题目
Deep Video Super-Resolution Network Using Dynamic Upsampling Filters Without Explicit Motion Compensation
摘要
近年来,视频超分辨率(VSR)是对于为超高清显示提供高分辨率(HR)内容的越来越重要。但是已经提出的许多基于深度学习的VSR方法,其中大部分都严重依赖于运动估计和补偿的精度。在本文中,我们为VSR介绍了一个完全不同的框架。我们提出了一种新的端到端深度神经网络,用于生成动态上采样滤波器和残差图像,这些滤波器和残差图像是根据每个像素的局部时空邻域来计算的,以避免显式运动补偿。该方法使用动态上采样滤波器对输入图像进行直接重构,并通过计算残差增加细节。我们的网络借助一种新的数据增强技术,可以生成具有时间一致性的更清晰的HR视频。我们还通过大量的实验对我们的网络进行分析,以显示网络如何隐式地处理运动。
介绍
超分辨率(SR)的目标是从相应的低分辨率(LR)图像或视频中生成高分辨率(HR)图像或视频。SR广泛用于从医学成像到卫星成像和监视的许多领域。随着显示技术的进步,LR视频的视频超分辨率(VSR)作为超高清晰度电视的4K(3840×2160)和8K(7680×4320)目标显得越来越重要,但与之相匹配的内容仍然很少。
随着计算机视觉中的深度学习在图像分类和图像分割中的成功,出现了基于深度学习的单图像超分辨率(SISR)方法。这些方法在峰值信噪比(PSNR)和结构相似性指数(SSIM)方面显示了最新的性能。
执行VSR的一种简单方法是逐帧运行SISR。然而,由于SISR方法没有考虑帧之间的时间关系,因此很有可能连续的帧并不是自然连接的,从而导致闪烁的伪影。
传统的VSR(或多图像超分辨率)算法通过考虑相邻LR帧之间的亚像素运动输入多个LR帧和输出HR帧。所有基于深层学习的VSR方法都遵循相似的步骤,并且由两个步骤组成:运动估计和补偿过程,然后是上采样过程。这种两步法的一个问题是结果严重依赖于精确的运动估计。这种类型的方法的另一个潜在问题是HR输出帧是产生的。
这种方式的另一个潜在问题是,HR输出帧是通过卷积神经网络(CNN)混合来自多重运动补偿输入LR帧的值而产生的,这可导致输出HR帧的模糊。
在本文中,我们提出了一种新型的端到端深层神经网络,它与以往的方法有着本质的不同。运动信息被隐式地用于生成动态上采样滤波器,而不是对输入帧之间的运动进行显式计算和补偿。利用生成的上采样滤波器,HR帧直接通过到输入中心帧的局部滤波来构造(图2)。由于我们不依赖于运动的显式计算,也不直接组合来自多重帧的值,因此我们可以生成更清晰和时间一致的HR视频。

使用大量的训练视频和一个新的数据增强过程,我们实现了与以往的基于深度学习的VSR算法相比的最新性能。图1显示了一个示例,与最先进的方法之一VSRnet[16]相比,我们的方法产生更锐利的帧且更少的闪烁。
相关工作
方法
VSR的目标是从给定的LR帧 {Xt} 估计HR帧 {Ŷt} 。LR帧{Xt} 从相应的GT帧 {Yt} 下采样,其中t表示时间步长。提出的VSR网络G和网络参数θ,VSR的问题被定义为
N是时间半径。G的一个输入张量的形状是,其中,H 和W是输入LR帧的高和宽,C是色彩通道的数量。对应输出张量形状是,其中 r是放大因子。
如图3所示,我们的网络从一组输入LR帧 { } 产生两个输出生成最终的HR 帧Ŷt:动态upsampling过滤器和残差。输入中心帧首先经过动态上采样upsampling过滤器的局部滤波,然后残差添加为最终的输出结果添加上采样的upsampled。

