一、多核负载均衡
负载均衡这个概念是针对多核CPU而言的,希望达到的状态是各个核的调度情况尽量保持一致,不要使某一个核太忙也不能使某一个核太轻松,核与核之间相对均匀分配任务。而每个独立的核上的调度策略依然是使用SCHED_FIFO算法、SCHED_RR算法与SCHED_NORMAL算法。
不同进程如何做到负载均衡:
- RT进程
N个优先级最高的进程分不到N个不同的核,使用pull_rt_task与push_rt_task来达到负载均衡的效果。RT进程的话,实际上强调的是实时性而不是负载均衡。
- 普通进程
周期性负载均衡:所有的进程周期性的被各个核调度达到多个CPU的负载均衡。
IDLE时负载均衡:一旦跑了0号进程,说明整个系统处于一种低功耗的状态,这种状态下整个系统只有0号进程会跑,其他进程都在休眠。这里的负载均衡说的是只要其他核还在忙,当前核就会想办法去帮忙,而不是进入IDLE状态。
fork和exec时负载均衡:当创建一个新的进程或者替换了一个新进程,就会把这个新的task_struct推给一个最空闲的核去调度。
二、负载均衡限制
这里讲的是如何打破常规的负责均衡,主要有两个策略:
1)cpu task affinity
affinity的意思是亲和的意思,让task_struct对某一个或若干个CPU亲和。也就是让task_struct只在某几个核上跑,不去其他核上跑。
如何实现CPU task affinity?
- 代码API实现:
int pthread_attr_setaffinity_np(pthread_attr_t *, size_t, const cpu_set_t *);1
int pthread_attr_getaffinity_np(pthread_attr_t *, size_t, cpu_set_t *);
int sched_setaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask);
int sched_getaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask);
设置掩码来保证某一个线程对某几个核亲和,比如下方的0x6(110),就是设置线程只能在核2与核1上运行。
- taskset工具实现:
taskset -a -p 01 23421
注:这里01是掩码(0001)表示0核,02(0010)表示1核,03(0011)表示0核或者1核,以此类推。 23421是进程pid。-a 是所有线程。
2)cgroup
调度思想:进程分群,群与群之间CFS调度,群内部再CFS调度。这种分层思想能保证1000个线程的A程序与10个线程的B程序能相对公平地得到调度。如果仅仅只在线程间CFS,那么A程序得到调度的概率远大于B程序。
这里如何限制呢?
编译two-loops.c, gcc two-loops.c -pthread,运行三份
$ ./a.out &
$ ./a.out &
$ ./a.out &

用top观察CPU利用率,大概各自66%。
限制方法1:换cgroup
创建A,B两个cgroup:
/sys/fs/cgroup/cpu$ sudo mkdir A
/sys/fs/cgroup/cpu$ sudo mkdir B
把3个a.out中的2个加到A,1个加到B:
/sys/fs/cgroup/cpu/A$ sudo sh -c ‘echo 3407 > cgroup.procs’
/sys/fs/cgroup/cpu/A$ sudo sh -c ‘echo 3413 > cgroup.procs’
/sys/fs/cgroup/cpu/B$ sudo sh -c ‘echo 3410 > cgroup.procs’
这时发现3个a.out的CPU利用率大概是50%, 50%, 100%。
限制方法2:调整cgroup的权重
/sys/fs/cgroup/cpu/A$ sudo sh -c ‘echo 2048 > cpu.shares’
然后B的权重保持1024,那么3个a.out的CPU利用率大概又回到了各占60%多的样子。
限制方法3:限制一个cgroup在一个周期内最多跑多久。
cpu.cfs_quota_us:限制一个cgroup组在period时间周期内跑多长时间。
cpu.cfs_period_us:时间周期。
/sys/fs/cgroup/cpu/A$ cat cpu.cfs_period_us
100000
/sys/fs/cgroup/cpu/A$ sudo sh -c ‘echo 20000 > cpu.cfs_quota_us’
A这个group里面cfs进程100000us周期内,最多可以跑20000us,那么相当于CPU利用率为20%。若超过cpu.cfs_period_us,按N核*100 %算。
三、实时性
硬实时:任务从唤醒到调度,时间不超过某一个预定的截止期限,具有可预期性。
软实时:相比硬实时,被调度的时间允许超过那个截止期限,无法做到精确可控。
Linux就属于软实时系统。
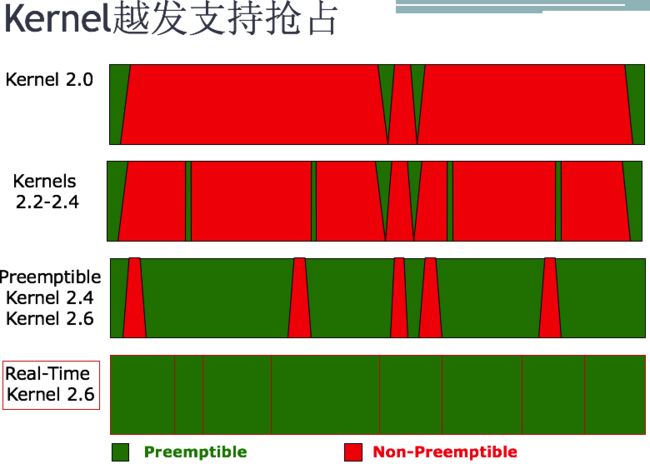
但是kernel随着版本的迭代,越发地往硬实时靠了。
Linux为什么不是硬实时的?
