Bitcask哈希存储系统
一. 简介
二. 系统架构
1.日志型的数据文件
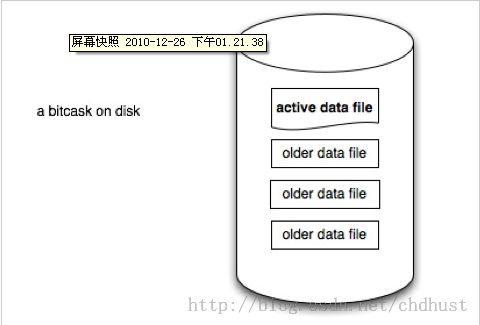
何谓日志型?就是append only,所有写操作只追加而不修改老的数据,就像我们的各种服务器日志一样。在Bitcask模型中,数据文件以日志型只增不减的写入文件,而文件有一定的大小限制,当文件大小增加到相应的限制时,就会产生一个新的文件,老的文件将只读不写。在任意时间点,只有一个文件是可写的,在Bitcask模型中称其为active data file,而其他的已经达到限制大小的文件,称为older data file,如下图:
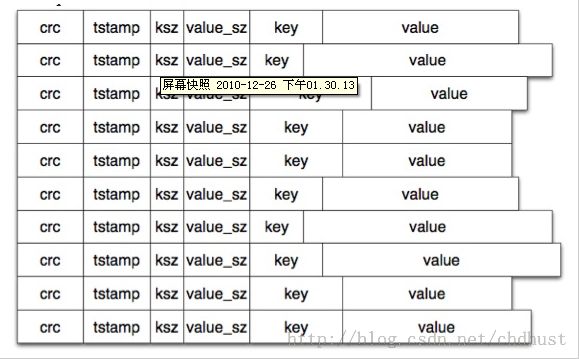
文件中的数据结构非常简单,是一条一条的数据写入操作,每一条数据的结构如下:
上面数据项分别为key,value,key的大小,value的大小,时间戳(应该是),以及对前面几项做的crc校验值。(数据删除操作也不会删除旧的条目,而是将value设定为一个特殊的值以作标示)
数据文件中就是连续一条条上面格式的数据,如下图:
好了,上面是日志型的数据文件,如果数据文件这样持续的存下去,肯定是会无限膨胀的,为了解决个问题,和其他日志型存储系统一样Bitcask也有一个定期的merge操作。
merge操作,即定期将所有older data file中的数据扫描一遍并生成新的data file(没有包括active data file 是因为它还在不停写入),这里的merge其实就是将对同一个key的多个操作以只保留最新一个的原则进行删除。每次merge后,新生成的数据文件就不再有冗余数据了。
2.基于hash表的索引数据
上面讲到的是数据文件,日志类型的数据文件会让我们的写入操作非常快(日志型的优势之一是将磁盘当作磁带,进行顺序读写的效率非常高,可以参见这里),而如果在这样的日志型数据上进行key值查找,那将是一件非常低效的事情。于是我们需要使用一些方法来提高查找效率。
例如在Bigtable中,使用bloom-filter算法为每一个数据文件维护一个bloom-filter 的数据块,以此来判定一个值是否在某一个数据文件中。
而在Bitcask模型中,我们使用了另一种方法,使用了一个基于hash表的索引数据结构。
在Bitcask模型中,除了存储在磁盘上的数据文件,还有另外一块数据,那就是存储在内存中的hash表,hash表的作用是通过key值快速的定位到value的位置。hash表的结构大致如下图所示:
hash表对应的这个结构中包括了三个用于定位数据value的信息,分别是文件id号(file_id),value值在文件中的位置(value_pos),value值的大小(value_sz),于是我们通过读取file_id对应文件的value_pos开始的value_sz个字节,就得到了我们需要的value值。整个过程如下图所示:
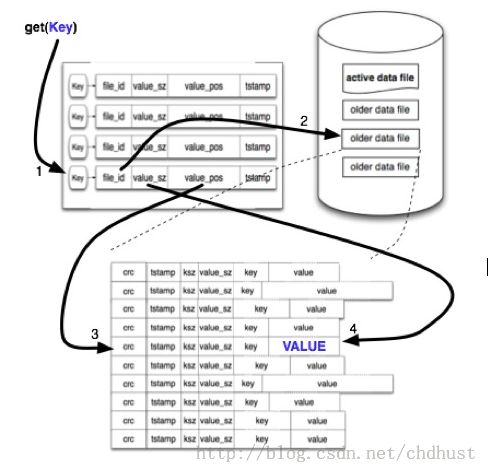
由于多了一个hash表的存在,我们的写操作就需要多更新一块内容,即这个hash表的对应关系。于是一个写操作就需要进行一次顺序的磁盘写入和一次内存操作。
3.有用的hint file
至此,Bitcask模型基本上已经讲述完成,而这一节讲到的hint file,则是一个有用的技巧,本人认为并不一定是Bitcask模型的必须特性。
从上面我们可以知道,我们称其为索引的hash表,是存储在内存中的,虽然在各自的实现中可以做一些持久化的保证,但是Bitcask模型中并不对在断电或重启后的hash表数据不丢失做出保证。
因此,如果我们不做额外的工作,那么我们启动时重建hash表时,就需要整个扫描一遍我们的数据文件,如果数据文件很大,这将是一个非常耗时的过程。因此Bitcask模型中包含了一个称作hint file的部分,目的在于提高重建hash表的速度。
我们上面讲到在old data file进行merge操作时,会产生新的data file,而Bitcask模型实际还鼓励生成一个hint file,这个hint file中每一项的数据结构,与data file中的数据结构非常相似,不同的是他并不存储具体的value值,而是存储value的位置(像在hash表中的一样),其结构如下图:

这样,在重建hash表时,就不需要再扫描所有data file文件,而仅仅需要将hint file中的数据一行行读取并重建即可。大大提高了利用数据文件重启数据库的速度。
三. Bitcask使用的场景
- 适合连续写入,随机的读取,连续读取性能不如Btree
- 记录的key可以完全的载入内存
- value的大小比key大很多,否则意义不大
- key/value存储结构