Mongodb
该博客基于大数据存储MongoDB实战指南.pdf
提取码:zkil
查询优化
查询优化的目的就是找出慢的查询语句,分析慢的原因,然后优化此查询语句
1. MongoDB对于超过100ms的查询语句,会自动输入到日志文件里面。
------查看Mongodb的日志文件找出慢查询,
100mss阈值过大,可以通过mongod的服务启动选项slowms来设置
2. 打开数据库的监视功能,默认关闭
--- db.setProfilingLevel(level,[slowms])
参数level是监视级别
0 关闭数据库的监视功能
1 只记录慢查询
2 记录所有的操作
slowms 可选参数
设定慢查询的阈值
所有监视的结果都将保存到一个特殊的集合system.profile
索引不能过大,保证全部保存在内存中,而不是被移动到磁盘文件上会影响查询性能,
监控一个查询是否用到索引,可以在查询语句后用explain命令
命名规则 _id
Mongodb中的主键值类型为objectID类型,能更好支持分布式存储
Object ID类型的值由12个字节组成,
前面4个字节表示的是一个时间戳,精确到秒
紧接着的3个字节,表示机器唯一标识
接着2个字节,表示进程id
最后3个字节,是一个随机的计数器
修改语句(update)
数据库修改语句分为两种,
一种是只针对具体的目标字段,其他不变
另一种是取代性,即修改具体目标字段后,其他的字段会被删除
db.collection.update(query,update,,
值得关注的是
upsert,boolen类型,默认值为false。
当值为true时,update方法将更新匹配到的记录,
如果找不到匹配的文档则将插入一个新的文档到集合
multi ,boolen类型,默认值为false
表示是否更新匹配到的多个文档,默认值为false,
当为true时,update方法将更新所有匹配到的文档
删除语句
db.collection.remove(
, )
需要注意的时remove没有指定任何参数,它将删除集合中的所有文档,但是不会删除集合对应的索引数据
需要删除数据和集合索引,可以使用drop
justOne 删除数据的数量,默认全部
1 只删除第一条
锁机制
mongodb通过锁机制来保证数据的完整性和一致性,mongodb利用读写锁来支持并发操作,读锁可以共享,写锁具有排它性
MongoDB在每一个数据库上实现锁的粒度
查询产生读锁,增删改查产生写锁,
默认情况下在前台创建索引会产生写锁、聚集aggregate操作读锁等
Journaling日志功能
Mongodb存在两种日志,log日志和Journaling日志
log日志:简单记录数据库在服务器上的启动信息,
慢查询记录,数据库异常信息,
客户端与数据库连接、断开等信息。
Journaling日志: 保证数据库服务器在意外断电、自然灾害等情况下数据的完整性
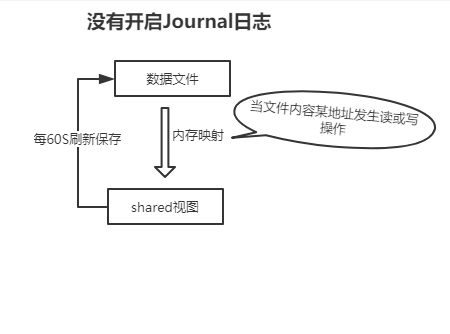
两个重要的存储视图 private view和shared view
shared view :数据的读写,对应的磁盘文件地址映射到shared,数据的改变影响到shared,每60S刷新数据到磁盘文件
private view : 保存数据改变的信息
Jaurnaling工作原理
1.在没有开启journaling日志的情况
-
开启journaling日志的情况
 2.jpg
2.jpg
聚合分析
主要提供三种对数据进行分析计算方式 :
管道模式、MapReduce、简单函数和命令
1. 管道模式
