数据流编程模型
抽象层次
程序和数据流
并行数据流
Windows
Time
有状态的操作
容错检查点checkpoint
批量流媒体
抽象层次
Flink提供不同级别的抽象来开发流/批处理应用程序。
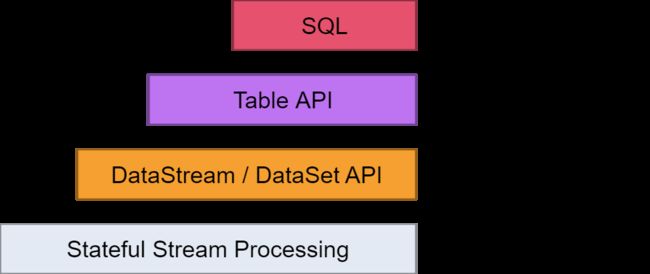
最低级抽象只提供有状态流。它 通过Process Function嵌入到DataStream API中。它允许用户自由处理来自一个或多个流的事件,并使用一致的容错状态。此外,用户可以注册事件时间和处理时间回调,允许程序实现复杂的计算。
-
在实践中,大多数应用程序不需要上述低级抽象,而是针对Core API编程, 如DataStream API(有界/无界流)和DataSet API(有界数据集)。这些流畅的API提供了用于数据处理的通用构建块,例如各种形式的用户指定的转换,连接,聚合,窗口,状态等。在这些API中处理的数据类型在相应的编程语言中表示为类。
低级Process Function与DataStream API集成在一起,因此只能对某些操作进行低级抽象。该数据集API提供的有限数据集的其他原语,如循环/迭代。
-
Table API是以表为中心的声明性DSL,其可被动态地改变的表(表示流时)。Table API遵循(扩展)关系模型:表的schema(类似于在关系数据库中的表)和API提供可比的操作,如选择,项目,连接,分组依据,聚合等表API程序以声明方式定义应该执行的逻辑操作,而不是准确指定 操作代码的外观。尽管Table API可以通过各种类型的用户定义函数进行扩展,但它的表现力却不如Core API,但使用更简洁(编写的代码更少)。此外,Table API程序还会通过优化程序,在执行之前应用优化规则。
可以在表和DataStream / DataSet之间无缝转换,允许程序混合Table API以及DataStream 和DataSet API。
Flink提供的最高级抽象是SQL。这种抽象在语义和表达方面类似于Table API,但是将程序表示为SQL查询表达式。在SQL抽象与表API紧密地相互作用,和SQL查询可以通过定义表来执行表API。
程序和数据流
Flink程序的基本构建块是流(streams )和转换算子(transformation operators)。(请注意,Flink的DataSet API中使用的DataSet也是内部流 - 稍后会详细介绍。)从概念上讲,流是(可能永无止境的)数据记录流,而转换是将一个或多个流作为一个或多个流的操作。输入,并产生一个或多个输出流。
执行时,Flink程序映射到流数据流,由流和转换算子组成。每个数据流都以一个或多个sources 开头,并以一个或多个sink结束。数据流类似于任意有向无环图 (DAG)。尽管通过迭代结构允许特殊形式的循环 ,但为了简单起见,我们将在大多数情况下对其进行掩饰。

通常,程序中的transformations 与数据流中的运算算子之间存在一对一的对应关系。但是,有时一个transformations 可能包含多个转换运算算子。
源流和接收器记录在流连接器和批处理连接器文档中。DataStream运算符和DataSet转换中记录了转换。
并行数据流
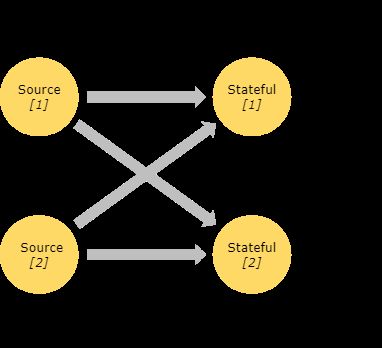
Flink中的程序本质上是并行和分布式的。在执行期间,流具有一个或多个流分区(stream partitions),并且每个运算算子具有一个或多个子任务。子任务彼此独立,并且可以在不同的线程中执行,并且可能在不同的机器或容器上执行。
运算算子任务的数量是该特定算子的并行度。流的并行性始终是其生成运算算子的并行性。同一程序的不同运算算子可能具有不同的并行级别。

