You can find this article and source code at my GitHub
Testing
Two types of our problems

Think about a simple case... How well is my model doing with a regression problem?
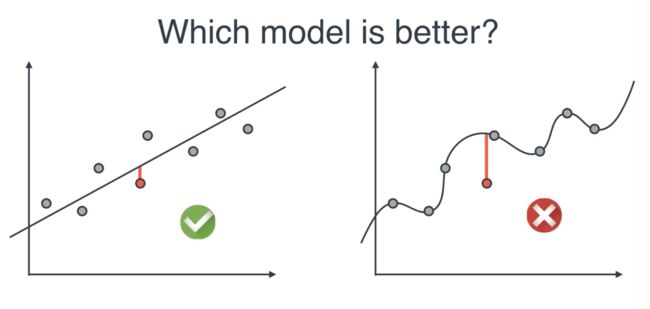
It seems that, though the line in the right graph fits better to the original data points. But if we add one more new data point for testing purpose, the left one works better since it's more generalized.
How do we measure the generalization?
For a regression problem...

For a classification problem...
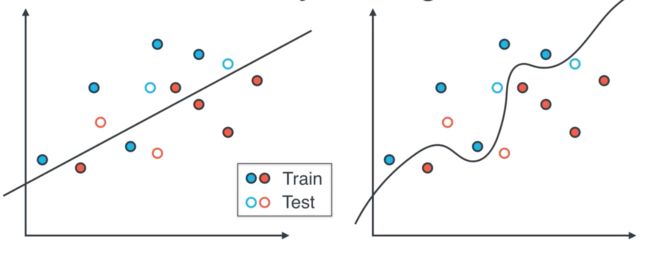
Notice that both models fit the training set well, but once we introduce the testing set, the model on the left makes less mistakes than the model on the right.
This issue can be handled easily in a Python package called "sklearn".
from sklearn.model_selection import train_test_split
X_train, y_train, X_test, y_test = train_test_split(X, y, test_size=0.25) # 25% total samples will be split into the test set
A golden rule is...
Never use your testing data for training purpose.
That is, never let your model know anything about your testing data. Your model should not learn anything from the testing data.
Evaluation
There is a metric for classification problems called "confusion matrix"


You can fill the blank by yourself to see whether you understand this metric correctly.
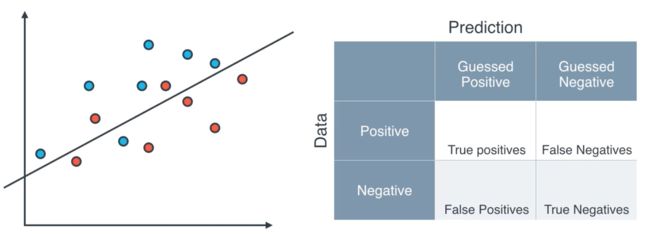
The answers are 6, 1, 2 and 5 for True Positives, False Negatives, False Positives, and True Negatives, respectively.
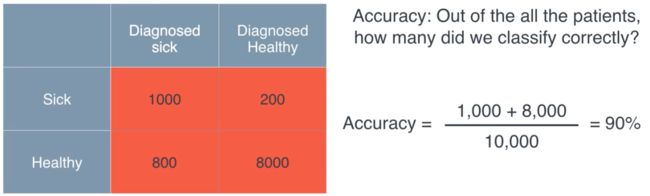
Accuracy
We have a very basic method to calculate the accuracy...
Again, "sklearn" can do this simply with several lines of code
from sklearn.metrics import accuracy_score
accuracy_score(y_true, y_predict)
Regression metrics
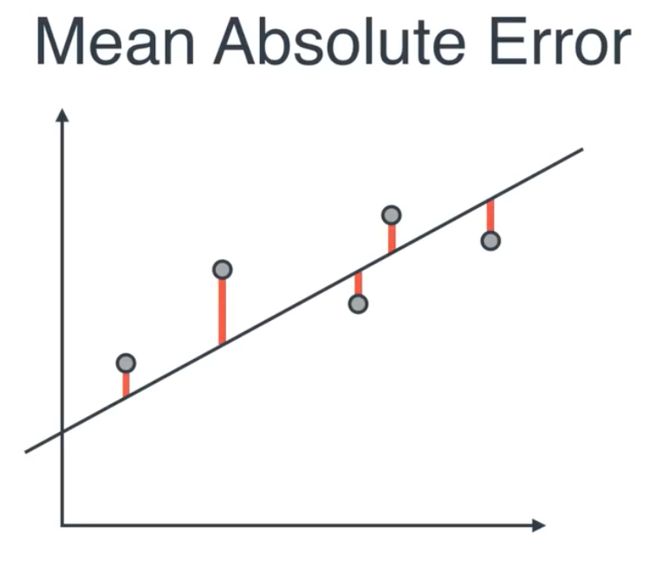
from sklearn.metrics import mean_absolute_error
from sklearn.linear_model import LinearRegression
classifier = LinearRegression()
classifier.fit(X_train, y_train)
guesses = classifier.predict(X_test)
error = mean_absolute_error(y_test, guesses)
But there is a problem with the mean absolute error (MAE) is that the formula of MAE is not differentiable, therefore it cannot be adopted to some common method we will use later such as the gradient descent.
An alternative method is the mean squared error (MSE).

