Fsimage和Edits解析
相关概念
namenode被格式化之后,将在/opt/module/hadoop-2.8.3/data/tmp/dfs/name/current目录中产生如下文件

- Fsimage文件:HDFS文件系统元数据的一个永久性的检查点,其中包含HDFS文件系统的所有目录和文件idnode的序列化信息。
- Edits文件:存放HDFS文件系统的所有更新操作的路径,文件系统客户端执行的所有写操作首先会被记录到edits文件中。
- seen_txid文件保存的是一个数字,就是最后一个edits_的数字
每次NameNode启动的时候都会将最新的fsimage文件读入内存,并合并edits里面的更新操作,保证内存中的元数据信息是最新的、同步的,可以看成NameNode启动的时候就将fsimage和edits文件进行了合并。
NameNode会把最新的fsimage后缀和seen_txid 之间的edits合并。
使用OIV查看fsimage文件
hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
hdfs oiv -p XML -i fsimage_0000000000000000294 -o fsimage.xml
文件内容如下
-63
1
b3fe56402d908019d99af1f1f4fc65cb1d1436a2
1560614512
1000
1040
0
1073741862
294
16407
6
16385
DIRECTORY
1536189784686
hadoop:supergroup:0755
9223372036854775807
-1
16403
DIRECTORY
user
1536189784687
hadoop:supergroup:0755
-1
-1
16404
DIRECTORY
hadoop
1536190852299
hadoop:supergroup:0755
-1
-1
16405
FILE
client
3
1536189786438
1536320623173
134217728
hadoop:supergroup:0644
1073741858
1036
36667596
0
0
0
16385
16403
16403
16404
16404
16405
16406
16406
16407
0
0
0
0
1
0
0
从上面的文件中可以看出,fsimage中并没有记录块所对应的datenode,这是因为没有必要在fsimage文件中记录,在内存中维护就可以了,datenode像namenode汇报。
oev查看edits文件
hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
hdfs oev -p XML -i edits_inprogress_0000000000000000336 -o edits_inprogress_0000000000000000336.xml
内容如下
-63
OP_START_LOG_SEGMENT
303
OP_MKDIR
304
0
16408
/user/hadoop/test
1536562302682
hadoop
supergroup
493
OP_ADD
305
0
16409
/user/hadoop/test/cpHello.txt._COPYING_
3
1536562302831
1536562302831
134217728
DFSClient_NONMAPREDUCE_1326850463_1
192.168.114.102
true
hadoop
supergroup
420
424e8401-aa20-4dd2-83ae-cedd762158f0
7
OP_ALLOCATE_BLOCK_ID
306
1073741863
OP_SET_GENSTAMP_V2
307
1041
OP_ADD_BLOCK
308
/user/hadoop/test/cpHello.txt._COPYING_
1073741863
0
1041
-2
OP_CLOSE
309
0
0
/user/hadoop/test/cpHello.txt._COPYING_
3
1536562304777
1536562302831
134217728
false
1073741863
1116
1041
hadoop
supergroup
420
OP_RENAME_OLD
310
0
/user/hadoop/test/cpHello.txt._COPYING_
/user/hadoop/test/cpHello.txt
1536562304822
424e8401-aa20-4dd2-83ae-cedd762158f0
12
上述是往hdfs上传文件的一个完成过程
首先创建文件夹,添加文件(不是真正的添加,只是占个位置),分配块ID,生成时间戳,真正上传文件,关闭流,重命名文件。
NameNode和SecondaryNameNode工作机制
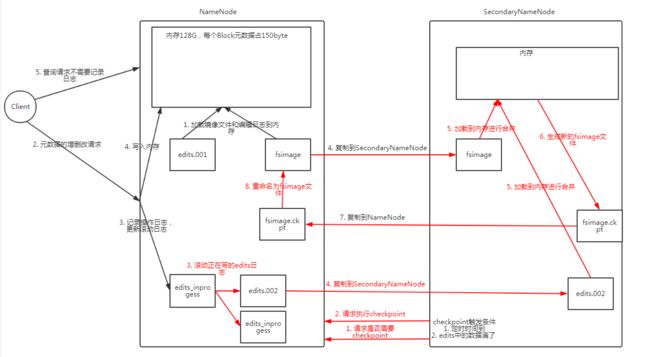
该图可以分成两个阶段看
第一阶段:NameNode启动
1). 第一次启动NameNode格式化后,创建fsimage和edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
2). 客户端对元数据进行增删改的请求。
3). NameNode记录操作日志,更新滚动日志。
4). NameNode在内存中对数据进行增删改查。第二阶段:Secondary NameNode工作
1). Secondary NameNode询问NameNode是否需要checkpoint。直接带回NameNode是否检查结果。
2). Secondary NameNode请求执行checkpoint。
3). NameNode滚动正在写的edits日志。
4). 将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
5). Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
6). 生成新的镜像文件fsimage.ckpt。
7). 拷贝fsimage.chkpoint到NameNode。
8). NameNode将fsimage.chkpoint重新命名成fsimage。
checkpoint时间设置
- 通常情况下,SecondaryNameNode每隔一小时执行一次。如果修改在hdfs-site中
在hdfs-default.xml中值如下
dfs.namenode.checkpoint.period
3600
The number of seconds between two periodic checkpoints.
