上一次写了scrapy-redis分布式爬虫的环境搭建,现在以毒舌电影社区为例子编写毒舌电影社区的分布式爬虫例子。如果对于scrapy-redis的环境搭建不熟悉,可以直接参考 scrapy-redisf实现分布式爬虫;分析毒舌电影社区需要Fiddler进行抓包,这部分可以直接参考 fiddler抓取摩拜单车数据包教程。下面直接给出电影评论接口地址以及参数。
- 1.通过Fiddler抓包分析,可以得到电影评论的接口,以及传递的参数如下,其中count表示每次调用接口返回的点评条数,startIndex就是下一条的起始index,userid是用户id(如果为0,代表用户没有登录)
接口地址:
https://dswxapp.dushemovie.com/dsmovieapi/ssl/daily_recmd/list_daily_recmd_dynamic/3
传递参数:
{"count":"20","startIndex":"0","userId":"0"}
-
-
毒舌电影社区基本架构图,数据库Redis维持公共的requestUrl队列,实现去重和保存爬取到的item,MongoDB保存所有的数据。Master主机首先提取url到redis,slave从中提取url,并且把爬取到url保存会redis。Master同样提取url到redis,并且从中获取url进行爬取。
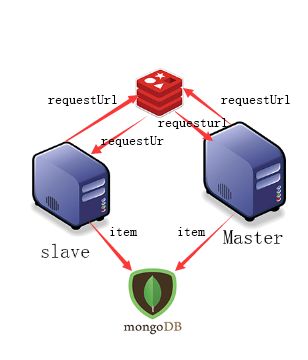 scrapy-redis架构图
scrapy-redis架构图
-
-
- 文件如下:

文件分布
- 4.爬取逻辑spiders源码,spider直接继承scrapy-reids的RedisSpider,保存在Redis数据库的DuzhemovieSpider的starturl中:
# -*- coding: utf-8 -*-
import json
from scrapy import Request
from time import sleep
import logging
from scrapy_redis.spiders import RedisSpider
class DuzhemovieSpider(RedisSpider):
name = "duzhemovie"
# allowed_domains = ["dushemovie.com"]
# start_urls = ['http://dushemovie.com/']
redis_key:"DuzhemovieSpider:start_urls"
url="https://dswxapp.dushemovie.com/dsmovieapi/ssl/daily_recmd/list_daily_recmd_dynamic/3"
postBody={"count":"20","startIndex":"0","userId":"0"}
def start_requests(self):
yield Request(url=self.url,method="POST",body=str(self.postBody),callback=self.parse)
def parse(self, response):
jsonData=json.loads(response.body.decode('UTF-8'))
yield jsonData
while True:
sleep(1)
self.postBody["startIndex"]=str(int(self.postBody['startIndex'])+20)
yield Request(url=self.url,method="POST",body=str(self.postBody),callback=self.parse)
- 5.pipelines保存数据item在远程阿里云自建数据库MongoDB上,因为数据都是json格式,所以item模块没有定义字段值,直接把json格式数据写进MongoDB数据库里面。源码如下:
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import pymongo
from scrapy.exceptions import DropItem
class MongoPipeline(object):
collection_name="users"
def __init__(self,mongo_uri,mongo_db,mongo_user,mongo_pass):
self.mongo_uri=mongo_uri
self.mongo_db=mongo_db
self.mongo_user=mongo_user
self.mongo_pass=mongo_pass
@classmethod
def from_crawler(cls,crawler):
return cls(mongo_uri=crawler.settings.get('MONGO_URI'),mongo_db=crawler.settings.get('MONGO_DATABASE'),mongo_user=crawler.settings.get("MONGO_USER"),mongo_pass=crawler.settings.get("MONGO_PASS"))
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
self.db.authenticate(self.mongo_user,self.mongo_pass)
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
# self.db[self.collection_name].update({'url_token': item['url_token']}, {'$set': dict(item)}, True)
# return item
if item["dynamicDataList"]==None:
raise DropItem("Data is None")
else:
self.db[self.collection_name].insert(dict(item))
return item
- 6.项目设置模块,主要设置MongoDB的地址,用户,密码以及Redis数据库的用户名与密码,以及常见的一些scrapy控制爬取速率和item,middleWare顺序。
lines (94 sloc) 4 KB
# -*- coding: utf-8 -*-
# Scrapy settings for dushe project
#
# For simplicity, this file contains only settings considered important or
# commonly used. You can find more settings consulting the documentation:
#
# http://doc.scrapy.org/en/latest/topics/settings.html
# http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
# http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
BOT_NAME = 'dushe'
SPIDER_MODULES = ['dushe.spiders']
NEWSPIDER_MODULE = 'dushe.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
#USER_AGENT = 'dushe (+http://www.yourdomain.com)'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False
