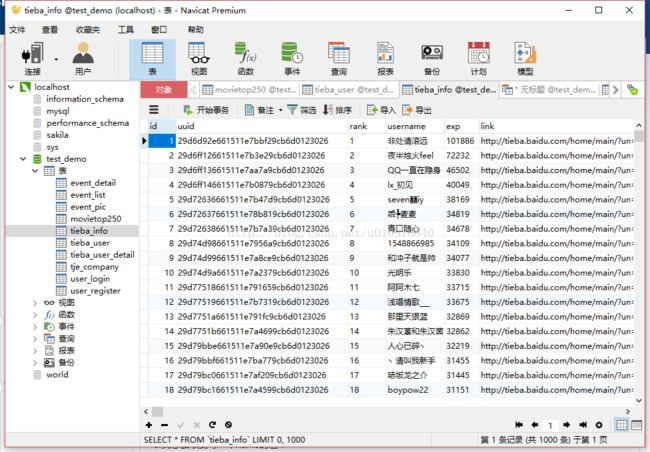
现在有一个需求,从数据库tieba_info表查出rank小于某个值的username和uuid,然后把所有查出来的 username 和 uuid作为参数值,用于下一个接口,注意 username和uuid 要一一对应
三、分析及实践
1、分析
- 要查出
username和uuid,那么首先就要有 1 个或者 2 个jdbc request,连接本地数据看,分别查询出我们需要的username和uuid; -
rank小于某个值,这个值我们可以做一个变量,方便管理。我们查出来的username和uuid可能会有很多个,具体多少根据我们的条件rank来变化; - 查询出所有
username和uuid后,我怎么取到每一个username和对应的uuid的值? - 又怎么把我们查出来的每一组
username和uuid作为参数值去请求下一个接口?这里先说下,需要做一个循环。 - 我事先并不知道能查出多少条数据,那如何知道我们需要循环多少次?
2、实践
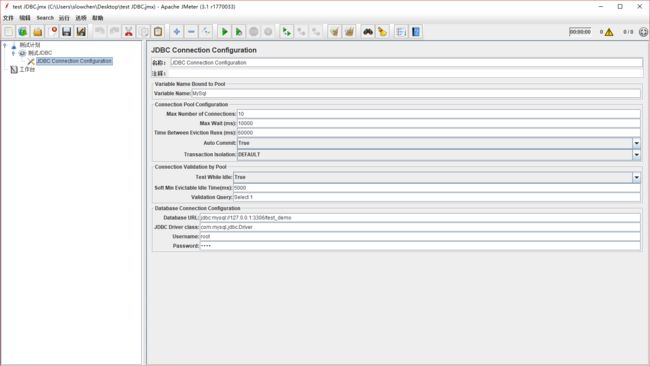
1). 首先添加一个jdbc connection configuration
这里的配置方法可以百度,我连接的是我本地的mysql 数据库
2). 添加 1 个或者 2 个 jdbc request,分别查询 username 和 uuid
我这里是用了两个
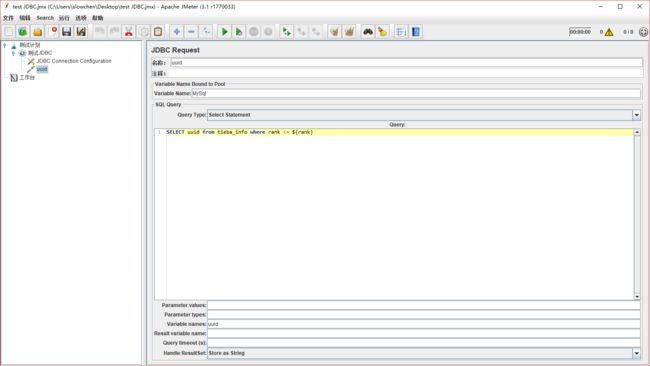
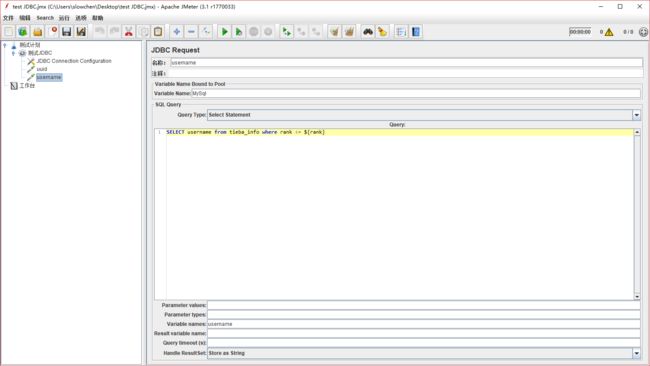
可以看到,在这 2 个请求中,select 语句中出现了变量rank,那我们可以
