OSI7层模型
开放系统互联(Open System Interconnection),国际标准化组织(ISO)制定了OSI模型,该模型定义了不同计算机互联的标准,是设计和描述计算机网络通信的基本框架。OSI模型把网络通信的工作分为7层.
- 物理层
- 数据链路层 硬件性能
- 网络层 kvm vm 虚拟化性能为题
- 传输层(TCP四层) 内核参数设置控制 tcp udp ip
- 会话层/控制层(TCP四层) 建立连接 断开连接等
- 表示层(TCP四层)解压 解密 编码转换
- 应用层(TCP四层)http ftp https ssh
TCP 滑动窗口、三次握手、四次挥手、粘包拆包
三次握手
- 在TCP/IP协议中,TCP协议提供可靠的连接服务,采用三次握手建立一个连接。
- 第一次握手:建立连接时,客户端发送syn包(syn=j)到服务器,并进入SYN_SEND状态,等待服务器确认;
- 第二次握手:服务器收到syn包,必须确认客户的SYN(ack=j+1),同时自己也发送一个SYN包(syn=k),即SYN+ACK包,此时服务器进入SYN_RECV状态;
- 第三次握手:客户端收到服务器的SYN+ACK包,向服务器发送确认包ACK(ack=k+1),此包发送完毕,客户端和服务器进入ESTABLISHED状态,完成三次握手。
完成三次握手,客户端与服务器开始传送数据,在上述过程中,还有一些重要的概念:
- 未连接队列:在三次握手协议中,服务器维护一个未连接队列,该队列为每个客户端的SYN包(syn=j)开设一个条目,该条目表明服务器已收到SYN包,并向客户发出确认,正在等待客户的确认包。这些条目所标识的连接在服务器处于SYN_RECV状态,当服务器收到客户的确认包时,删除该条目,服务器进入ESTABLISHED状态。
- SYN-ACK重传次数 服务器发送完SYN-ACK包,如果未收到客户确认包,服务器进行首次重传,等待一段时间仍未收到客户确认包,进行第二次重传,如果重传次数超过系统规定的最大重传次数,系统将该连接信息从半连接队列中删除。注意,每次重传等待的时间不一定相同。
- 半连接存活时间:是指半连接队列的条目存活的最长时间,也即服务从收到SYN包到确认这个报文无效的最长时间,该时间值是所有重传请求包的最长等待时间总和。有时我们也称半连接存活时间为Timeout时间、SYN_RECV存活时间。
- linux 和win查看链接状态
netstat -ano
- 链接状态汇总
- LISTEN:侦听来自远方的TCP端口的连接请求
- SYN-SENT:再发送连接请求后等待匹配的连接请求
- SYN-RECEIVED:再收到和发送一个连接请求后等待对方对连接请求的确认
- ESTABLISHED:代表一个打开的连接
- FIN-WAIT-1:等待远程TCP连接中断请求,或先前的连接中断请求的确认
- FIN-WAIT-2:从远程TCP等待连接中断请求
- CLOSE-WAIT:等待从本地用户发来的连接中断请求
- CLOSING:等待远程TCP对连接中断的确认
- LAST-ACK:等待原来的发向远程TCP的连接中断请求的确认
- TIME-WAIT:等待足够的时间以确保远程TCP接收到连接中断请求的确认
- CLOSED:没有任何连接状态
- 设置参数
net.ipv4.tcp_max_syn_backlog //表示未连接队列的最大容纳数目。
net.ipv4.tcp_synack_retries // SYN+ACK重发次数
net.ipv4.tcp_syn_rcvd_max //SYN_RECV状态的最大个数 - 重发时间间隔
RTO表示时间间隔
第一次重试 RTO*1
第二次重试 RTO*2
第三次重试 RTO*4
第四次重试 RTO*8
达到指定次数 应用层超时
UDP
UDP和TCP协议的主要区别是两者在如何实现信息的可靠传递方面不同。

TCP协议中包含了专门的传递保证机制,当数据接收方收到发送方传来的信息时,会自动向发送方发出确认消息;发送方只有在接收到该确认消息之后才继续传送其它信息,否则将一直等待直到收到确认信息为止。与TCP不同,UDP协议并不提供数据传送的保证机制。如果在从发送方到接收方的传递过程中出现数据报的丢失,协议本身并不能做出任何检测或提示。因此,通常人们把UDP协议称为 不可靠的传输协议。