db.books.aggregate(
[
{ $match:(status:"normal") },
{ $group:{_id:'$book_id',total:($sum:'$num')} }
]
)
常用的管道操作符
$match 过滤文档,只传递匹配的文档到管道中的下一个步骤
$limit 限制管道文档的数量
$skip 跳过指定数量的文档,返回剩余的文档
$sort 对所有输入的文档进行排序
$group 对所有文档进行分组然后计算聚合结果
$out 将管道中的文档输出到一个具体的集合中,这个必须是管道操作中的最后一步
与$group操作一起使用的计算聚集值得操作符
$first 返回group操作后得第一个值
$last 返回group操作后得最后一个值
$max 返回group操作后得最大值
$min 返回group操作后得最小值
$avg 返回group操作后得平均值
$sum 返回group操作后所有值得和
截取mysql和mongodb中聚合地差异

2. MapReduce模式聚集
理解不足,具体查看书籍或文档
3. 简单聚集函数(group不懂)
管道模式和MapReduce模式都是重型武器,基本上可以解决数据分析中的所有问题,
但有时在数据量不是很大的情况下,直接调用基于集合的函数会更简单
distinct函数 用于返回不重复的记录,返回值是数据
db.orders.distinct(key,)
count函数 用于统计查询返回的记录总数
db.collection.find().count()
group函数 返回的结果集不能大于16MB,
不能在分片集群上进行操作且group不能处理超过10000个唯一键值。
如果我们的聚集操作超过了这个限制,只有使用上面介绍的管道聚集或MapReduce方案。
db.collection.group({
key : ...,
initial : ... ,
reduce : ... [cond: ... ]
})
实例:("_id" : 2, "value" : 100 }
需要统计_id小于3,按照_id分组求value值的和
db.books.group({
key: { _id: 1 },
cond: { _id: { $lt: 3 } },
reduce: function(cur, result{
result.count += cur.count
}
initial: { count: 0 }
})
复制集
Journaling日志提供数据恢复的功能,单通常只针对单个节点,保证单节点数据的一致性
复制集通常由多个节点组成,每个节点除了Journaling日志恢复功能外,
整个复制集还具有故障自动转移的功能,保证数据库的高可用性。
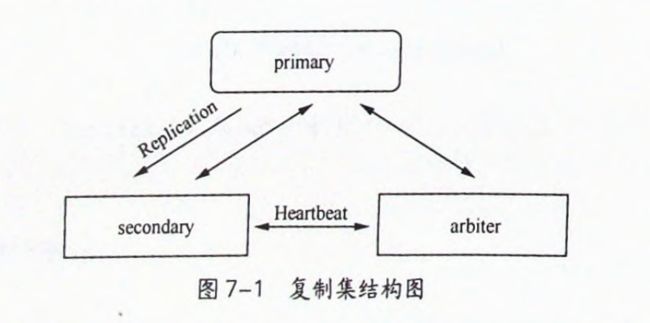
复制集描述
复制集最少包含三个节点,其中一个必须是主节点
primary节点 负责数据的读写
seconda'r节点 备份primary节点上的数据
ariter节点 不参与备份与数据读写,但在primary节点故障时,选择一个新primary节点
1.1 数据同步
主节点集合
rs0:PEIMARY>show collections
//
oplog.rs #-------> 实现复制集间数据同步的(核心部分)
slaves #保存的是需要从primary节点同步数据的secondary节点
startup_log #mongod实例每一次的启动信息
system.indexes #当前数据库(local)上的所有索引信息
system.replset #复制集的成员配置信息
