-
1 scrapy startproject doupan
 屏幕快照 2017-11-15 14.59.40.png
屏幕快照 2017-11-15 14.59.40.png-
1.1进入项目,在里面我们能看到有以下文件
 屏幕快照 2017-11-15 15.01.11.png
屏幕快照 2017-11-15 15.01.11.png
-
- 2 我们可以用pycharm打开项目,在items.py中定义想要爬取的字段,这里图省事,我就爬取了标题名
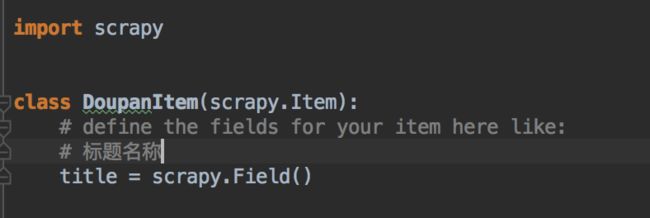 屏幕快照 2017-11-15 15.03.44.png
屏幕快照 2017-11-15 15.03.44.png -
3 进入之前1.1中的spiders文件下,创建自己的爬虫类
-
3.1 可以手动在目录下直接创建
 屏幕快照 2017-11-15 15.05.08.png
屏幕快照 2017-11-15 15.05.08.png 3.2 可以用终端进入当前目录用命令创建模板,1和2两种都可以
1:scrapy genspider moviedouban “movie.douban.com”
2:scrapy genspider -t crawl moviedouban movie.douban.com3.3打开moviedouban文件,在此写自己的爬虫
-
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from douban.items import DoubanItem
class MoviedoubanSpider(CrawlSpider):
name = 'doubanmovie'
allowed_domains = ['movie.douban.com']
start_urls = ['https://movie.douban.com/top250?start=0']
pagelink = LinkExtractor(allow=r'start=\d+')
rules = (
Rule(pagelink, callback='parse_item', follow=True),
)
def parse_item(self, response):
item = DoubanItem()
movies = response.xpath("//div[@class='info']")
for each in movies:
# 标题
item['title'] = each.xpath(".//span[@class='title'][1]/text()").extract()[0]
yield item
- 4 这个时候要写管道文件
import json
import codecs
class DoupanPipeline(object):
def __init__(self):
self.filename = codecs.open("donggguan.json", "w", encoding="utf-8")
def process_item(self, item, spider):
text = json.dumps(dict(item), ensure_ascii=False) + ",\n"
self.filename.write(text)
return item
def close_spider(self, spider):
self.filename.close()
- 5 在写setting文件
延迟访问
DOWNLOAD_DELAY = 2.5
禁用COOKIES
COOKIES_ENABLED = False
MONGODB 主机名
MONGODB_HOST = "127.0.0.1"
MONGODB 端口号
MONGODB_PORT = 27017
SPIDER_MIDDLEWARES = {
'douban.middlewares.RandomUserAgent': 100,
'douban.middlewares.RandomProxy': 200,
}
ITEM_PIPELINES = {
'doupan.pipelines.DoupanPipeline': 300, # DoupanPipeline自己定义的管道名称
}
这个是我添加的USER_AGENTS,以便模仿多个用户登录使用
USER_AGENTS = [
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0)',
'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.2)',
'Opera/9.27 (Windows NT 5.2; U; zh-cn)',
'Opera/8.0 (Macintosh; PPC Mac OS X; U; en)',
'Mozilla/5.0 (Macintosh; PPC Mac OS X; U; en) Opera 8.0',
'Mozilla/5.0 (Linux; U; Android 4.0.3; zh-cn; M032 Build/IML74K) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30',
'Mozilla/5.0 (Windows; U; Windows NT 5.2) AppleWebKit/525.13 (KHTML, like Gecko) Chrome/0.2.149.27 Safari/525.13'
]
PROXIES = [
{"ip_port" :"121.42.140.113:16816", "user_passwd" : "mr_mao_hacker:sffqry9r"},
#{"ip_prot" :"121.42.140.113:16816", "user_passwd" : ""}
#{"ip_prot" :"121.42.140.113:16816", "user_passwd" : ""}
#{"ip_prot" :"121.42.140.113:16816", "user_passwd" : ""}
]
- 6 在middleware.py文件中实现方法,把在setting添加的USER_AGENTS追加到请求报文的heads中去
from scrapy import signals
import random
import base64
from douban.settings import USER_AGENTS
from douban.settings import PROXIES
# 随机的User-Agent
class RandomUserAgent(object):
def process_request(self, request, spider):
useragent = random.choice(USER_AGENTS)
#print useragent
request.headers.setdefault("User-Agent", useragent)
class RandomProxy(object):
def process_request(self, request, spider):
proxy = random.choice(PROXIES)
if proxy['user_passwd'] is None:
# 没有代理账户验证的代理使用方式
request.meta['proxy'] = "http://" + proxy['ip_port']
else:
# 对账户密码进行base64编码转换
base64_userpasswd = base64.b64encode(proxy['user_passwd'])
# 对应到代理服务器的信令格式里
request.headers['Proxy-Authorization'] = 'Basic ' + base64_userpasswd
request.meta['proxy'] = "http://" + proxy['ip_port']
class DoubanSpiderMiddleware(object):
# Not all methods need to be defined. If a method is not defined,
# scrapy acts as if the spider middleware does not modify the
# passed objects.
@classmethod
def from_crawler(cls, crawler):
............
7 scrapy list 查看当前爬虫名称
8 scrapy crawl 爬虫名
9 JSON数据
{"title": "肖申克的救赎"},
{"title": "霸王别姬"},
{"title": "这个杀手不太冷"},
{"title": "阿甘正传"},
{"title": "美丽人生"},
{"title": "千与千寻"},
{"title": "辛德勒的名单"},
{"title": "泰坦尼克号"},
{"title": "盗梦空间"},
{"title": "机器人总动员"},
{"title": "海上钢琴师"},
{"title": "三傻大闹宝莱坞"},
{"title": "忠犬八公的故事"},
{"title": "放牛班的春天"},
{"title": "大话西游之大圣娶亲"},
{"title": "教父"},
{"title": "龙猫"},
......