前几天,群里有人开车。发现了github上有人写了一个mac版本的种子搜索器。闲来无聊,改成手机版的。
贴上地址:https://github.com/dongqihouse/AE86.git
预览:

思路
首先 讲下这个种子搜索器的思路,其实对开发的童鞋来说很简单,几乎是手到擒来。
首先我们打开一个种子搜索网站
举例-》 种子搜:
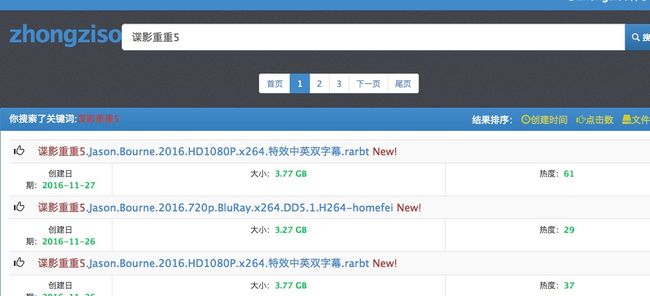
之后查看源代码:

之后我们发现磁力链 在源文件就能看得到。
了解了这些东西之后,事情就变得简单多了。
1 获取请求页面的html代码
2 解析里面的数据,抽取我们想要的数据
第一步这个很简单直接网络请求下来就行,第二部用的是Xpath来接节点的上所需要的信息截取出来
这边贴一下Xpath的基本语法
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有子节点。 |
| / | 从根节点选取。 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点。 |
| .. | 选取当前节点的父节点。 |
| @ | 选取属性。 |
之后根据源文件的写法,给出Xpath
"magnet":".//a//@href",
"name":".//tbody//a",
"size":".//tbody//tr//td[2]//strong",
"count":".//tbody//tr//td[1]//strong",
之后就能得到我们想要的一些比如磁力链 影片名字 等等
具体实现
这边使用的三方开源库
target 'AE86' do
# Comment the next line if you're not using Swift and don't want to use dynamic frameworks
use_frameworks!
pod 'Alamofire', '~> 4.0'
pod 'Ono'
pod 'SwiftyJSON'
pod 'PKHUD', '~> 4.0'
# Pods for AE86
end
Alamofire HUD 以及SwiftyJSON 不用说,这个Ono就是一个解析的框架。
我们从上面的预览看出,其实就一个界面很简单。几乎没有什么代码。
上面一个searchBar 下面一个tableView
UI上没有好说的。
主要在数据处理上说一下
首先我们将要抓取网站以及Xpath写在json文件中
[
{
"site":"AOYOSO",
"waiting":"0",
"group":"//div[@class='col-md-8']//div[@class='panel panel-default']",
"magnet":".//a//@href",
"name":".//a",
"size":".//table//tr//td[2]",
"count":".//table//tr//td[1]",
"source":"http://www.aoyoso.com/search/XXX_ctime_1.html"
},
{
"site":"BT云搜",
"waiting":"0",
"group":"//li[@class='media']",
"magnet":".//a//@href",
"name":".//a",
"size":".//div[@class='media-more']//span[2]",
"count":".//div[@class='media-more']//span[1]",
"source":"http://www.btyunsou.com/search/XXX_ctime_1.html"
},
{
"site":"种子搜",
"waiting":"0",
"group":"//table[@class='table table-bordered table-striped']",
"magnet":".//a//@href",
"name":".//tbody//a",
"size":".//tbody//tr//td[2]//strong",
"count":".//tbody//tr//td[1]//strong",
"source":"http://www.zhongziso.com/list/XXX/1"
}
]
之后需要同时请求多个网站,
这边可以利用dispatch的group enter以及leave配合Alamofire同时异步请求,请求完成之后刷新数据
PKHUD.sharedHUD.contentView = PKHUDProgressView(title: "高速飘漂移中---", subtitle: "")
PKHUD.sharedHUD.show()
for site in sites {
let urlStr = site.source?.replacingOccurrences(of: "XXX", with: keyWord)
let url = urlStr?.addingPercentEncoding(withAllowedCharacters: CharacterSet.urlFragmentAllowed)
group.enter()
SearchHelper.searchMoive(urlStr: url!, site: site, success: { array in
self.movies.append(array as! [MovieModel])
group.leave()
})
}
group.notify(queue: DispatchQueue.main) {
PKHUD.sharedHUD.hide()
self.tableView.reloadData()
}
这边吐槽一下 3.0以后好多API都大变样无语死了,尤其下面对string的处理 无语
之后重点就是请求下来数据处理的过程拉
首先
获取所有的元素节点
let doc = try ONOXMLDocument(data: response.data)
doc.enumerateElements(withXPath: site.group, using: { (element, idx, stop) in
let model = MovieModel.entity(element: element!, site: site)
model.source = urlStr
array.append(model)
})
之后利用我们在json中写好的Xpath
var firstMagent = element.firstChild(withXPath: site.magnet).stringValue()
if firstMagent!.hasSuffix(".html") {
firstMagent = firstMagent!.replacingOccurrences(of: ".html", with: "" )
}
if firstMagent!.components(separatedBy: "&").count > 1 {
firstMagent = firstMagent?.components(separatedBy: "&")[0]
}
let i = firstMagent!.index(firstMagent!.endIndex, offsetBy: -40)
let magent = firstMagent?.substring(from: i)
movie.magnet = String(format: "magnet:?xt=urn:btih:%@", magent!)
movie.name = element.firstChild(withXPath: site.name).stringValue()
movie.size = element.firstChild(withXPath: site.size).stringValue()
movie.count = element.firstChild(withXPath: site.count).stringValue()
movie.sourceName = site.site
来获取到model
接下来就是展示拉
开车楼,不过手机版的迅雷好像被下架了。不知道老司机们还有没有别的车
参照项目:mac版种子搜索器 https://github.com/youusername/magnetX