动态上采样滤波器 Dynamic Upsampling Filters
传统的双线性bilinear或双三次bicubic上采样的滤波核基本上是固定的,唯一的变化是滤波核根据上采样图像中新创建的像素的位置而移动。对于 X4 upsampling,传统的upsampling过程使用一系列16个固定的滤波核kernel。它们速度快,但很难恢复锐化和纹理区域。
与此相反,我们受动态滤波器网络 (DFN) 的灵感启发,提出使用动态上采样滤波器。上采样滤波器是根据LR帧中每个像素的时空邻域进行局部动态生成的。
VSR动态上采样过程的概述如上图2所示。首先,将一组输入LR帧{ } (在我们网络中的7帧:N = 3) 送入动态滤波器生成网络。训练网络输出一组 确定大小(在我们的网络是55)的上采样upsampling过滤器,将用于生成经过滤波器的HR 帧的新的像素。最后,对输入帧中的LR像素进行局部滤波,得到每个输出HR像素值,对应的滤波器如下:
其中,x,y是LR是栅格的坐标,v和u是每个 输出块的坐标 (0 ≤ v, u ≤r − 1),注意,这种操作类似于反卷积(或转置卷积),因此我们的网络可以进行端到端训练,因为它允许反向传播。
我们的方法与以往的基于深度学习的SR方法有本质的区别,深度神经网络学习在特征空间中通过一系列的卷积来重构HR帧。相反,我们使用深层神经网络来学习最好的上采样滤波器,然后用它直接从给定的LR帧重建HR帧。从概念上讲,动态滤波器是根据像素的运动来创建的,因为这些滤波器是通过观察像素的时空邻域来生成的,这使我们能够避免显式的运动补偿。
残差学习 Residual Learning
单独应用动态上采样滤波器后的结果缺乏清晰度(图像锐利的细节),因为它仍然是输入像素的加权和。通过线性滤波可能有不可恢复的细节。为了解决这个问题,我们另外预测残留图像以增加高频细节。在[17 ]中,将残差添加到双三次上采样基准以产生最终输出。我们的方法不同与[17]不同,因为残差图像是由多个输入帧而不是单个输入帧构成的,并且我们使用动态上采样帧作为更好的基准,然后加上计算的残差。通过组合这些互补组件,我们能够在得到的HR帧中实现空间清晰度和时间一致性。
[17] J. Kim, J. Kwon Lee, and K. Mu Lee. Accurate image super-
resolution using very deep convolutional networks. In CVPR,
pages 1646–1654, 2016.
网络设计 Network Design
如图3所示,我们的滤波器和残差生成网络被设计成共享大部分权重,因此我们可以减少产生两个不同输出所带来的开销。我们网络的共享部分是受稠密块dense block [10]的启发而设计的,并且它被适当地修改以解决我们的问题。特别地,我们用3D卷积层代替2D卷积层,以从视频数据中学习时空特征。已知3D卷积层比2D卷积层更适合于人类动作识别和视频数据的一般时空特征提取。稠密块dense block的每个部分依次由批量归一化(BN)[12]、ReLU[5]、1×1×1卷积、BN、ReLU和3×3×3卷积组成。正如在[10 ]中所做的那样,每个部分都把前面所有的特征映射作为输入。
[5] X. Glorot, A. Bordes, and Y. Bengio. Deep sparse rectifier neural networks. In AISTATS, 2011.
[10] G. Huang, Z. Liu, L. van der Maaten, and K. Q. Weinberger. Densely connected convolutional networks. In CVPR, 2017.
[12] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
每个输入LR帧首先由一个共享的二维卷积层处理,并沿时间轴连接。产生的时空特征图经过我们的3D 稠密块dense block,然后在由几个2D卷积层组成的独立分支上进行处理,生成两个输出。过滤输出添加生成的残余,产生最终的输出。
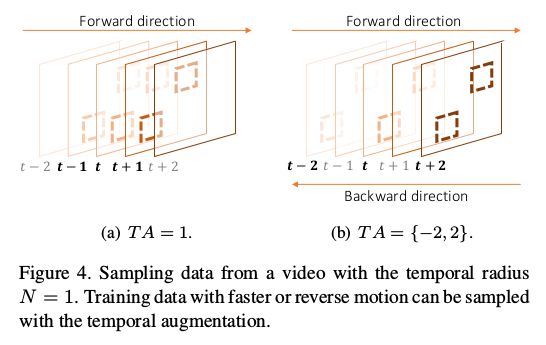
时间累加 Temporal Augmentation
为了使提出的网络能够充分理解各种复杂的真实世界运动,我们需要相应的训练数据。为了创建这样的训练数据,我们在一般数据扩充(如随机旋转和翻转)之上,在时间轴上采用数据扩充。这里,我们引入变量T A,它决定了时间增强的采样间隔。例如,T a=2,我们将对每间隔一帧进行采样,以模拟更快的运动。当我们将T A值设置为负值时,我们还可以按照相反的顺序创建一个新的视频样本(图4)。使用各种大小的T A(在我们的工作中从-3到3),我们可以创建具有丰富移动性的训练数据。注意,在|T A|>3的情况下,VSR性能会随着对象的位移太大而降低。
实施 Implementation
实验结果 Experimental Results
学习运动可视化 Visualization of Learned Motion
综合运动试验 为了验证提出的方法在不进行显式运动补偿的情况下,能够很好地合理利用给定视频的时域信息,合成在GT帧中每帧垂直条左右移动1个像素的视频。对于同一个输入块patch,因为每个条有不同的运动,两个视频的激活映射应该是不同的。但是生成的HR帧是相同的,所以上采样过滤器应该是相同的。在图5中(a),我们把激活第一个3×3×3的地图卷积层和生成的动态过滤器为不同的两个区域。根据预测,在相同的输入块中,我们的学习网络对不同的运动表现出不同的激活,生成的动态滤波器的权值几乎相同。
我们还在图5(b)中绘制了带点的橙色水平扫描线随时间的过渡图,以查看时间一致性是否得到很好的保护。由于VDSR[17]不考虑时间信息,所以结果是不稳定的。VSRnet[16]的重构条也呈现锯齿状伪影,在播放视频时都会产生严重的闪烁伪影。相比之下,我们的结果看起来更清晰,显示了维持时间一致性的能力,并且更接近于真值ground truth。我们建议读者阅读我们的补充视频,以便更好地进行比较。

