HyPer也是内存数据库
传统数据库基本都是TP,后续出现BI的需求,即AP的需求,传统数据库满足不了
所以出现了数仓,但是需要ETL把TP的数据同步到数仓中,进行AP
哪怕基于列存的实时数仓,也要针对Tp和AP用不同的存储引擎
总之如果要用一套数据结构和系统同时支持TP和AP,之前是没有能做到的

Hyper说,如果用基于内存的数据库架构,就可以做到
可以看到虽然都是在做内存数据库,但是针对的问题是不一样的,比如Hekaton,目的是要让TP快100倍
他们的共同点,是都认为,以当前硬件的发展,应用的核心数据已经完全是可以在内存里面放下了,paper还以Amazon为例算了一下
这里提到另外一个内存数据库, H-store,是MIT的石破天搞的,商业化后,叫做VoltDB
但是VoltDB也是主要针对TP的

架构
首先Hyper的目的,就是让TP和AP都可以跑在一个内存数据库中
可以通过配置,是行存还是列存
只是用主存,而没有使用虚拟内存,因为OS swap会让性能变的很差

首先,TP
TP写入使用单线程,这样就没有并发和锁的问题,果然解决问题的最佳方式,是消灭问题。。。
为什么能用单线程了?因为内存数据库,不像磁盘数据库,瓶颈在IO,所以一定要用多线程去等IO,内存数据库的瓶颈在CPU,那多开线程就是无谓的消耗了
而且内存数据库非常快,一个tp请求10微妙,就算单线程也足够了
立马就有个问题,怎么利用多核?作者也想到了,后面会说

AP

如何能满足TP的同时,不阻塞AP了,如何解决读写锁的问题
一般的思路就是snapshot,这里也是这个思路,实现比较骚,直接用系统Fork,Fork出来的子进程会保留和父进程相同的地址空间,这样就做到了读写分离
这个就是这篇paper的核心的创新,只有一层窗户纸
fork只能在事务之间做,不能在事务中做,否则事务做了一半,后面无法根据snapshot用Redo恢复
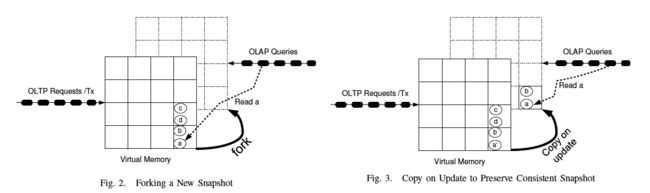
OS这里会有lazy的copy-on-update,更新只会影响到TP的数据

那怎么利用多核CPU?
先看AP,我可以开多个snapshot啊,这样不就是可以同时查多个version
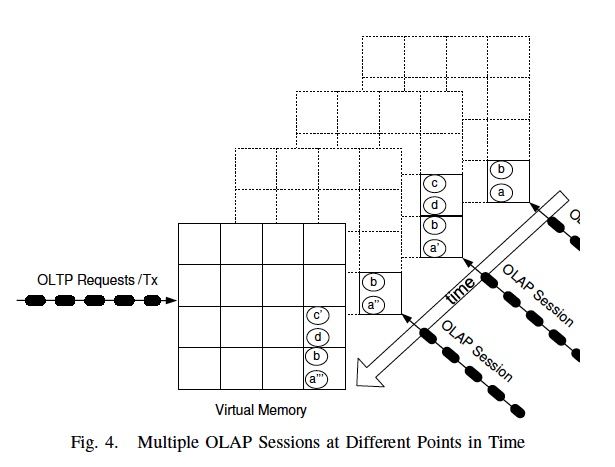
TP怎么办?
对于read-only的事务可以并发,利用多核

那写事务了?
数据库的数据一般都是可以分partition的,所以对于每个partition的并发是不用加锁的
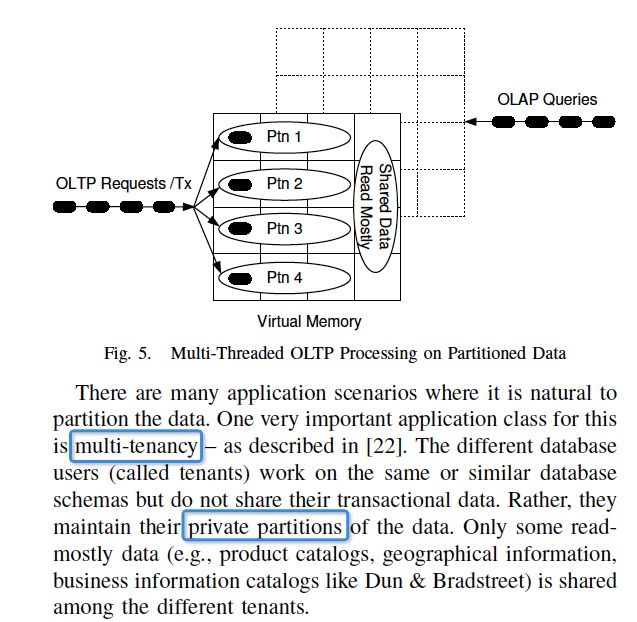
如果要跨partition了?那只能用锁了