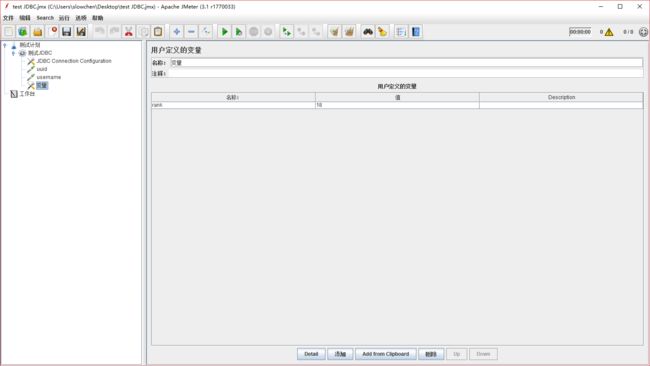
3). 添加一个【用户定义的变量】
名称就是我们的 sql 语句里面的变量引用名rank,值就根据需要自己填
sql 语句写完了,就要
4). 确认是否查询出数据
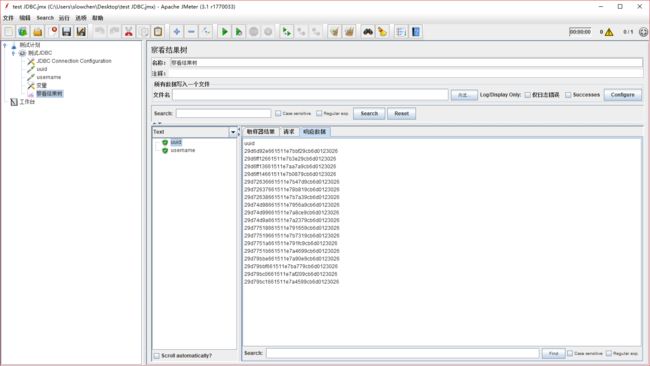
这个时候可以添加查看结果树,看看我们获取到的 uuid 和 username
uuid 查出来的数据如下图:
username 查询出来的数据如下
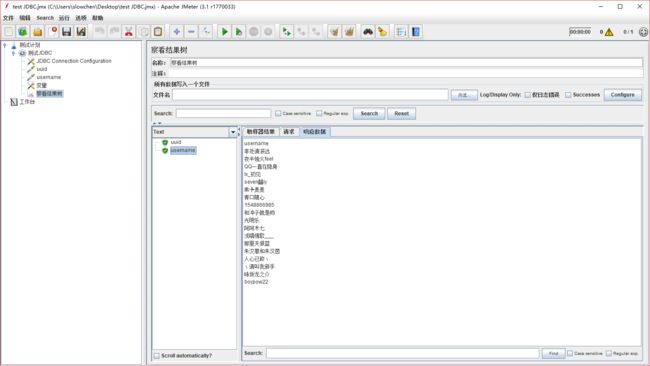
那我们需要的数据已经可以看到了,就是 uuid 和 username 下面的那些数据,他们是一一对应的
上面我们只是查出来数据,接下来我们就要
5). 提取username 和 uuid数据
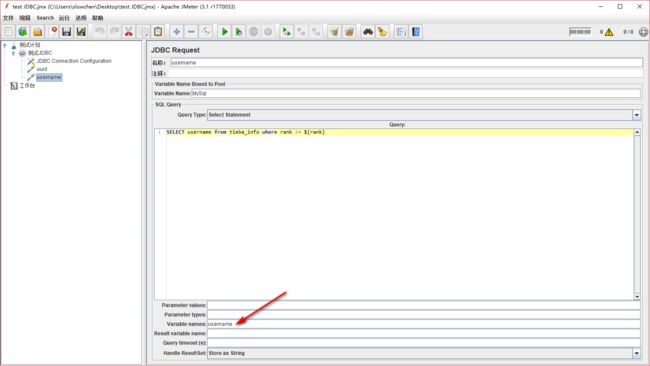
再回到我们的uuid 和username 两个jdbc request,在 username 这个request 里面,下方的 variable name 这里填上你想使用的变量名,也就是之后的接口中要用到的,我取的 username,同理,uuid 的 request 里也做相同操作,可以取为 uuid,如 3、4 两张图
6). 验证参数化是否成功
我模拟请求接口 localhost:3306/test,然后参数传 uuid 和 username,参数值分别是我们获取的 uuid 和 username,那根据变量的写法,我们可以写成下图所示。
注: ${变量名} 是
jmeter里面参数化的写法