学习过滤器 查看学习过的过滤器,是另一种检查我们的方法能否学习和使用时间信息的方法。为此,本方法在3×3×3卷积层中的学习滤波器应该从前后以及输入到时间轴的中心提取一些值。我们可以看到,由于滤波器在时间步长t_1和t+1以及图6所示的t上具有更高的权重,因此我们的网络能够以各种结构从前后以及输入到时间轴的中心均匀地提取一些值。这表明我们的方法可以隐式地学习和使用输入帧之间的时间信息来生成精确的输出帧。

动态上采样过滤器 生成的上采样滤波器应该针对不同的区域具有不同的权重,以自适应地处理局部运动。图7详细显示了场景日历的两个不同区域的建议的上采样过程的示例,并且每个新创建的像素位置的滤波器权重是不同的。对于具有不同纹理和运动方向的两个输入块,我们的方法自适应地生成上采样滤波器用于精确的输出重建。

与其他方法的比较
通过我们由16层(Ours-16L)组成的基本网络,还测试了28层(Ours-28L)和52层(Ours-52L)的网络。和大多数超分辨率方法一样,具有细线条的场景非常具有挑战性,如图8所示。使用我们的算法,增加层数为这种类型的挑战性场景提供更好的结果。

定量评价 与其他最先进的VSR方法的定量比较显示在表1中。结果表明,随着网络深度的增加,网络性能有改善的趋势,在附加参数为0.2M的情况下,Ours-28L的PSNR值比Ours-16L提高了0.18dB。即使叠加52层,我们的方法也能很好地工作,并且Vid4的PSNR值提高到27.34dB,比我们的-16L高0.53dB。即使使用我们的-16L,我们在PSNR和SSIM方面对所有高档生产商都比其他所有方法表现得好。例如,OURS16L的PSNR比第二最高结果(34)(r=4)高0.8dB。
定性比较 在图9中示出了一些定性示例。使用我们的方法更好地重建精细的细节和纹理。在图10中,我们还将[34]的结果与使用不同深度的网络的结果进行比较。我们的性能优于前面的工作,并且还可以更深入地观察性能的提高。在图11中示出了与VID4上其他最先进的VSR方法的更定性的比较。我们的研究结果表明,与其他作品相比,输出更流畅,时间更平稳。在X-T图像中锋利而平滑的边缘表明视频的抖动要小得多。
[34] X. Tao, H. Gao, R. Liao, J. Wang, and J. Jia. Detail-revealing deep video super-resolution. In ICCV, 2017.


结论
本文提出了一种新的基于深度学习的VSR框架,用于同时学习输出动态上采样滤波器和残差。我们用新的框架实现了最先进的性能,恢复了清晰的HR帧,并保持了时间上的一致性。通过实验,我们证明了我们的深层网络可以隐式地处理运动,而不需要显式的运动估计和补偿。
使用NVidia GeForce GTX 1080Ti,对Ours-16L、Ours-28L和Ours-52L分别进行0.4030s、0.8382s和2.8189s的7个输入帧的480×270,生成单个1920×1080输出帧需要训练2天。在我们的推理过程中,大约一半的运行时间花在局部过滤上。将来,我们将致力于加速实现实时性能的方法。我们还想扩展我们的工作,以增加时间分辨率除了空间分辨率,例如,创建一个60fps超高清视频从30fps的SD视频。