可见用单线程的限制还是很强的,虽然这里各种论证合理性,还是不是那么confidence
Transaction Semantics And Recovery
这里事务隔离,主要是通过SI来实现
那么SI的实现方式,主要有底下几种,
Roll-back,如果需要读老版本,通过undo roll back回去,Oracle这样做的,这个明显成本很高
Versioning,MVCC,主流做法
Shadowing,意思就是写入先写到一个shadow版本,在Transaction提交的时候,再把shadow install回DB,这个方法在乐观并发控制,occ算法就是这么做的;这样就不需要undo,因为如果roll back,直接把shadow丢掉即可
VM Snapshot,这个就是Hyper用的,
这里的总结很不错


还要重点看下的是Durability
内存数据库,最关键的是,机器crash,数据怎么恢复出来
依赖Redo,而且这里是逻辑的Redo,一般数据库Redo都是物理的,因为逻辑Redo在事务执行一半的时候,你不知道该怎么恢复,比如Redo,a+1,事务执行一半,你不知道是否加过1
这里之所以可以用逻辑Redo,因为定期的snapshot的presist,而snapshot一定是事务完成的状态,所以不会有这个问题

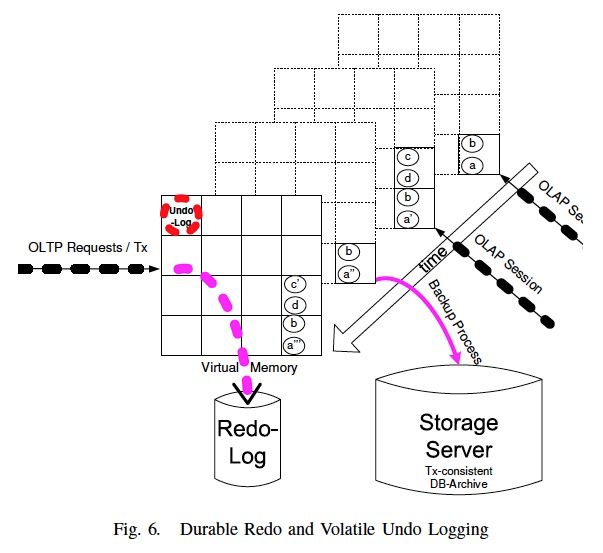
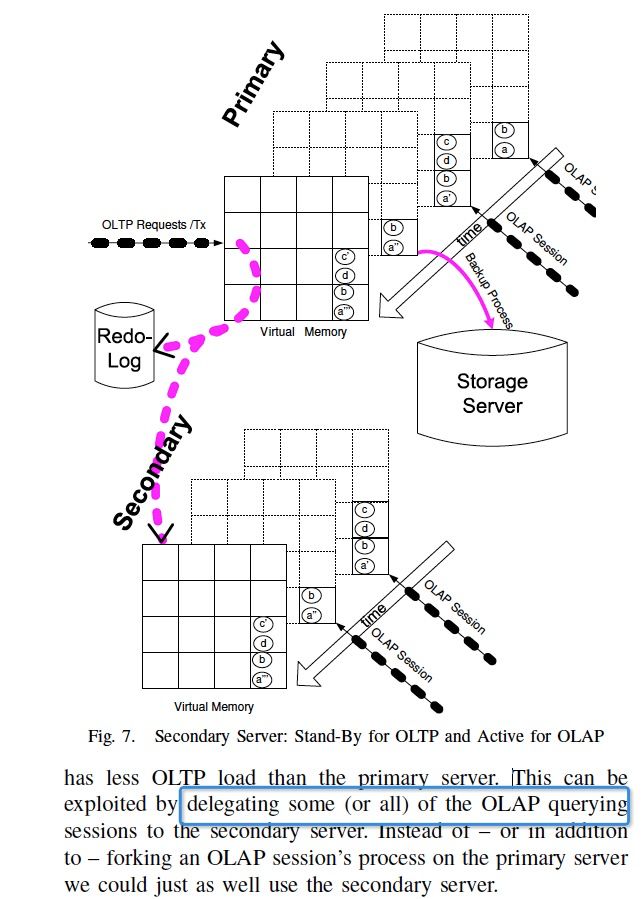
如何保证高可用性?
通过一个standby节点,standby节点直接通过redo日志来回放
我们也可以把所有的AP放到standby上去做,分担主的压力

加入Redo机制,难免会拖累性能
对于logging的优化,也就两种方法,
Group,多个Transaction一起提交,这样会加大client的等待时间
Async,不等log flush到磁盘,当log写入buffer时候就直接commit,会丢数据
好像很难两全


上面有一个点,undo日志是只保留在内存中的,
因为对于Hyper数据恢复的时候,不需要undo,通过snapshot,加上Redo就一定可以恢复,因为不存在事务执行到一半的情况
所以这里undo只是对于正在执行的Transaction保留在内存中,便于执行一半的事务roll back