在有些情况下UDP协议可能会变得非常有用。因为UDP具有TCP所望尘莫及的速度优势。虽然TCP协议中植入了各种安全保障功能,但是在实际执行的过程中会占用大量的系统开销,无疑使速度受到严重的影响。反观UDP由于排除了信息可靠传递机制,将安全和排序等功能移交给上层应用来完成,极大降低了执行时间,使速度得到了保证。
DDos攻击
- CC攻击 ChallengeCollapsar 意为"挑战黑洞"
模拟多个用户不停的进行访问,CC攻击又可分为代理CC攻击,和肉鸡CC攻击。 - SYN攻击
SYN攻击属于DOS攻击的一种,它利用TCP协议缺陷,通过发送大量的半连接请求,耗费CPU和内存资源。SYN攻击除了能影响主机外,还可以危害路由器、防火墙等网络系统,事实上SYN攻击并不管目标是什么系统,只要这些系统打开TCP服务就可以实施。 - NTP攻击
NTP是Network Time Protocol(网络时间协议)的简称,是互联网中时间同步的标准之一,它的用途是把计算机的时钟同步到国际标准时间,连接在互联网上的机器通过该协议校准时间。
NTP协议中Monlist指令可以获取与目标NTP Server进行过同步的最新600个客户机IP。因此一个很小的请求包,就能获取到大量的由IP地址组成的连续UDP包。 - DNS攻击
域名欺骗
JVM垃圾回收与内存模型
垃圾回收(Garbage Collection,GC)算法
- 引用计数
给每个对象分配一个计算器,当有引用指向这个对象时,计数器加1,当指向该对象的引用失效时,计数器减一。最后如果该对象的计算器为0时,java垃圾回收器会认为该对象是可回收的。
循环引用出现无法回收的问题。 -
可达性分析算法(Reachability Analysis)
通过一系列"GC Roots"对象作为起始点,开始向下搜索;
搜索所走过和路径称为引用链(Reference Chain);
当一个对象到GC Roots没有任何引用链相连时(从GC Roots到这个对象不可达),则证明该对象是不可用的;
 可达性分析算法
可达性分析算法
Java中,GC Roots对象包括:
(1)、虚拟机栈(栈帧中本地变量表)中引用的对象;
(2)、方法区中类静态属性引用的对象;
(3)、方法区中常量引用的对象;
(4)、本地方法栈中JNI(Native方法)引用的对象;
主要在执行上下文中和全局性的引用;
分析过程需要GC停顿(引用关系不能发生变化),即停顿所有Java执行线程(称为"Stop The World",是垃圾回收重点关注的问题);
由于垃圾回收会导致java进程停顿响应一段时间,所以有两种优化方式
- 分代垃圾回收
只是根据对象存活周期的不同将内存划分为几块;
这样就可以根据各个年代的特点采用最适当的收集算法;
一般把Java堆分为新生代和老年代;- 新生代
每次垃圾收集都有大批对象死去,只有少量存活;
所以可采用复制算法; - 老年代
对象存活率高,没有额外的空间可以分配担保;
使用"标记-清理"或"标记-整理"算法;
- 新生代
优化方式 减少每次回收对象数量 不同区域采用不同的回收算法
缺点 老年代对象增多后 每次回收的数量还是不能减少。不能控制每次回收的时间
- 增量GC
将回收分段进行 不是一次性完成。
优化方式 进一步减小每次回收的对象数量,控制了每次回收时间。
复制算法(Copying)
算法思路
1. 把内存划分为大小相等的两块,每次只使用其中一块;
2. 当一块内存用完了,就将还存活的对象复制到另一块上(而后使用这一块);
3. 再把已使用过的那块内存空间一次清理掉,而后重复步骤2;
新生代回收采用此类算法,所以新生代内存分为2块Eden和Survivor Space,Survivor Space又分为 To Survivor、 From Survivor
- 新建的对象都会分配到Eden区
- 当经过一次垃圾回收后从Eden区到to Survivor区
- 当to Survivor区快满的时候 进行复制算法 将存活的对象复制到 from Survivor区,存活对象年龄加1
- 当from Survivor区快满的时候,进行复制算法 将存活的对象复制到to Survivor区,存活对象年龄加1
-
当对象达到一定年龄的时候 复制到老年代区
