Bitcask 存储模型的实现 - merge与hint文件
在《Bitcask存储模型的实现 - 基本框架》中,我们了解了Bitcask存储模型中数据的存储方式、内存索引的组织形式,以及如何使用缓存加速数据读取。另外,Bitcask存储模型中提出闲时进行merge减少数据冗余、运用hint文件加速创建内存索引,下面我们来看merge的具体实现、如何用hint文件加速索引创建。
merge
Bitcask是日志型存储模型,对于新增和更改的操作,都Append到磁盘,磁盘使用率将随着操作的增多而增长。
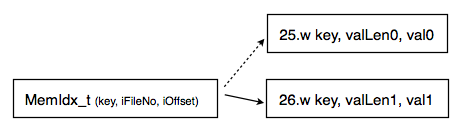
以上图例表示,key及对应val最开始存放在25.w,之后对数据进行了更改,并通过Append存放到26.w中,内存中的索引相应地修改,这时25.w中的key数据即变成废弃的数据。
怎么清理这些冗余的数据呢?因内存索引指向磁盘中当前有效的key数据,我们可以利用这个特性清理冗余的数据。在数据存放目录下,我们再定义一个文件:
xxx.m:数据存储文件,存储经过merge后的数据,相比xxx.w文件,减少了废弃数据
假设一条磁盘上的记录为一条Record,清理冗余数据的过程如下:
1. 遍历.w文件中的Record,根据Record中的key反查对应的MemIdx_t
(参照《Bitcask存储模型的实现 - 基本框架》一文,通过对key计算hash值可取得相应MemIdx_t)
2. 如果 Record.iFileNo == stMemIdx.iFileNo && Record.iOffset == stMemIdx.iOffset,则表示该条Record为有效数据
3. 将满足以上条件的Record记录到一个.m文件中,同时更新内存索引MemIdx_t中的iFileNo、iOffset,跳过不满足条件的Record
4. 当遍历完一个.w文件之后,将其删除
以上过程将.w中的多余数据滤去,将有效的数据迁移到.m文件中,因为数据在磁盘中的位置变了,所以相应地要修改内存中的索引数据。随着有更多的更新操作,.m文件中也将存在冗余数据,因而对.w进行完以上操作之后,还会遍历已有的.m文件进行同样的操作。
hint文件
以上谈到的Bitcask实现中,内存索引有很大的作用,不仅加速了数据读取,在merge过程中还以其为标准,判断哪些数据是有效数据,哪些数据可以删除。但内存数据易失,当程序或机器重启时即丢失,如果想重建内存索引数据,要遍历磁盘上所有的.m和.w文件,这样效率很低,hint文件是加速内存索引创建的一种方式:
xxx.h:加速内存索引创建的hint文件,相比.w、.m文件,只保存key/valLen/iFileNo/iOffset,并不保存val数据
在merge的过程中,当检查到有效Record数据、写入.m文件后,将该Record的key/keyLen/valLen/iFileNo/iOffset指标写入.h文件。当程序重启时,遍历.h文件,即可重建内存索引数据。