译文:Attention and Augmented Recurrent Neural Networks
循环神经网络是深度学习的主要手段之一,使得神经网络能够处理诸如文本、音频、视频之类的序列数据。 它们可以对源信息进行高级理解、注释序列,甚至从头开始生成新序列!
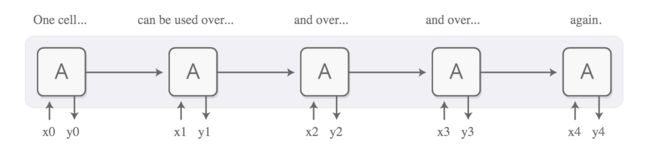
基本的RNN处理长依赖较为困难,但是一个特殊的变体 - LSTM 可以解决这些问题。 已经证明这些模型非常强大,在翻译、语音识别、图像内容提取等在内的许多任务中取得了显着的成果。 这使得循环神经网络在过去几年中变得非常普遍。
正如现在,我们看到越来越多的尝试在添加新的属性来强化RNN,在以下 四个方向特别突出、令人兴奋:
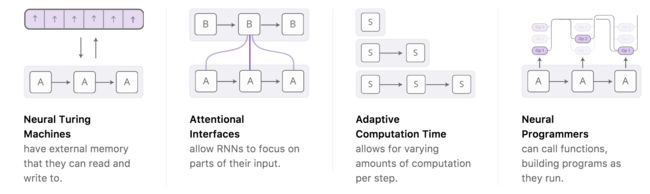
单独来看,这些技术都是RNN的有力扩展,但真正令人惊奇的是它们可以组合起来,看起来似乎只是在更广阔的空间中的点。 此外,他们都依赖于相同的底层技巧——attention。
我们的猜测是,这些“增强型RNN”将在未来几年对扩大深度学习的能力发挥重要作用。
神经图灵机(Neural Turing Machines)
神经图灵机将RNN与外部存储器组合,由于向量是神经网络的自然语言,所谓的外部存储就是一系列向量:

但这些读和写操作如何工作呢? 面临的挑战是我们想让他们有所差异。 特别地,我们希望使它们会因我们读、写的位置的差异而有所差异,所以我们可以学习读和写。 这是一个棘手的问题,因为内存地址是离散的。 NTM(神经图灵机)采取了一个非常聪明的解决方案:在每一步都进行读写操作,只不过程度不同而已。
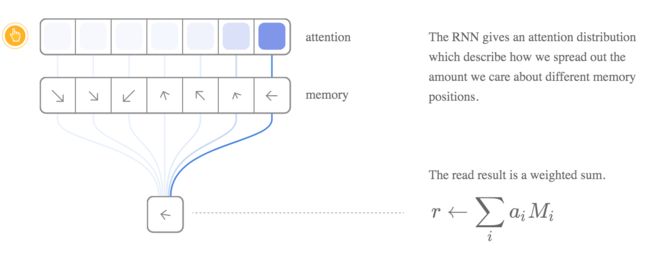
例如,让我们专注于阅操作, RNN不是指定单个位置,而是输出一个“关注分布”,这个分布描述我们如何分配我们关心不同内存位置的数量。 这样,读操作的结果是加权和。
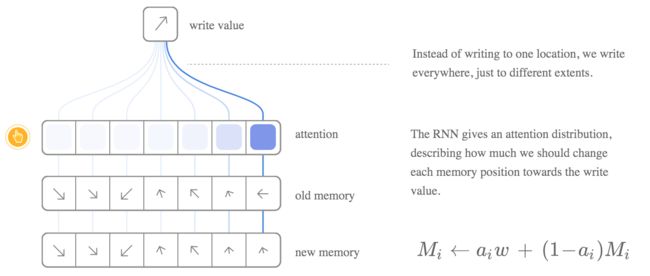
同样地,我们每一步都进行写操作,只是成不不同而已。同样,一个注意力分布描述了我们在每个位置写的多少。 我们将内存中该位置的新值与旧值进行凸起组合,位置信息注意力的权重决定。
但NTM如何决定记忆中的哪些位置将注意力增强? 他们实际上使用了两种不同的方法:基于内容的关注和基于位置的关注。 基于内容的注意力模型允许NTM通过其内存搜索并专注于匹配所需内容的位置,而基于位置的注意力模型允许内存中的相对移动,使NTM能够循环。

