
##########################################################
##聚类分析:层次聚类/划分聚类
### 层次聚类--
##1.计算距离
library(flexclust)
data(nutrient,package = "flexclust")
##将行名大写改为小写,大写不好读 tolower
row.names(nutrient)<-tolower(row.names(nutrient))
#标准化数据 scale()
nutrient.scaled<-scale(nutrient)
#####$###########
###计算距离
d<-dist(nutrient.scaled,method = "euclidean")
##选取平均联动的方法进行聚类
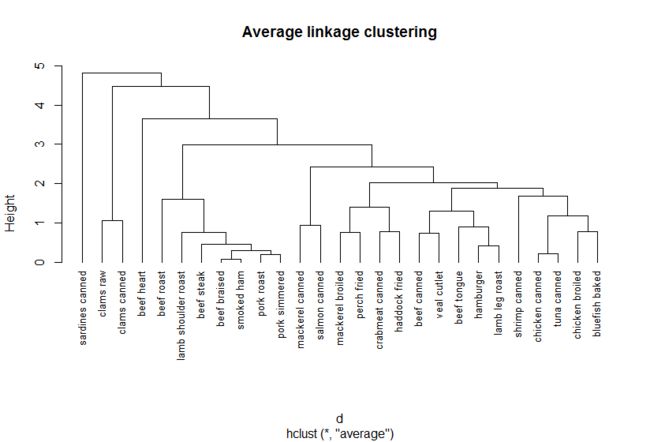
fit.average<-hclust(d,method = "average")
fit.average
##作图 hang=-1可以展示观测值标签,美观 图:从下往上读
plot(fit.average,hang=-1,cex=0.8,main="Average linkage clustering")
#################
###选择聚类的个数--因此前面的可以不写的 NbClust包,NbClust()函数 也可以计算距离
library(NbClust)
devAskNewPage(ask = TRUE)
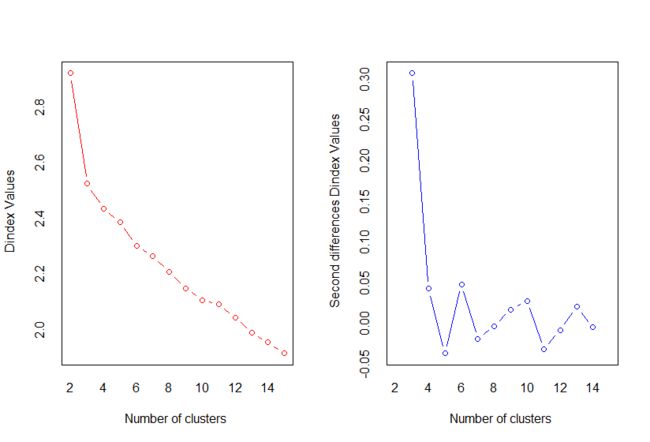
nc<-NbClust(nutrient.scaled,distance = "euclidean",min.nc = 2,max.nc = 15,method = "average")
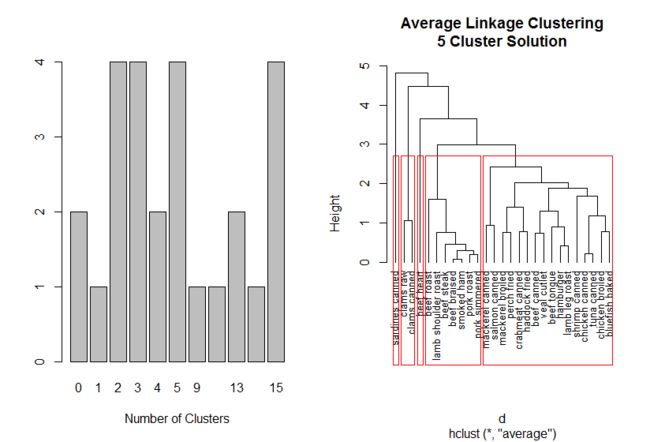
table(nc$Best.n[1,])
barplot(table(nc$Best.n[1,]),xlab="Number of Clusters") ##可以选择投票最多的2,3,5,15,从中选择一个最有意义的。
###获得最终的聚类方法
###cutree 把树状图分成5类 从中选择了5类
clusters<-cutree(fit.average,k=5)
table(clusters)
##描述聚类
aggregate(nutrient,by=list(cluster=clusters),median)
aggregate(as.data.frame(nutrient.scaled),by=list(cluster=clusters),median)
plot(fit.average,hang=-1,cex=0.8,main="Average Linkage Clustering\n5 Cluster Solution")
rect.hclust(fit.average,k=5)
###划分聚类分析:K均值聚类和基于中心点的划分(PAM)-例子 rattle包 178种葡萄酒中的13中化学成分--wine数据集为3种酒13种化学成分
library(rattle)
data(wine,package = "rattle")