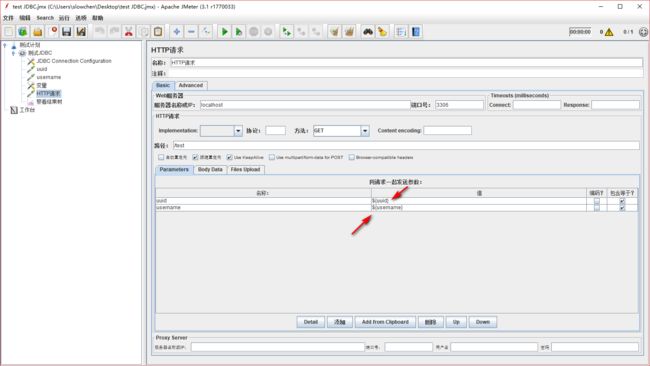
现在运行,然后查看下请求结果
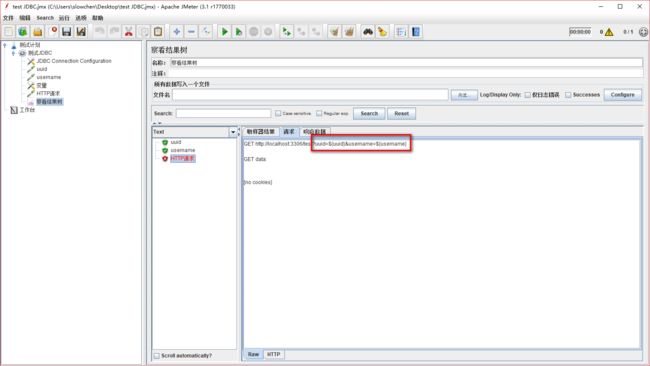
我发现请求里面 username 和 uuid 参数化并没有成功,那为什么会不成功呢,经过一番搜索,原来当使用 jdbc request 的结果作为参数时,要写成 ${username_0}这样子,username就是你的变量名,0 代表索引,索引是 0 就表示第一行,索引是 1 就表示第二行。
例如,我想取username查询结果第 4 行的数据,那我的变量值就需要写成 ${username_3},再看看上面 uuid和username 查询结果是怎么展示的
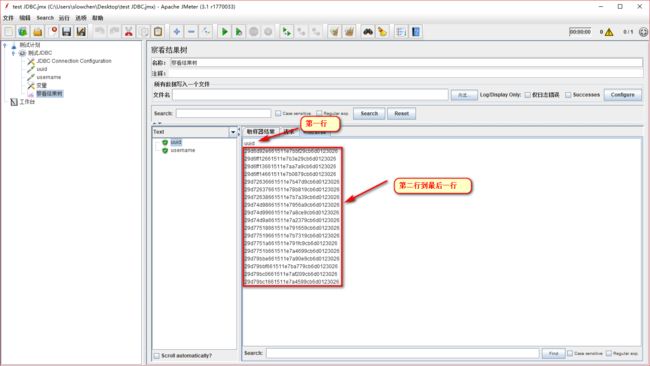
可以看到,查询出来的数据,第一行是一个标题,这个标题就是我们 sql 语句里面要查询的字段名,也就是说,我们在参数化的时候,第一行是不能取的,要从第二行开始取值,再回忆下,第一行的索引是 0,第二行的索引是 1,所以如果我们取第二行的uuid应该是${uuid_1},同理 username应该是 ${username_1}
那问题又来了,我们查出来的 username 和 uuid 有很多条,我是想所有的 username和uuid 都请求一次,也就是说 ${username_1}和 ${uuid_1}里面的 1 这个数字应该是要不断变化的而不是某个固定的值,那怎么才能让他不断变化呢
7). 添加计数器
对,就是计数器
我们添加一个计数器
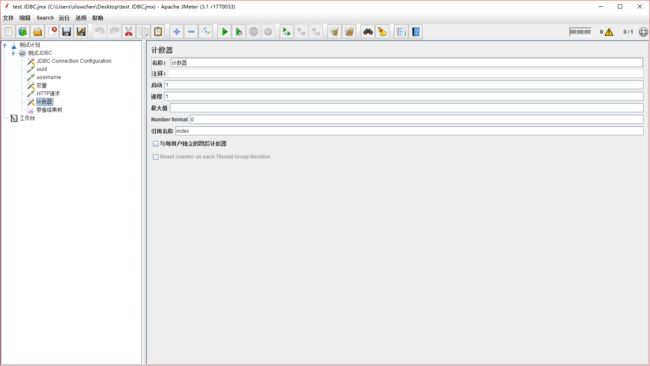