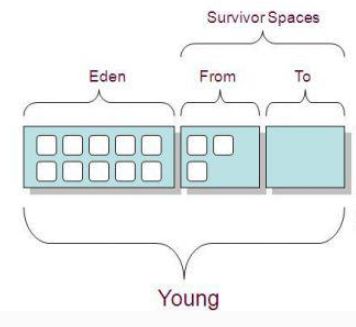 新生代堆内存模型
新生代堆内存模型
如果另一块Survivor空间没有足够空间存放上一次新生代收集下来的存活对象时,这些对象将直接通过分配担保机制(Handle Promotion)进入老年代;
所以当设置的年轻代和Eden与survivor不合理的时候 将导致大部分对象分配到了老年代,老年代对象过多的时候 将导致full gc ,full gc频繁将导致整个jvm吞吐量下降
标记清除整理(mark sweep compact)
将存活的对象像内存的一端移动
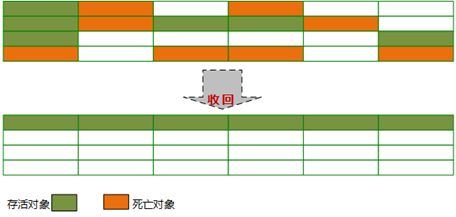
用于老年代回收,因为老年代对象存活率高,没有额外的空间可以分配担保;
mysql集群
了解binlog
- binlog基本定义:二进制日志,也成为二进制日志,记录对数据发生或潜在发生更改的SQL语句,并以二进制的形式保存在磁盘中;
- 文件位置:默认存放位置为数据库文件所在目录下
- 文件的命名方式: 名称为hostname-bin.xxxxx (重启mysql一次将会自动生成一个新的binlog)
- 启动binlog方法
- 方法一、修改my.cnf参数文件,该方法需要重启
[mysqld] log-bin = mysql-bin- 方法二、不重启修改二进制日志配置,该方法mysql的版本需要5.6以上
SET @@global.log_bin=1|0 (1为开启,0为关闭) SET @@global.binlog_size=37268(单位bytes)
利用binlog恢复
- 最长用的就是回复指定数据端的数据了,可以直接恢复到数据库中:
mysqlbinlog --start-date="2012-10-15 16:30:00" --stop-date="2012-10-15 17:00:00" mysql_bin.000001 |mysql -uroot -p123456
亦可导出为sql文件,再导入至数据库中:
mysqlbinlog --start-date="2012-10-15 16:30:00" --stop-date="2012-10-15 17:00:00" mysql_bin.000001 >d:\1.sql
source 1.sql
- 指定开始\结束位置,从上面的查看产生的binary log我们可以知道某个log的开始到结束的位置,我们可以在恢复的过程中指定回复从A位置到B位置的log.需要用下面两个参数来指定:
--start-positon="50" //指定从50位置开始
--stop-postion="100"//指定到100位置结束
主从
主服务器将更新写入binlog,并维护文件的一个索引以跟踪日志循环。这些日志可以记录发送到从服务器的更新。

- 主库将更新写入binlog
- 从库读取主库binlog 写入自己的relay log
- 从库的sql线程读取relay log 进行更新
所以master是以推送的方式通知从服务器更新。
改变主mysql的配置,注意每个mysql的server-id必须不同
[mysqld]
log_bin = mysql-bin
server_id = 1
改变从mysql的配置
[mysqld]
log_bin = mysql-bin
server_id = 2
relay_log = mysql-relay-bin
log_slave_updates = 1
改变配置后重启主从mysql
- 连接主库,执行命令 查看主库状态
SHOW MASTER STATUS;
- 连接从库,执行
CHANGE MASTER TO MASTER_HOST='主库ip',
MASTER_USER='主库用户名',
MASTER_PASSWORD='主库密码',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=0;
启动从库
START SLAVE;
查看从库状态
SHOW SLAVE STATUS\G
如果看到
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
表示主从创建成功
主主