head(wine)
###标准化数据-均值为0,标准差为1 ##第一列为三种酒分类,排除在标准化外
df<-scale(wine[-1])
##获得距离以及聚类个数以及聚类
#wssplot确定聚类个数 ##方法一,自写的函数wssplot ;方法二:NbClust:
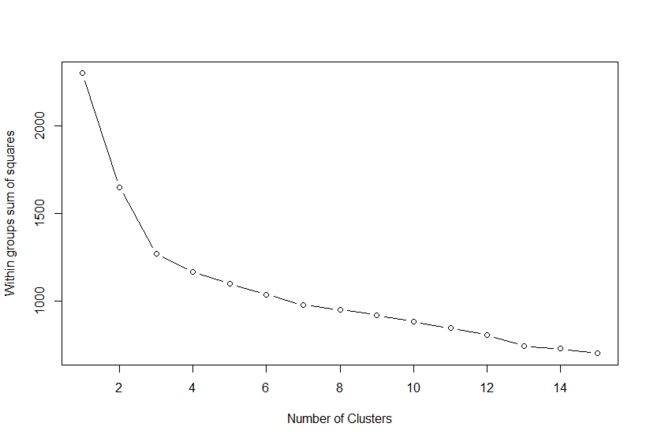
wssplot<- function(data,nc=15,seed=1234){
wss<- (nrow(data)-1)*sum(apply(data,2,var))
for(i in 2:nc){
set.seed(seed)
wss[i] <- sum(kmeans(data, centers = i)$withinss)
}
plot(1:nc,wss,type = "b",xlab = "Number of Clusters",
ylab = "Within groups sum of squares")
}
wssplot(df)
##方法二NbClust
library(NbClust)
set.seed(1234)##保证随机选择的数据作为中心点可以多次操作有一致性:操作可复制
devAskNewPage(ask=TRUE)
nc<-NbClust(df,min.nc=2,max.nc = 15,method = "kmeans")
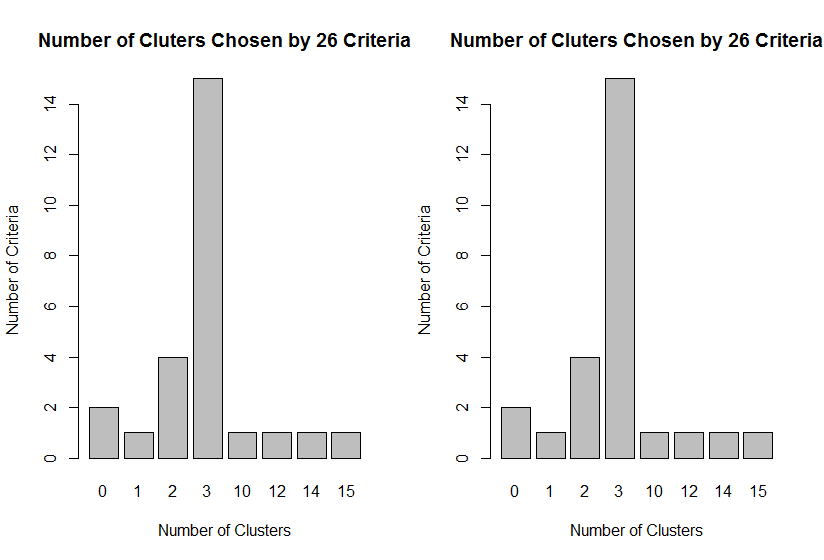
table(nc$Best.nc[1,])###3个类 15个值支持
#作图
barplot(table(nc$Best.nc[1,]),xlab="Number of Clusters",ylab="Number of Criteria",main="Number of Cluters Chosen by 26 Criteria")
###K均值聚类分析
set.seed(1234)
fit.km<-kmeans(df,3,nstart = 25) ##默认nstart=25,
fit.km$size
fit.km$centers
###葡萄酒品种与类成员表示
ct.km<-table(wine$Type,fit.km$cluster)
ct.km
##量化类型变量与类之间的协议 flexclust包
library(flexclust)
randIndex(ct.km)
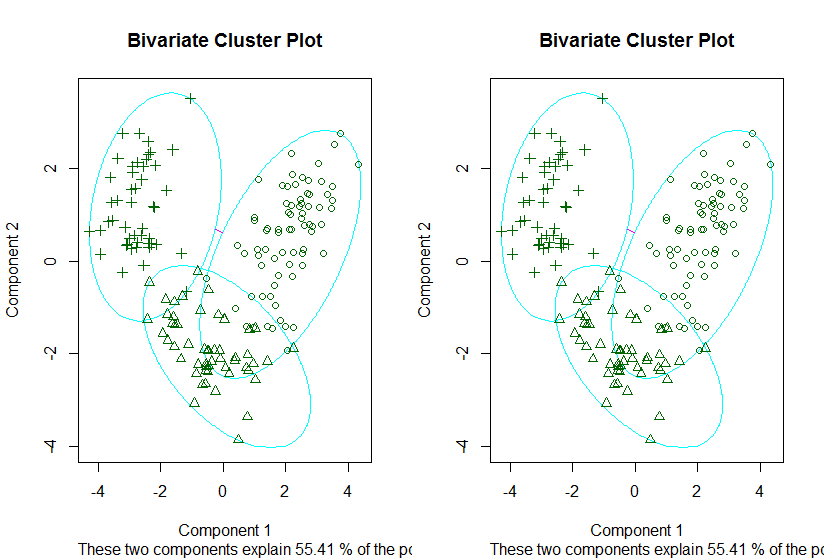
##围绕中心化分类---也就是在坐标轴上不同类 分别画一个圈圈括起来cluster包中的 pam函数
library(cluster)
set.seed(1234)
fit.pam<-pam(wine[-1],k=3,stand = T) #3数据wine、聚类为3类-之前k聚类有求解、标准化stand
fit.pam$medoids ##输出中心点
##作图
clusplot(fit.pam,main="Bivariate Cluster Plot") #####蛮好看的
ct.pm<-table(wine$Type,fit.pam$clustering)
ct.pm
randIndex(ct.pm) ## 调整的兰德指数从K聚类-变为0.7