本文主要介绍正则re模块的常用函数。
1. 编译正则
import re
p = re.compile(r'ab*')
print '【Output】'
print type(p)
print p
print p.findall('abbc')
【Output】
<_sre.SRE_Pattern object at 0x7fe4783c7b58>
['abb']
正则编译的好处:速度更快。
2. re模块常用函数和方法
1. 不区分大小写匹配
p = re.compile(r'ab*',re.I)
print '【Output】'
print p.findall('AbBbc')
【Output】
['AbBb']
2. 字符串前加r,反斜杠\就不会被作任何特殊处理
即:如果字符串前带r,表示这是一个正则字符串,字符串里面用到的需要表示转义用途的\不用使用双重转义。
s = 'a+++'
p1 = re.compile('\++')
p2 = re.compile('\\++')
p3 = re.compile(r'\++')
# p4 = re.compile(r'\\++')
print '【Output】'
print p1.findall(s)
print p2.findall(s)
print p3.findall(s)
# print p4.findall(s)
# 用p4来匹配会报错:error: multiple repeat
【Output】
['+++']
['+++']
['+++']
3. 两个匹配函数
match():判断正则是否在字符串开始位置出现。search():判断正则是否在字符串任何位置出现。
p = re.compile(r'aa')
print '【Output】'
print p.match('aabcd')
print p.match('bcaad')
print p.search('bcaad')
【Output】
<_sre.SRE_Match object at 0x7fe47020a098>
None
<_sre.SRE_Match object at 0x7fe47020a098>
4. 匹配查找函数
findall():找到正则匹配的所有子串,并作为列表返回。finditer():找到正则匹配的所有子串,并作为迭代器返回。
p = re.compile(r'\d')
s = 'a1b2c3d'
print '【Output】'
print p.findall(s)
print p.finditer(s)
for ss in p.finditer(s):
print ss
print ss.group()
【Output】
['1', '2', '3']
<_sre.SRE_Match object at 0x7fe47020a780>
1
<_sre.SRE_Match object at 0x7fe47020a6b0>
2
<_sre.SRE_Match object at 0x7fe47020a780>
3
5. MatchObject实例方法
p = re.compile(r'aa')
m = p.search('1aa2bb3aad')
print '【Output】'
print m.group()
print m.group(0)
#print m.group(1) # IndexError: no such group,因为当前只有一个分组
print m.start()
print m.end()
print m.span()
【Output】
aa
aa
1
3
(1, 3)
p = re.compile(r'age:(\d+),score:(\d+)')
info = 'age:15,score:98;age:20,score:100'
it = p.finditer(info)
print '【Output】'
for x in it:
print 'info=({0}),age={1},score={2}'.format(x.group(0),x.group(1),x.group(2))
【Output】
info=(age:15,score:98),age=15,score=98
info=(age:20,score:100),age=20,score=100
6. 其他re顶级函数
(1) 匹配开头
re.match(pattern,str,flags = 0)
注:这里的pattern既可以直接使用正则字符串(r'...'),又可以使用编译后的正则(p = re.compile(r'...'))
(2) 匹配所有位置
re.search(pattern,str,flags = 0)
re.search()函数和re.match()函数的不同用法举例:
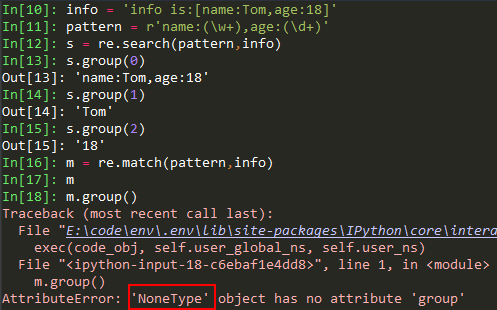
(3) 替换子串
re.sub(pattern,repl,str,count = 0,flags = 0)
print '【Output】'
print re.sub(r'a.b','xxx','acb,ayb,acd,aub,dd',2)
# re.sub()是产生一个新的字符串,使用re.sub()函数替换后,并不会对原字符串产生影响
【Output】
xxx,xxx,acd,aub,dd
替换子串与后项引用的结合使用举例:
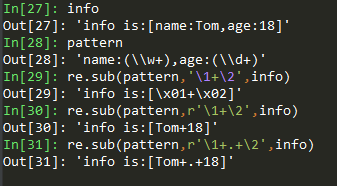
可以看出re.sub()函数的第二个参数支持对前面的正则分组的后向引用,值得注意的是,第二个参数如果需要进行后向引用,那么必须写成raw字符串(r开头的字符串),且字符串中的正则元字符(如.、+等)会被当成普通字符出现在结果中。
注:正则后向引用相关用法参见博文:python正则表达式系列(4)——分组和后向引用
(4) 替换子串
re.subn(pattern,repl,str,count = 0,flags = 0),作用同re.sub()函数,只不过subn()函数返回一个二元组,包含了替换后的字符串和替换次数。
print '【Output】'
print re.subn(r'a.b','xxx','acb,ayb,acd,aub,dd')
【Output】
('xxx,xxx,acd,xxx,dd', 3)
(5) 字符串分割函数
re.split(pattern, string, maxsplit=0, flags=0)
p = re.compile(r'[+\-*/]')
print '【Output】'
print re.split(p,'1+2-3*4/5')
【Output】
['1', '2', '3', '4', '5']
(6) 子串查找函数
re.findall(pattern, string, flags=0)
print '【Output】'
print re.findall(r'a+','abbaaccaaa')
【Output】
['a', 'aa', 'aaa']
# 分组查找:
print '【Output】'
print re.findall(r'age=(\d+)','age=1,age=21')
【Output】
['1', '21']