朴素贝叶斯分类器
朴素贝叶斯
在经典的分类器模型中,Naive Bayes Classifier应该是比较简单的一种了,比之前的决策树要简单得多,但是它虽然简单,但是一点都不简约,在很多情况下它往往能得到比较好的分类效果。
通常的分类问题中,每一个实例都可以用一个特征向量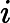
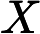
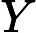
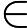
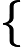
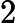
朴素贝叶斯模型的基本思想就是,通过直接从样本中学习得到条件概率分布
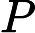
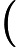


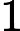
当我们需要判断一个未知实例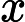
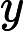
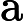
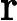
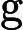
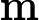
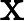
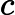
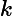
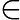
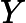
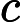
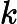
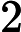
上面的第二个等号之所以成立,是因为
在上面的最后一个等式中,
对于后验概率来说,我们可以将其展开:
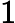
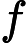

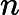
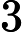
上式中的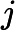
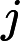
上式中的等号是严格成立的,但是不幸的是,如果根据上述的公式直接计算后验概率,那么空间复杂度是呈指数增长的,真实计算时是完全不可行的。假设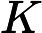
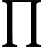
为了解决计算复杂度的问题,朴素贝叶斯模型对条件概率分布作了条件独立性的假设,因为这是一个很强的假设,朴素贝叶斯也是因此而得名的。条件独立性假设是指:
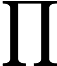

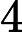
上述公式中的第二个公式是朴素贝叶斯中最重要的核心部分,它是指每个属性在给定分类结果的条件下是相互独立的
经过条件独立性的假设的化简,原来的优化目标就可以写成:
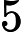
经过这样的化简之后,我们需要学习的参数个数就变成了
朴素贝叶斯法实际上学习到生成数据的机制,所以属于生成模型。条件独立假设等于是说用于分类的特征在雷确定的条件下都是条件独立的,这一假设使得朴素贝叶斯变得简单,但有时会牺牲一定的分类准确率.
参数估计
经过上面的分析,我们现在需要从数据中学习的分布有以下两个:
极大似然估计
利用极大似然估计是比较容易从数据中学习上述两个概率分布的。
先验概率
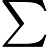
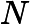
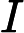
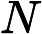
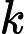
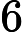
其中
设
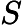
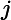
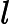
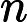
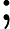
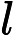
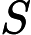
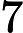
其中,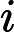
贝叶斯估计
但是,从上面的估计方法中,我们可以发现,其实极大似然估计还是有一些问题的,如果
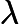
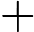
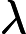
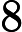
上式中的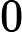
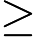
同样,先验概率的贝叶斯估计是:
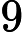
具体实现
朴素贝叶斯算法的Python简单实现如下:
#coding:utf-8 """ Program: Naive Bayes Algorithm Description: Author: Flyaway - [email protected] Date: 2014-01-13 20:30:29 Last modified: 2014-01-13 21:58:27 Python release: 3.2.3 """ from collections import Counter class NaiveBayes: def __init__(self,dataset,labels,lam = 1): self.dataset = dataset self.labels = labels self.instance_num = len(dataset) self.lam = lam #lambda self.count = {} self.prior = {} def getPrior(self,cla): ''' get the prior probability ''' member = self.prior[cla] + self.lam denominator = self.instance_num + len(self.prior) * self.lam return float(member/denominator) def train(self): self.prior={} m = Counter(self.labels).most_common() for item in m: self.prior[item[0]] = item[1] for i,vector in enumerate(self.dataset): cla = self.labels[i] if cla not in self.count: self.count[cla] = [{}] * len(vector) for j,feat in enumerate(vector): self.count[cla][j][feat] = self.count[cla][j].get(feat,0) + 1 def getPost(self,cla,index,feat): ''' get the post probability ''' member = self.count[