- 一分钟检查一次操作次数,当操作次数达到1百万时,SecondaryNameNode执行一次。
在hdfs-default.xml配置如下
dfs.namenode.checkpoint.txns
1000000
The Secondary NameNode or CheckpointNode will create a checkpoint
of the namespace every 'dfs.namenode.checkpoint.txns' transactions, regardless
of whether 'dfs.namenode.checkpoint.period' has expired.
dfs.namenode.checkpoint.check.period
60
The SecondaryNameNode and CheckpointNode will poll the NameNode
every 'dfs.namenode.checkpoint.check.period' seconds to query the number
of uncheckpointed transactions.
NameNode故障处理
方法一
将SecondaryNameNode中数据拷贝到NameNode存储数据的目录
- kill -9 NameNode对应的进程
- 删除NameNode存储数据
rm -rf /opt/module/hadoop-2.8.3/data/tmp/dfs/name/ - 拷贝SecondaryNameNode中数据到原NameNode存储数据目录
scp -r hadoop@hadoop-102:/opt/module/hadoop-2.8.3/data/tmp/dfs/namesecondary/* ./name - 重新启动NameNode
方法二
使用-importCheckpoint选项启动NameNode守护进程,从而将SecondaryNameNode中数据拷贝到NameNode目录中
- 修改hdfs-site.xml
dfs.namenode.checkpoint.period
120
dfs.namenode.name.dir
/opt/module/hadoop-2.7.2/data/tmp/dfs/name
- kill -9 namenode进程
- 删除NameNode存储的数据
rm -rf /opt/module/hadoop-2.8.3/data/tmp/dfs/name/ - 如果SecondaryNameNode不和NameNode在一个主机节点上,需要将SecondaryNameNode存储数据的目录拷贝到NameNode存储数据的平级目录,并删除in_use.lock文件
在dfs目录下执行
scp -r hadoop@hadoop-102:/opt/module/hadoop-2.8.3/data/tmp/dfs/namesecondary ./
进入namesecondary目录,删除in_use.lock文件
cd namesecondary
rm -rf in_use.lock - 导入检查点数据(等待一会ctrl+c结束掉)
hdfs namenode -importCheckpoint - 启动namenode
hadoop-daemon.sh start namenode
集群安全模式
概述
NameNode启动时,首先将映像文件(fsimage)载入内存,并执行编辑日志(edits)中的各项操作。一旦在内存中成功建立文件系统元数据的映像,则创建一个新的fsimage文件和一个空的编辑日志。此时,NameNode开始监听DataNode请求。但是此刻,NameNode运行在安全模式,即NameNode的文件系统对于客户端来说是只读的。
系统中的数据块的位置并不是由NameNode维护的,而是以块列表的形式存储在DataNode中。在系统的正常操作期间,NameNode会在内存中保留所有块位置的映射信息。在安全模式下,各个DataNode会向NameNode发送最新的块列表信息,NameNode了解到足够多的块位置信息之后,即可高效运行文件系统。
如果满足“最小副本条件”,NameNode会在30秒钟之后就退出安全模式。所谓的最小副本条件指的是在整个文件系统中99.9%的块满足最小副本级别(默认值:dfs.replication.min=1)。在启动一个刚刚格式化的HDFS集群时,因为系统中还没有任何块,所以NameNode不会进入安全模式。
基本语法
集群处于安全模式,不能执行重要操作(写操作)。集群启动完成后,自动退出安全模式。
- bin/hdfs dfsadmin -safemode get (功能描述:查看安全模式状态)
- bin/hdfs dfsadmin -safemode enter (功能描述:进入安全模式状态)
- bin/hdfs dfsadmin -safemode leave (功能描述:离开安全模式状态)
- bin/hdfs dfsadmin -safemode wait (功能描述:等待安全模式状态,监控安全模式)
模拟等待安全模式
- 先进入安全模式
hdfs dfsadmin -safemode enter - 编写并执行下面脚本
vim testWait.sh
输入如下内容
#!/bin/bash
hdfs dfsadmin -safemode wait
hdfs dfs -put test.txt /
给执行权限
chmod +x testWait.sh
执行
./testWait.sh
- 新打开一个窗口,离开安全模式
hdfs dfsadmin -safemode leave
观察结果,是否上传成功
NameNode多目录配置
NameNode的本地目录可以配置成多个,且每个目录存放内容相同,增加了可靠性
具体步骤如下
- 在hdfs-site.xml文件中增加如下内容
dfs.namenode.name.dir
file:///${hadoop.tmp.dir}/dfs/name1,file:///${hadoop.tmp.dir}/dfs/name2
- 停止集群
stop-dfs.sh - 删除date和logs中所有数据
rm -rf /data /logs - 格式化集群并启动
hdfs namenode -format
start-dfs.sh -
查看结果
 namenode多级目录.png
namenode多级目录.png