secondary节点集合
存在me集合 #保存了实例本身所在的服务器名称
minvalid集合 #保存对数据库的最新操作的时间截
#没有slaves集合,其他都和主节点一样
secondeary节点利用oplog.rs集合对比节点间的差异性,进行同步

oplog.rs集合特性
大小固定的 capped类型的集合
32位系统默认50MB,64位系统默认5%的空闲磁盘空间大小(oplogSize可设置大小)
优点:
充当循环使用的缓冲区
缺点:
当一个secondary节点因为宕机,长时间不能恢复,
(期间大量的写操作在primary节点上,会把oplog.rs集合刷新一遍)
导致secondary没有及时同步信息
1.2 故障转移
心跳(lastHeartbeat),MongoDB依靠它实现自动故障转移;
mongod实例每隔两秒就向其他成员发送一个心跳包并且通过rs.staus()中返回的成员的'health‘值来判断成员的状态,如果primary不可用,开始选举
1.2.1 secondary节点失败
secondary节点失败,然后过一段时间后重启,自动同步(时间不能无限期,否则就会导致oplog.rs集合严重滞后问题,需要手动才能同步)

1.2.2 primary节点失败,故障转移发生
primary宕机,选举一个secondary节点作为primary节点
原来的primary节点激活后,变成secondary节点,oplog也会被同步更新
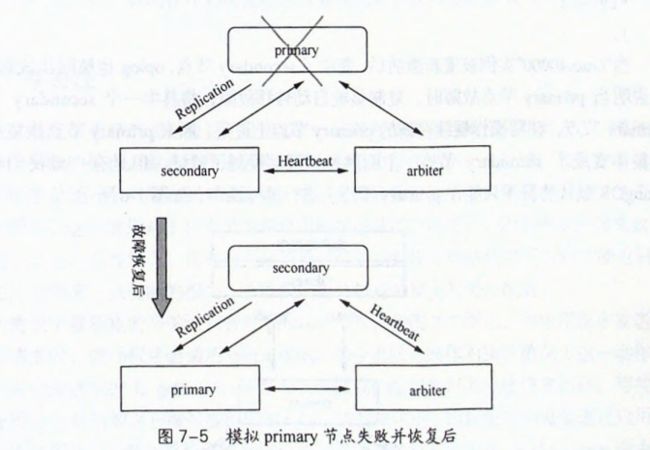
默认情况下primary节点只能在primary节点上进行读写操作
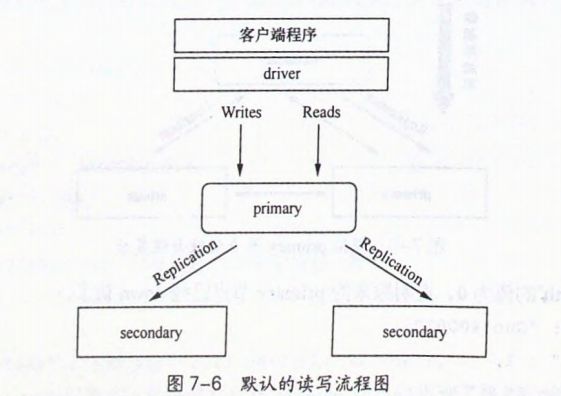
在primary节点失效、复制集发生故障转移时,复制集先关闭与所有客户端的socket连接,
驱动程序将返回一个异常,程序收到这个异常,需要应用程序的开发人员去处理异常,同时驱动程序会尝试与primary节点建立连接(对程序员透明)
》》》异常期间可能发生读写操作,程序员需要知道读写结果
1.3 写关注
写关注,它能判断哪些写操作成功写入,哪些失败,默认情况写关注只针对primary节点
当应用程序发送一个写操作请求时
驱动程序会调用getLastError命令返回写操作的执行情况(对程序员透明)
getLastError默认配置项
local.system.replset.settings.getLastErrorDefaults
1. 选项 w
-1 驱动程序不会使用写关注,忽略所有网络或socket错误
0 驱动程序不会使用写关注,只返回网络和socket的错误
1 驱动程序使用写关注,但只针对primary节点
(这个配置项对于复制集或mongod实例默认写关注配置)
>1 写关注将针对复制集的n个节点,
当客户端收到这些节点的反馈信息后,命令才返回给客户端继续执行
2. 选项 wtimeout
指定写关注应在多长时间内返回,如果你没有指定这个值,
复制集可能因为不确定因素导致应用程序的写操作一直阻塞
1.4 读参考
MongoDB将客户端的读请求路由到复制集中指定的成员上,默认为primary节点
可修改到其他节点上,但由于secondary节点同步会有时间差,可能导致从secondary节点上读到的数据不是最新的(对于是实时性要求不高影响不大)
特殊性:
》》》所有读参考并不能提高系统读写的容量
每一个secondary节点都会从primary节点同步数据,
所有secondary节点一般有相同的写操作流量,同时priamry节点上的读操作量也并没有减少,