由于我们从第 2 行开始取值,索引是 1,所以启动填 1,每次我们往后多 1,所以递增也填 1,最大值可不填,number format 就是数字格式,如果填 000,取值是 12,那最后会显示为 012,而我们只需要本身的数字,所以就填 0,引用名称就是后面需要用的变量名
有了计数器,能递增了,那我们就需要
8). 把 username 和uuid传进去了
我们上面说了 ${username_1}是取第二行,${username_2}是取第三行,依次类推,那我们要从第二行也就是索引等于 1 开始取,一直到最后。上一步添加的计数器就起作用了,我们设置的计数器是从 1 开始计数,每次递增 1,那么跟我们想要的完全吻合,index 就是我们设置的计数器的变量名,可以直接用他来代替我们的索引 1,2,3,4 等等,那我们现在来把username 和index两个变量拼接起来,这里如果你直接写成 ${username_index} 或者 ${username_${index}}都是不行的,因为两个变量不能直接拼接,需要用到一个函数 __V,不了解这个函数的可以百度看看,作用就是可以使 2 个变量可以拼在一起,所以我们拼接后的 username 变量应该是 ${__V(username_${index})},同理 uuid的变量应该是 ${__V(uuid_${index})}
现在再来看看 我们请求接口有没有把所有的username传进去
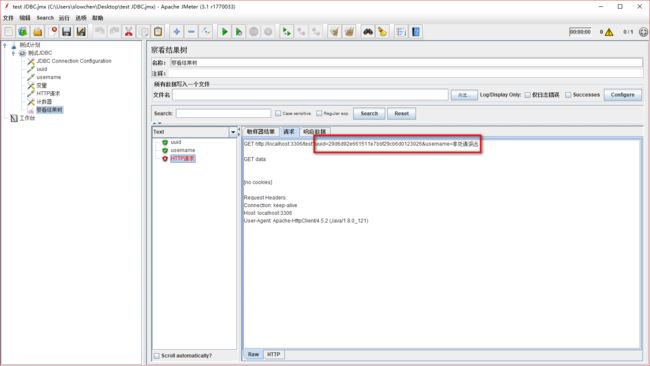
结果发现,参数化成功了,uuid 和username 的值与数据库一致,并且匹配成功。但为啥只请求了一次,明明符合条件的数据有很多,那应该请求多次啊,为啥只把第一组 username 和uuid传进去了呢?