# Configure maximum concurrent requests performed by Scrapy (default: 16)
#CONCURRENT_REQUESTS = 32
# Configure a delay for requests for the same website (default: 0)
# See http://scrapy.readthedocs.org/en/latest/topics/settings.html#download-delay
# See also autothrottle settings and docs
#DOWNLOAD_DELAY = 3
# The download delay setting will honor only one of:
#CONCURRENT_REQUESTS_PER_DOMAIN = 16
#CONCURRENT_REQUESTS_PER_IP = 16
# Disable cookies (enabled by default)
#COOKIES_ENABLED = False
# Disable Telnet Console (enabled by default)
#TELNETCONSOLE_ENABLED = False
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Host': 'dswxapp.dushemovie.com',
'Content-Type': 'application/json',
'Accept-Language':' zh-cn',
'Accept-Encoding': 'gzip, deflate',
'Connection':' keep-alive',
'Accept': '*/*',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 10_0_1 like Mac OS X) AppleWebKit/602.1.50 (KHTML, like Gecko) Mobile/14A403 MicroMessenger/6.5.16 NetType/WIFI Language/zh_CN',
'Referer': 'https://servicewechat.com/wxae1df0a33ef19e00/18/page-frame.html',
'acw_tc':'AQAAAGEFNWv+5AsARUVJ3wWxzmZzc+SK; Path=/; HttpOnly',
'Expires': 'Thu, 01 Jan 1970 00:00:00 GMT',
'di': {"uid":0,"sysType":1,"versionCode":1,"channelCode":"WeChat Small App","lang":"zh_CN","local":"CN","sign":"null"}
}
# Enable or disable spider middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/spider-middleware.html
#SPIDER_MIDDLEWARES = {
# 'dushe.middlewares.DusheSpiderMiddleware': 543,
#}
# Enable or disable downloader middlewares
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html
#DOWNLOADER_MIDDLEWARES = {
# 'dushe.middlewares.MyCustomDownloaderMiddleware': 543,
#}
# Enable or disable extensions
# See http://scrapy.readthedocs.org/en/latest/topics/extensions.html
#EXTENSIONS = {
# 'scrapy.extensions.telnet.TelnetConsole': None,
#}
# Configure item pipelines
# See http://scrapy.readthedocs.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'dushe.pipelines.MongoPipeline': 300,
'scrapy_redis.pipelines.RedisPipeline': 301
}
# Enable and configure the AutoThrottle extension (disabled by default)
# See http://doc.scrapy.org/en/latest/topics/autothrottle.html
#AUTOTHROTTLE_ENABLED = True
# The initial download delay
#AUTOTHROTTLE_START_DELAY = 5
# The maximum download delay to be set in case of high latencies
#AUTOTHROTTLE_MAX_DELAY = 60
# The average number of requests Scrapy should be sending in parallel to
# each remote server
#AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# Enable showing throttling stats for every response received:
#AUTOTHROTTLE_DEBUG = False
# Enable and configure HTTP caching (disabled by default)
# See http://scrapy.readthedocs.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings
#HTTPCACHE_ENABLED = True
#HTTPCACHE_EXPIRATION_SECS = 0
#HTTPCACHE_DIR = 'httpcache'
#HTTPCACHE_IGNORE_HTTP_CODES = []
#HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
HTTPERROR_ALLOWED_CODES = [404]
DOWNLOAD_DELAY = 3
MONGO_URI="remoteAddress"
MONGO_DATABASE='databaseName'
MONGO_USER="username"
MONGO_PASS="password"
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
REDIS_URL = 'redis://username:password@remoteAddress:port'
SCHEDULER_IDLE_BEFORE_CLOSE = 10
SCHEDULER_PERSIST=False
-
爬取的数据展示如下:
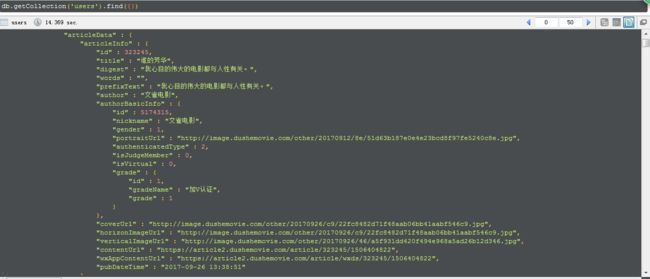 数据库展示
数据库展示
github地址:https://github.com/laternkiwis/duSheCommunity