优点:
使得客户端的读者请求路由到最佳的secondary节点上(如最近的节点),提高客户端的读效率
MongoDB驱动支持的读参考模式如下
1. primary模式(默认)
所有读请求都路由到复制集中的primary节点上
如果priamry节点故障了,读操作将会产生一个错误或抛出异常
2. priamarypreferred模式
在大多数模式下,读操作从primary节点上进行,如果primary节点故障无法读取,读操作将被路由到secondary节点上
3.secondary模式
读操作只能从secondary节点上进行,如果没有可用的secondary节点,读操作将产生错误或抛出异常
4. secondaryPreferred模式
在大多数情况下,读操作在secondary节点上进行,但当复制集中一个primary节点时,读操作将用这个复制集的primary节点
5. nearest模式
读操作从最近节点上进行,有可能是primary节点,也有可能是secondary节点,并不会考虑节点的类型
1、 MongoDB向复制集的primary节点写操作,会产生两个锁,一个是集合数据所在的数据库上的写锁,还有一个是local数据库上的写锁
2、 在secondary节点采用周期延迟批量写入的方式,secondary节点当应用写操作变化时,会锁在数据库,不允许读操作发生
分片集群
MongoDB使用内存映射文件的方式来读写数据库,对内存的管理由操作系统来负责。
分片就是内存三级索引,没有分片前【没索引,一级索引(对应内存)】,没分片【有索引,二级索引(对应内存)】
1、 当数据库的索引和数据文件远大于内存的时候,
操作系统会频繁地进行内存交换,导致整个数据库系统的读写性能下降
2、 在数据库内存使用率达到一定程度时就要考虑分片了,通过分片使整个数据库分布在各个片上,
每个片拥有数据库的一部分数据,从而降低内存使用率,提高读写性能。
分片集群中的一个片shard实际上就是一个复制集,当然一个片也可以是单个mongod实例
分片集群主要由mongos路由进程、复制集组成的片shards、一组配置(Configrure)服务器构成
mongos路由进程是一个轻量级且非持久性的进程。
轻量级表示它不会保存任何数据库中的数据
它只是将整个分片集群看成一个整体,使分片集群对整个客户端程序来说是透明的。
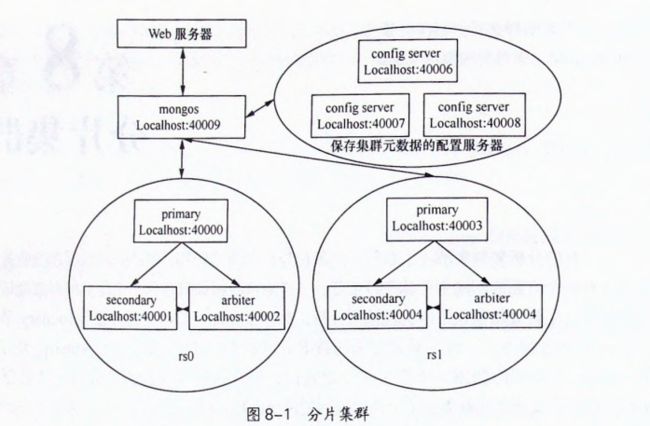
1.1 分片配置(细节参考大数据存储MongoDB.pdf)
1、配置复制集rs0并启动
配置复制集rs1并启动
2、配置configure服务器1并启动
配置configure服务器2并启动
配置configure服务器3并启动
configrure服务器也是一个mongod进程,只是它上面的数据库以及集合是特意分给分片集群用
3、配置mongos路由服务器并启动
4、添加各分片到集群
前面完成两个片(复制集)、三个配置服务器、一个路由服务器且它知道从哪些配置服务器上同步元数据(configdb = Guo:4006,GUO:4007,GuO:40008 )
5、最后通过命令sh。status()检查上面配置是否正确
集群中,系统默认创建一个config数据库,且这个数据库只存在于三个配置服务器上
config数据库中的集合包含了整个集群的配置信息
mongos > show collections
changelog 保存被分片的集合的任何元数据的改变,例如chunks的迁移、分割等
Chunks 保存集群中分片集合的所有块的信息,包含块的数据范围与块所在的片。