因为总结起来有3个不可抢占区间:
中断状态:当系统中有中断,CPU不能再调度任何其他进程,就算RT进程来了也一样得等着中断结束后的一瞬间才能抢占CPU。而且在中断中,不能再进行中断,也就是说,中断必须结束才能干其他事。中断是必须要被处理的。软中断状态:软中断中可以被中断。但是软中断中如果唤醒一个RT进程,此RT进程也不会被调度。进程处于spin_lock(自旋锁)状态:自旋锁是发生在两个核之间的。当某一个核如CPU0上的进程获取spin_lock后,该核的调度器将被关闭。如果另一个核如CPU1的进程task_struct1此时想要获取spin_lock,那么task_struct1将自旋。自旋的意思就是不停的来查看是否spin_lock被解锁,不停的占用CPU直到可以获取spin_lock为止。所以进程如果处于spin_lock,那么其他任何进程不会被调度。
实例说明:
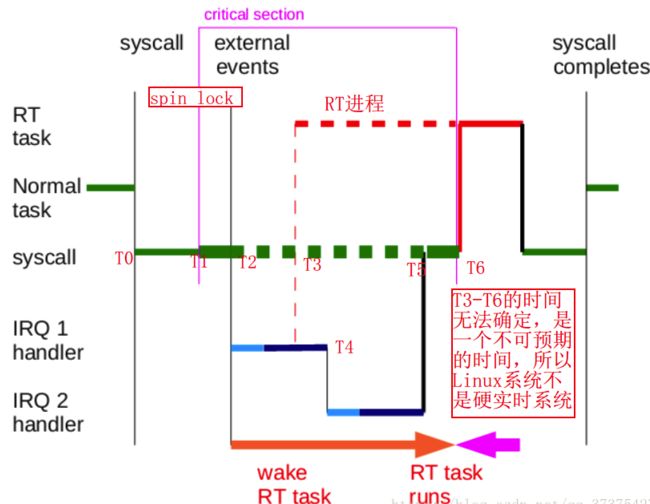
运行分析:
- T0时刻:假设有一个系统调用陷入到内核中。此时在跑的是一个普通进程(Normal task)。
- T1时刻:该Normal task获取了一个spin_lock。
- T2时刻:突然来了一个中断IRQ1,则系统执行中断处理函数IRQ1 handle,在中断处理函数中又调用软中断(Soft IRQ)。
- T3时刻:在软中断中唤醒了一个RT进程。此时由于系统处于软中断状态,所以RT进程无法抢占CPU(红色虚线部分为无法抢占CPU)。
- T4时刻:又来了一个中断IRQ2(说明软中断中可以中断),然后系统执行中断处理函数IRQ2 handler,然后执行软中断处理函数。
- T5时刻:中断与软中断执行完毕。但是由于此时Normal task还处于spin_lock状态,所以之前被唤醒的RT进程还是依然无法占用CPU。
- T6时刻:Normal task释放了spin_lock的一瞬间,RT进程抢占了CPU。当RT进程执行完,才会把CPU还给最开始还没有执行完的Normal task。Normal task执行完后,退出内核的系统调用。
RT在T3时刻被唤醒,因为中断、软中断、自旋锁的影响,直到T6才得到调度,因此T3-T6这个阶段是不可控的,根据硬实时的概念知,Linux系统不是硬实时的。
参考:
宋宝华Linux的进程、线程以及调度
《 Linux内核设计与实现》