1.导入BeautifulSoup库
from bs4 import BeautifulSoup
2.使用open()函数打开本地页面
with open('./web/new_index.html','r') as wb_data:
3.使用BS构造解析文件并输出解析结果
with open('./web/new_index.html','r') as wb_data:
Soup = BeautifulSoup(wb_data,'lxml')
print(Soup)
运行后读出的是所有的网页信息,接下来去找我们需要的信息并描述爬取的元素位置
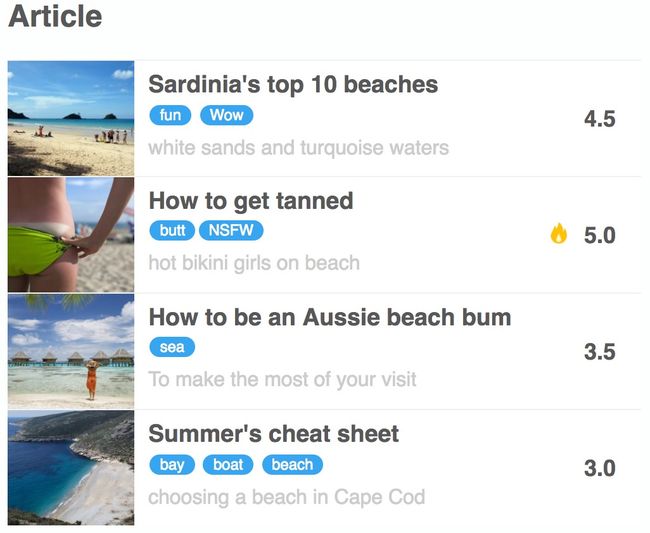
E674E70A-610E-40A1-AECB-3CE6BD5B0251.png
可以看到这个网页上每一个条目上面有五个元素,分别是图片、标题、分类标签、描述、评分。现在把它们一一对应的爬取下来。
4.使用chrome浏览器copy selector获取每个元素的CSS Selector
(首先找到页面对应元素的位置右击选择检查)

91C209FA-FBEE-4BAB-85B1-0CEE1908E5C7.png
以下是五个元素的CSS Selector
body > div.main-content > ul > li:nth-child(1) > div.rate > span
body > div.main-content > ul > li:nth-child(1) > div.article-info > p.description
body > div.main-content > ul > li:nth-child(1) > div.article-info > p.meta-info > span:nth-child(2)
body > div.main-content > ul > li:nth-child(1) > div.article-info > h3 > a
body > div.main-content > ul > li:nth-child(1) > img
因为一个网页中元素是多个的,上述的CSS Selector是单一元素的,所以我们要去掉描述具体位置的信息(比如nth-child(1)),还有,cates(分类标签)如果直接定位到span会打乱它与文章的多对一的关系,导致输出后只会显示一个分类标签,而实际上应该有两个或者更多的标签,所以我们需要在它的父级元素p.meta-info就应该停下来,OK,写入程序后如下
with open('./web/new_index.html','r') as wb_data:
Soup = BeautifulSoup(wb_data,'lxml')
images = Soup.select('body > div.main-content > ul > li > img')
titles = Soup.select('body > div.main-content > ul > li > div.article-info > h3 > a')
descs = Soup.select('body > div.main-content > ul > li > div.article-info > p.description')
rates = Soup.select('body > div.main-content > ul > li > div.rate > span')
cates = Soup.select('body > div.main-content > ul > li > div.article-info > p.meta-info')
print(images,titles,descs,rates,cates,sep='\n----------------\n')
5.筛选并释放每一个标签的所需信息
for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates):
data = {
'title':title.get_text(),
'rate':rate.get_text(),
'desc':desc.get_text(),
'cate':list(cate.stripped_strings),
'image':image.get('src')
}
print(data)
上面有两点要注意,第一点:image的信息并不是文本,所以不能用get_text(),而是直接用get('src')获取图片的路径信息。第二点:由于cate(分类标签)筛选的时候是在它的父级元素停下来的,所以应当使用stripped_strings方法,这个方法可以获取到父级元素下的所有子元素,这样我们就可以得到所有的cate,再将它放入到一个list()中。
6.小拓展,将数据统一放入一个列表中,并循环筛选出评分大于3分的文章
from bs4 import BeautifulSoup
info = []
with open('./web/new_index.html','r') as wb_data:
Soup = BeautifulSoup(wb_data,'lxml')
images = Soup.select('body > div.main-content > ul > li > img')
titles = Soup.select('body > div.main-content > ul > li > div.article-info > h3 > a')
descs = Soup.select('body > div.main-content > ul > li > div.article-info > p.description')
rates = Soup.select('body > div.main-content > ul > li > div.rate > span')
cates = Soup.select('body > div.main-content > ul > li > div.article-info > p.meta-info')
# print(images,titles,descs,rates,cates,sep='\n----------------\n')
for title,image,desc,rate,cate in zip(titles,images,descs,rates,cates):
data = {
'title':title.get_text(),
'rate':rate.get_text(),
'desc':desc.get_text(),
'cate':list(cate.stripped_strings),
'image':image.get('src')
}
print(data)
info.append(data)
for i in info:
if float(i['rate'])>3:
print(i['title'],i['cate'])