Databases 保存集群中的所有数据库,包含分片与未分片的。
Lockpings 保存跟踪集群中的激活组件。
locks 均衡器balancer执行时会生产锁,在此集合中插入一条记录。
mongos 保存了集群中所有路由mongos的信息。
Settings 保存分片集群的配置信息,如每个chunk的大小(64MB)、均衡器的状态。
Shards 保存了集群中的所有片的信息。
system.indexes 保存config数据库中的所有索引信息。
Version 保存当前所有元信息的版本。
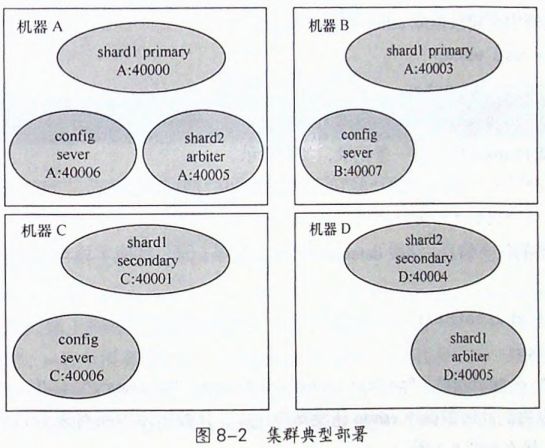
实际部署问题,从前面的配置中,至少需要9个mongod实例进程(不懂)
通过图8-1和前面的分析可知,一个生产环境最少需要9个mongod实例进程,一个mongos进程实例,
理论上说最少需要由10台机器才能组成。
但是这些进程中有些并不需要很多软硬件资源,它们可以与其他进程共存部署在同一个机器上,
如复制集中arbiter进程、mongos进程可以部署到应用程序所在的服务器,
综合考虑后我们可以得到如图8-2所示的典型部署
1.2 分片工作机制
MongoDB的分片基于范围的,也就是说任何一个文档一定位于指定片键的某个范围内,
一定片键选择好后,chunks就会按片键来将一部分documents从逻辑上组合在一起
1、使得数据库支持分片 sh.enableSharding('db_name')
2、选择所在片键上创建一个索引,如果集合初是没有任何数据,
则MongeDB会自动在所选的片键上创建一个索引(假设文档users中存在‘city’)
db.users.ensureIndex({city:1})
3、使集合分片 sh.ShardCollection("db.users",{city:1})
4、查看状态 sh.status()
1.3 集群平衡器
当一个被分片的集合的所有chunk在集群中分布不均匀时,
平衡器就会将chunk从拥有最大数量块上迁移到拥有最少数据块的片上
1.4 片键选择策略
1、升序字段片键 _id 以这个字段作为片键,
可能出现所有写操作将被路由到同一个片的同一个chunk上出现局部热点,没有达到负载均衡的目的
2、完全随机的片键 由于太过于随机,导致写操作被分散到整个集群上,
维护片键索引时,所有的索引文件将被调入内存,降低系统性能和读性能
3、片键的取值范围有限,假设数据库中存在city字段,并按照city字段进行分片,
由于city字段取值有限,每一个city区间所对应的文档都分割了一个chunk时,这是继续插入大量的文档,
将会出现没有可以再来分割的片键值,每一个chunk将会不断变大但又不能分割,最终导致集群中的数据严重不平衡
好的片键特质
1、分发写操作
2、读操作不能太过随机化(尽量局部化)
3、要保证chunk能一直被分割
例:{city:1,_id:1}作为片键
city字段保证同一个city下面的文档尽可能在同一个片上,即使分布在多个片上,
_id字段也能保证查询或更新操作被定位到同一个单独的片上(局部化),
同时{city:1,_id:1}也保证了chunk总是能被分割,因为_id:1总是在变化
分布式文件存储系统
MongoDB的存储基本单元BSON文档对象,字段值可以是二进制类型
单个BSON对象目前位置最大不能超过16MB,大于16MB需要用MongoDB提供的GridFS功能
1.1 小文件存储
将一个文件转化位二进制值,然后构造一个BSON对象,插入到数据库中
关键依赖:
MongoDB可以存储二进制数据