from sklearn.metrics import mean_squared_error
from sklearn.linear_model import LinearRegression
classifier = LinearRegression()
classifier.fit(X_train, y_train)
guesses = classifier.predict(X_test)
error = mean_squared_error(y_test, guesses)
Another common metric we use here is the R2 score.
The formula is as below, and the error in the two figures is calculated with the MSE formula.
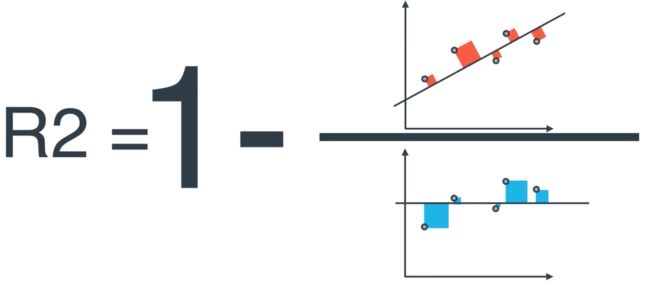
from sklearn.metric import r2_score
y_true = [1, 2, 3]
y_pred = [3, 2, 3]
r2_score(y_true, y_pred)
Type of Errors
Error due to bias (underfitting)
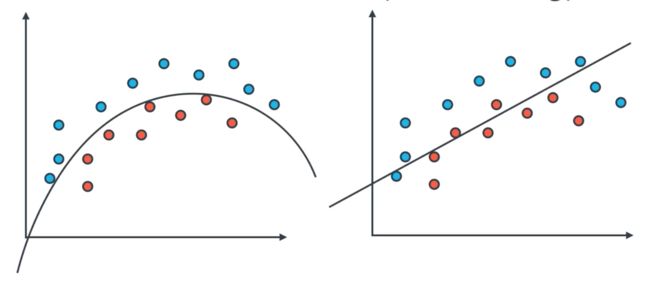
Error due to variance (overfitting)

There is the trade-off...

Model Complexity Graph
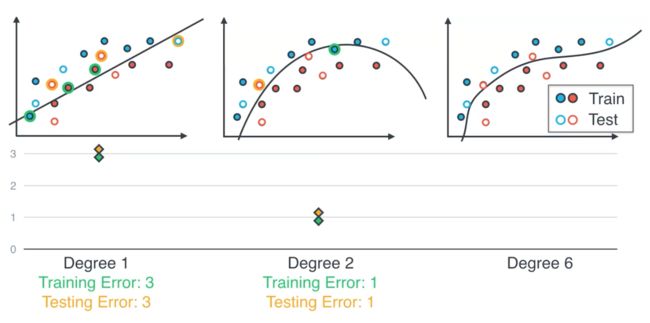
K-Fold Cross Validation
This is a very useful way to recycle our data...

With this algorithm, for example, in the above graph, we will go train our model 4 times with the different splitting result. And then we average the 4 results in order to find the final model.
"sklearn" is awesome!
from sklearn.model_selection import KFold
kf = KFold(12, 3)
for train_idx, test_idx in kf:
print(train_idx, test_idx)
If we want to "eliminate" possible bias, we can also add randomized selection in the K-Fold algorithm.

"sklearn" is awesome AGAIN!
from sklearn.model_selection import KFold
kf = KFold(12, 3, shuffle=True)
for train_idx, test_idx in kf:
print(train_idx, test_idx)
Thanks for reading. If you find any mistake / typo in this blog, please don't hesitate to let me know, you can reach me by email: jyang7[at]ualberta.ca