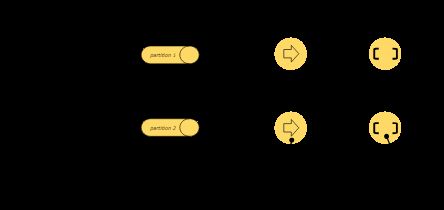
流可以以一对一(或转发)模式或以重新分发模式在两个运算算子之间传输数据:
一对一流(例如,在上图中的Source和map()运算符之间)保留元素的分区和排序。这意味着map()运算符的subtask [1] 将看到与Source运算符的subtask [1]生成的顺序相同的元素。
重新分配流(在上面的map()和keyBy / window之间,以及 keyBy / window和Sink之间)重新分配流。每个运算算子子任务将数据发送到不同的目标子任务,具体取决于所选的转换(transformation)。比如: keyBy()(其通过散列密钥重新分区),broadcast() ,或rebalance() (其重新分区随机地)。在重新分配交换中,元素之间的排序仅保留在每对发送和接收子任务中(例如,map()的子任务[1] 和子任务[2]keyBy / window)。因此,在此示例中,保留了每个密钥内的排序,但并行性确实引入了关于不同密钥的聚合结果到达接收器的顺序的非确定性。
有关配置和控制并行性的详细信息,请参阅并行执行的文档。
Windows(窗口)
聚合事件(例如,counts,sum)在stream上的工作方式与batch处理上的方式不同。例如,不可能计算流中的所有元素,因为流通常是无限的(无界)。相反,流上的聚合(计数,总和等)由窗口限定,例如“在最后5分钟内计数”或“最后100个元素的总和”。
Windows可以是时间驱动的(例如:每30秒)或数据驱动(例如:每100个元素)。人们通常区分不同类型的窗口,例如tumbling windows(没有重叠), *sliding windows (具有重叠)和session windows *(由不活动间隙打断)。

可以在此博客文章中找到更多窗口示例。更多详细信息在窗口文档中。
Time
当在流程序中引用时间(例如定义窗口)时,可以参考不同的时间概念:
事件时间(Event Time)是创建事件的时间。它通常由事件中的时间戳描述,例如由生产传感器或生产服务附加。Flink通过时间戳分配器访问事件时间戳。
摄取时间(Ingestion time)是事件在源操作员处输入Flink数据流的时间。
处理时间(Processing Time )是执行基于时间的操作的每个运算算子的本地时间。
有关如何处理时间的更多详细信息,请参阅事件时间文档。
有状态的操作
虽然数据流中的许多操作只是一次查看一个单独的事件(例如事件解析器),但某些操作会记住多个事件(例如窗口操作符)的信息。这些操作称为有状态。
状态操作的状态保持在可以被认为是嵌入式键/值存储的状态中。状态被分区并严格地与有状态运营商读取的流一起分发。因此,只有在keyBy()函数之后才能在键控流上访问键/值状态,并且限制为与当前事件的键相关联的值。对齐流和状态的密钥可确保所有状态更新都是本地操作,从而保证一致性而无需事务开销。此对齐还允许Flink重新分配状态并透明地调整流分区。
有关更多信息,请参阅有关状态的文档。
容错检查点
Flink使用流重放(stream replay )和检查点(checkpointing)的组合实现容错。检查点与每个输入流中的特定点以及每个算子的对应状态相关。通过恢复算子的状态并从检查点重放事件,可以从检查点恢复流数据流,同时保持一致性(满足恰好一次处理语义)。
检查点间隔是在系统执行期间容错的开销和发生错误时恢复所需要的时间(需要重放的事件的数量)来折衷取值。
容错内部的描述提供了有关Flink如何管理检查点和相关主题的更多信息。有关启用和配置检查点的详细信息,请参阅检查点API文档。
批量流媒体
Flink执行批处理程序作为流程序的特殊情况,其中流是有界的(有限数量的元素)。数据集(DataSet)在内部视为数据流(stream)。因此,上述概念以相同的方式应用于批处理程序,并且它们适用于流程序,除了少数例外:
批处理程序的容错不使用检查点。通过完全重放流来进行恢复。这是可能的,因为输入有限。这会使成本更多地用于恢复,但使常规处理更便宜,因为它避免了检查点。
DataSet API中的有状态操作使用简化的内存/核外数据结构,而不是键/值索引。
DataSet API引入了特殊的同步(超级步骤)迭代,这些迭代只能在有界流上进行。有关详细信息,请查看迭代文档。
扫描下方二维码,及时获取更多互联网求职面经、java、python、爬虫、大数据等技术,和海量资料分享:
公众号菜鸟名企梦后台发送“csdn”即可免费领取【csdn】和【百度文库】下载服务;
公众号菜鸟名企梦后台发送“资料”:即可领取5T精品学习资料、java面试考点和java面经总结,以及几十个java、大数据项目,资料很全,你想找的几乎都有