这种读写能力允许NTM执行许多简单的算法。 例如,他们可以学习存储一个长序列,然后循环往复执行。 在这样做时,我们可以看到他们读写的内容,以便更好地了解他们在做什么:
他们还可以学习模拟查找表,甚至学习排序数字(尽管它们是欺骗性的)! 另一方面,他们仍然不能做许多基本的事情,如乘法和加法。
自从NTM的论文出来以后,已经出现了一些令人兴奋的论文,探索了类似的方向。 Neural GPU 克服了NTM无法对数字进行加和乘的操作。 Zaremba&Sutskever使用强化学习训练NTM
在某些客观意义上,这些模型可以执行的许多任务。像神经图灵机器这样的模型似乎已经打破了传统模型的限制。
Attentional Interfaces
当我在翻译句子时,我特别注意我正在翻译的单词。 当我录制录音时,我会仔细聆听我正在积极写下的片段。 如果你要我描述我正在坐着的房间,我会盯着正在看的物体。
神经网络可以使用注意力来实现同样的行为,重点放在信息的一部分上。 例如,一个RNN的输出可以作为另一个RNN的输入。 在每个时间点,它关注于另一个RNN的不同位置。
我们希望关注点是可以区分的,所以我们可以学习在哪里集中。 为了做到这一点,我们使了在神经图灵机中相同的技巧:我们专注于各个点,只是程度不同。

注意分布通常是基于内容产生的。 Attending RNN生成一个query,描述它想要关注的内容。 每个item都与这个query做点积以产生分数,这个分数描述了item与query匹配的程度。 将得分加入到softmax中以产生注意力分布。

Attention的一个应用就是翻译。 一个传统的sequence-to-sequence模型必须将整个输入变成单个向量,然后将其扩展回来。 Attention模型规避了这个问题,其通过允许RNN处理输入来传递关于其看到的每个单词的信息,然后RNN生成只和这些词相关的输出。
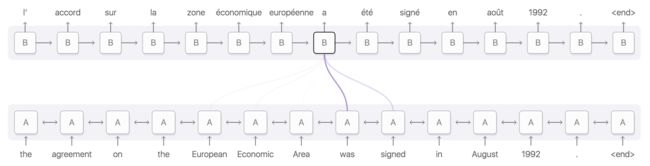
这种Attention RNN有许多其他的应用。 它可以用于语音识别,允许一个RNN处理音频,然后另一个RNN进行关注点处理。

Attention方法的其他用途包括解析文本,它允许模型在生成解析树时查看单词。对于会话建模,在产生回复的时候,模型能够关注于前面的对话内容。
Attention方法也可以在卷积神经网络和RNN之间的接口上使用。 这允许RNN每一步都可以看到图像的不同位置。 一个比较流行的用法是图像文字内容生成。 首先,一个conv net 处理图像,提取高级特征。 然后运行RNN ,生成图像的描述。 在它产生每个单词的过程中,RNN关注于conv net的关于其他部分的解释。 我们可以明确地可视化这一部分:

更广泛地说,只要想要在其输出中具有重复结构的神经网络就可以使用attention方法。
Attention方法是一种非常普遍和强大的技术,并且越来越广泛。
Adaptive Computation Time(自适应)
标准的RNN对于每个时间步长都执行相同的计算量。 这似乎是不太明智的, 当事情很难的时候,应该多思考一下。 这也限制了RNN的时间复杂度为O(n)——对长度为n的待处理数据
自适应计算,是一种为每个步骤执行不同计算量的RNN。 想法很简单即允许RNN对每个时间步骤进行多步骤计算。
为了使网络了解需要执行多少步骤,我们希望步数是可微的, 我们使用以前使用的相同技巧来实现这一点:我们对运行步数产生一个分部,输出是每一步的权重。
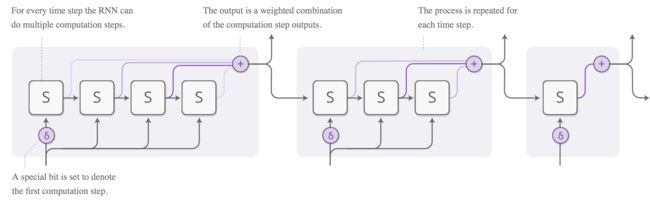
还有一些更多的细节问题,在前面的图表中被省略了。 下面是一个具有三个计算步骤完整图。
There are a few more details, which were left out in the previous diagram. Here’s a complete diagram of a time step with three computation steps.
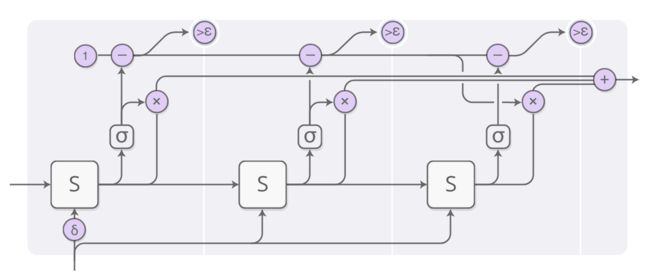
这里看着有点复杂,所以让我们一步一步的分析。 在上层,我们依然运行RNN并输出状态的加权组合:

每个步骤的权重由“停止神经元”决定,它是一个Sigmoid神经元,它观察RNN的状态,并给出了一个停止的权重,我们可以将它们看作是我们应该在该步骤停止的概率。

停止权重的总和是1,所以一路上我们都严格遵循这个限制,当累加的总和和1的差小于阈值epsilon时,我们停止。

当达到停止条件时,可能会有一些残留值( 自适应计算时间是一个新的想法,但我们认为,它与类似的想法将是非常重要的。