将主从的流程反过来再做一次,就可以实现主主复制。
改变上面的主库配置
[mysqld]
log_bin = mysql-bin
server_id = 1
relay_log = mysql-relay-bin
log_slave_updates = 1
重启两个库都执行后续操作即可实现主住复制
主主双从
主主复制成功后,可以每个主库在连接一个从库
数据库事务
事务的4个特性ACID
- Automic 原子性
事务(Transaction)是并发控制的基本单位。 所谓事务,它是一个操作序列,这些操作要么都执行,要么都不执行,它是一个不可分割的工作单位。 - Consistency 一致性
在事务开始之前和事务结束以后,数据库的完整性没有被破坏。这表示写入的资料必须完全符合所有的预设规则,这包含资料的精确度、串联性以及后续数据库可以自发性地完成预定的工作。 - Isolation 隔离性
数据库允许多个并发事务同时对其数据进行读写和修改的能力,隔离性可以防止多个事务并发执行时由于交叉执行而导致数据的不一致。事务隔离分为不同级别,包括读未提交(Read uncommitted)、读提交(read committed)、可重复读(repeatable read)和串行化(Serializable)。 - Duration 持久性
事务处理结束后,对数据的修改就是永久的,即便系统故障也不会丢失。
数据库事务隔离级别
- Read uncommitted(读未提交)
容易产生脏读,再一次查询中,查到了另一个事务未提交的数据,导致查询数据不准确。
例如:查询工资,读到了一条未提交的错误数据。那条数据在回滚后再也查不到。页面显示工资10w 实际可能就1k 。正常因为工资数据未提交应该显示工资未发放。 - read committed (读已提交)
容易产生不可重复读,再一个事务内两次查询结果不一致,主要原因是另一个事务提交了新的数据。
例如:信用卡付款,开始查询了余额充足,输入密码后显示余额不足,因为输入密码的时候,另一笔交易自动提交了。 - repeatable read (可重复读)
事务查询后,其它事务不再允许修改(UPDATE)数据。
容易产生幻读
再一次update表中几个符合条件的数据时候 第二个事务提交了一条新符合条件数据,在update那个事务看来就像有一条符合条件的数据没有被update执行。
例如:打印话费的时候,在线查询话费是100条记录,打印之后是101条记录。因为打印的时候又打了一个电话。 - Serializable (串行化)
Serializable 是最高的事务隔离级别,在该级别下,事务串行化顺序执行,可以避免脏读、不可重复读与幻读。但是这种事务隔离级别效率低下,比较耗数据库性能,一般不使用。
大多数数据库默认的事务隔离级别是Read committed,比如Sql Server , Oracle。Mysql的默认隔离级别是Repeatable read。
mysql锁情况
例1: (明确指定主键,并且有此数据,row lock)
SELECT * FROM products WHERE id='3' FOR UPDATE;
例2: (明确指定主键,若查无此数据,无lock)
SELECT * FROM products WHERE id='-1' FOR UPDATE;
例2: (无主键,table lock)
SELECT * FROM products WHERE name='Mouse' FOR UPDATE;
例3: (主键不明确,table lock)
SELECT * FROM products WHERE id<>'3' FOR UPDATE;
例4: (主键不明确,table lock)
SELECT * FROM products WHERE id LIKE '3' FOR UPDATE;
mysql性能优化
- explain
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。 - 使用方法,在select语句前加上explain就可以了:
- 结果分析
- table:显示这一行的数据是关于哪张表的
- type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、indexhe和ALL
- possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。可以为相关的域从WHERE语句中选择一个合适的语句
- key: 实际使用的索引。如果为NULL,则没有使用索引。很少的情况下,MYSQL会选择优化不足的索引。这种情况下,可以在SELECT语句中使用USE INDEX(indexname)来强制使用一个索引或者用IGNORE INDEX(indexname)来强制MYSQL忽略索引
- key_len:使用的索引的长度。在不损失精确性的情况下,长度越短越好
- ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
- rows:MYSQL认为必须检查的用来返回请求数据的行数
- Extra:关于MYSQL如何解析查询的额外信息。将在表4.3中讨论,但这里可以看到的坏的例子是Using temporary和Using filesort,意思MYSQL根本不能使用索引,结果是检索会很慢
- extra结果
- Distinct:一旦MYSQL找到了与行相联合匹配的行,就不再搜索了
- Not exists: MYSQL优化了LEFT JOIN,一旦它找到了匹配LEFT JOIN标准的行,就不再搜索了
- Range checked for each Record(index map:#):没有找到理想的索引,因此对于从前面表中来的每一个行组合,MYSQL检查使用哪个索引,并用它来从表中返回行。这是使用索引的最慢的连接之一
- Using filesort: 看到这个的时候,查询就需要优化了。MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行
- Using index: 列数据是从仅仅使用了索引中的信息而没有读取实际的行动的表返回的,这发生在对表的全部的请求列都是同一个索引的部分的时候
- Using temporary 看到这个的时候,查询需要优化了。这里,MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上
- Where used 使用了WHERE从句来限制哪些行将与下一张表匹配或者是返回给用户。如果不想返回表中的全部行,并且连接类型ALL或index,这就会发生,或者是查询有问题不同连接类型的解释(按照效率高低的顺序排序)
- system 表只有一行:system表。这是const连接类型的特殊情况
- const:表中的一个记录的最大值能够匹配这个查询(索引可以是主键或惟一索引)。因为只有一行,这个值实际就是常数,因为MYSQL先读这个值然后把它当做常数来对待
- eq_ref:在连接中,MYSQL在查询时,从前面的表中,对每一个记录的联合都从表中读取一个记录,它在查询使用了索引为主键或惟一键的全部时使用
- ref:这个连接类型只有在查询使用了不是惟一或主键的键或者是这些类型的部分(比如,利用最左边前缀)时发生。对于之前的表的每一个行联合,全部记录都将从表中读出。这个类型严重依赖于根据索引匹配的记录多少—越少越好
- range:这个连接类型使用索引返回一个范围中的行,比如使用>或<查找东西时发生的情况
- index: 这个连接类型对前面的表中的每一个记录联合进行完全扫描(比ALL更好,因为索引一般小于表数据)
- ALL:这个连接类型对于前面的每一个记录联合进行完全扫描,这一般比较糟糕,应该尽量避免
敏捷开发
持续可以 持续集成
四个价值观
沟通 简单 反馈 谦逊
项目管理
- 时间
保证按时完成项目、合理分配资源、发挥最佳工作效率。合理的安排时间,保证项目按时完成 - 成本
承包人为使项目成本控制在计划目标之内所作的预测、计划、控制、调整、核算、分析和考核等管理工作。
项目成本管理就是要确保在批准的预算内完成项目,具体项目要依靠制定成本管理计划、成本估算、成本预算、成本控制四个过程来完成。 - 质量
代码规范 抽象设计 方便扩展 - 风险
风险识别,风险量化, 风险对策。
引用文章
- Java虚拟机垃圾回收(二) 垃圾回收算法:标记-清除算法 复制算法 标记-整理算法 分代收集算法 火车算法
- 理解事务的4种隔离级别