MongoDB可以部署成分片集群,实现海量数据存储、读写分离
集群中的片可以部署成复制集,保证数据的可靠性
1.2 GridFS文件存储
当上传一个大文件到GridFS系统时,MongoDB自动将文件分割成默认大小为256KB的小块(和集群上的块不同)
然后将这些小块插入到数据库默认的集合fs.chunks中,同时将大文件的元数据信息插入到数据库的集合fs.files中
1.文件上传

- 查看数据库

GridFS不适合小文件的存储,因为从GridFS中读取数据会涉及到两次查询操作

管理与监控
导入和导出(具体看文档)
备份与恢复
备份可以从两个方面进行
一是:从数据库中导出二进制的dump文件进行备份
二是:在文件系统和操作系统的基础下直接进行数据文件的磁盘快照备份
备份与恢复
1.单节点dump备份与恢复(具体看文档)
2.集群dump备份与恢复策略
根据复制集的primary节点和secondary节点的特性,可以锁定secondary节点上的数据库,
在此实例上进行备份,备份后解锁此数据库
操作流程:
1. 禁用平衡器,sh.stopBalancer()
balancer进程在后台维护各个片上数据块数量的均衡,不禁用会导致备份数据的重复或缺失
2. 停止每个片(复制集)上的某个secondary节点利用此节点进行备份;
停止其中某个配置服务器,保证备份时配置服务器上元数据不会改变
3.重启所有停掉的复制集成员,它们会自动从primary节点上的oplog同步数据,最终数据达到一致性
4. 重启分片集群的平衡器
监控
mongostat工具 主要捕获和返回数据库上各种操作的统计
mongotop工具 监控MongoDB实例上最近发生过读写操作的数据库上
每一个集合的读写时间或者在每个数据库上的读写锁时间
数据库命令 serverStatus 查看数据库信息
数据库命令 stats 显示具体某个数据库统计信息的方法
影响性能因数(细节看文档)
1、锁
MongoDB用一个锁确保数据的一致性。但如果某种操作长时间运行,其他请求和操作将不得不等待这个锁,导致系统性能降低。
2、内存
MongoDB通过内存映射数据文件,如果数据集很大,MongoDB将占用所有可用的系统内存。
3、缺页错误
当MongoDB请求的数据不在物理内存中、必须从虚拟内存读取时,就会引起缺页错误。
4、连接数
有时候,客户端的连接数超过了 MongoDB数据库服务器处理请求的能力,这也会降低系统的性能。
权限控制API
MongoDB采用基于角色的权限控制,一个角色时一组权限的集合,
一个权限决定了用户对某个数据库可以有哪些操作动作,用户可能有一个或多个角色
针对所有数据库的角色

针对单个数据库的角色
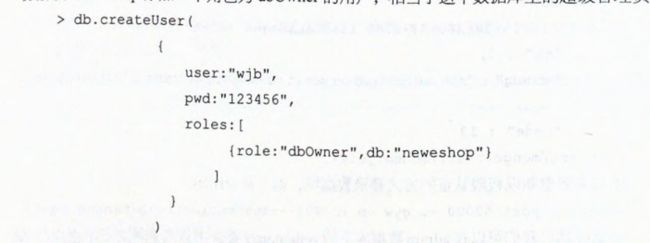
在admin数据库上的system.user集合中可查到记录


dbAdmin角色:维护此数据库上的系统表和监控数据库的命令.
userAdmin角色:维护此数据库上的用户和角色
复制集合集群的权限控制
1、创建一个含有最少6个字符的文件,这个文件件被部署在复制集中的每一个节点上
文件中内容相当于密码,能够作为复制集中各成员间的权限认证
2、启动,在最后每个节点启动时,给mongod加上启动项 --keyFile,路径指向所创建的密码文件
3、分片集群的权限控制在复制集基础上延伸,集群中的每个节点都是一个复制集
集群中的每个mongod和mongos进程启动时都加上keyFile选项,
指向内容相同的密码文件,完成这些设置后,我们就能对整个集群进行统一的权限控制了。