这是因为,我们传的username和 uuid参数相当于做了参数化,有多个值,这时候就需要
9). 设置线程数或者添加一个循环控制器
但是我们并不知道到底需要循环多少次或者需要设置多少线程数,才能让username 和uuid刚好传完,这个时候,我们需要多加一个 jdbc request 了,来查询出我们符合条件的数据有多少条。SELECT count(*) from tieba_info where rank <= ${rank}就是查询符合条件的数据总数,同理我们在 variable names 填上一个变量名,以供后面使用,这里我取 count
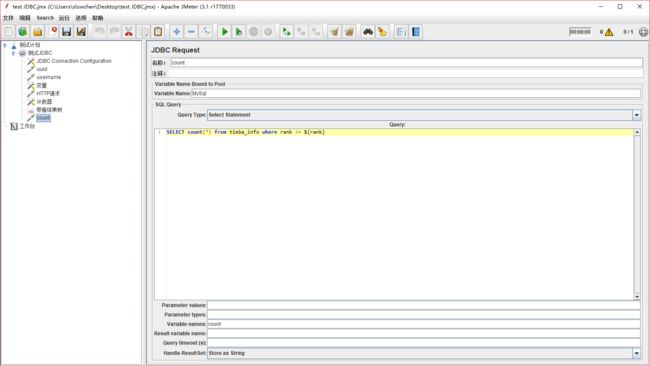
count 变量是我们之前查出来的所有数据的总数,这个总数是多少就说明我们需要多少线程或多少次循环。ok,那我们在 http 请求上右击,点击插入上级 -- 逻辑控制器 -- 循环控制器,循环次数,我们使用count 变量,由于 count变量查询出来的结果肯定只有一个,那我们可以直接取结果的第二行数据,索引是 1,即${count_1},这样就能把次数确定。这里其实不能用添加线程的方式来做,因为这几个 jdbc request 都在这个线程里,如果设置多线程,jdbc request 也会多次请求,不合理,所以我们选择更好的循环控制器。
10). 解决一个问题
在群里看到一个人有个需求,跟这个几乎一样,但是他是有两层循环,然后当外层循环到第二次后,内层循环里面的http请求参数化不成功,例如内层循环20次后,到第二次内层循环,此时uuid的参数值成了username_21,没有将查询出来的数据带过来。
经常好一番测试查找,原来是计数器设置的锅。在之前设置计数器的时候我们没有填写最大值,这样计数器就会从1一直往下技术,也就是我们${_V(username${index})}的index会一直取下去,但是我们查询出来的数据量count是有限的,当超过count后,${_V(username${index})}就取不到值了,所以直接显示成了username_21这样的。那么解决方案就是设置计数器的最大值,最大值应该等于我们查出来的数量count,即可以填写成${count_1}。
11). 把我们的东西进行重新排序归类
我们首先是有 jdbc connection config,然后有 uuid 和username 两个 jdbc request,然后我们有一个测试的 http 请求,一个计数器,一个 count的 jdbc request 和一个循环控制器,那么这时候就需要把计数器和 http 请求全部移入循环控制器了,让参数循环请求测试接口
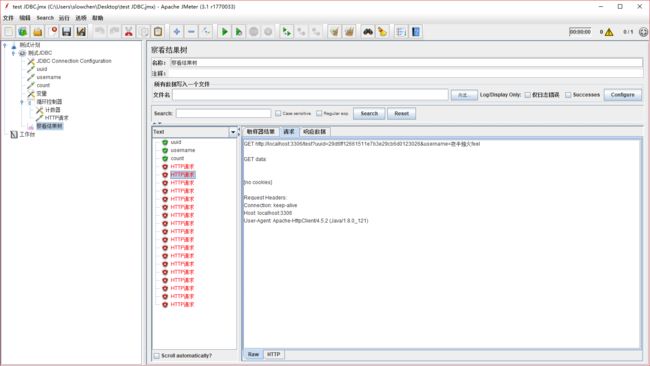
最后的效果如图,rank 变量值是 18,刚好 18 个 http 请求,每个请求的 username 和 uuid 都不同
四、最后成果
百度云: JMETER文件