从去年开始,陆陆续续学习了大半年的机器学习,现在是时候做个总结了。
在以往的编程经验里面,我们需要对于输入有一个精确的,可控制的,可以说明的输出。例如,将1 + 1作为输入,其结果就是一个精确的输出 2 。并且不论怎么调整参数,都希望结果是2,并且能够很清楚的说明,为什么结果是2,不是3。这样的理念在传统的IT界,非常重要,所有的东西就像时钟一般精确,一切都是黑白分明的。由于这种严格的输入输出,衍生出很多对于程序的自动测试工具,你的程序无论怎么运行,都应该在相同输入情况下,得到相同的,准确的,精确的输出。
但是,如果你进入机器学习的世界,则一切都是基于一个准确率。换句话说,你的模型,允许是不完美的,1 + 1,结果可以是 2.01,也可以是1.98。有时候,如果你的模型要追求完美,则可能出现过拟合的可能性。也就是说,由于你的模型太过于完美,使得模型可以很好的匹配训练用数据,反而失去了通用性,在数据发生变化的时候,发生错误。
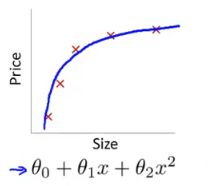
举个例子来说吧,如果一个男孩子说喜欢某个女孩子,这个女孩子身高178,籍贯是辽宁抚顺,专业是计算机。如果机器学习发生过拟合的时候,它就会输出这样一个模型
如果 身高 = 178 ,籍贯 = 抚顺 ,专业 = 计算机 则喜欢。
这个模型如果用来匹配一个个例,则这个模型是完美的!
但是,如果这个女孩子身高是179呢,这个模型会告诉你,这个男孩子不喜欢她。其实,对于男孩子来说,178和179其实没有什么很大的区别。但是由于计算机想精确给出男孩子喜欢女孩子的模型,所以,计算机做出了过拟合的模型。
当然,一般来说,计算机的模型应该是有弹性的。
身高在 【175,185】之间
籍贯是 东北
专业是 IT相关的
这样的话,模型虽然会把一些男孩子不喜欢的女孩子也错误的标识出来,但是大部分的样本还是可以比较好的预测出来的。
机器学习追求的不是100%的正确,而是一个可以容忍的正确率。
当然,在某些时候,还需要一些风险策略的,例如,在人工智能判断一个用户是否能够发给信用卡的时候,并不是说,这个人51%的可能性是一个讲信用的人,就发卡,而是这个人95%是讲信用的人的时候,才发卡的。机器给出的只是一个估计值,最后还是要人工控制风险的。
机器学习,很多人认为是一个高科技的IT技能,其实,一个好的机器学习模型,领域里的业务知识还是很需要的。而且现在很多工具可以帮助大家建立程序,完全不需要什么编程的技能,只需要给机器“喂”数据,调节参数,就可以获得结果了。
给机器“喂”什么数据,那些数据的特征值是有用的,那些特征值没有价值,这个就是领域专家思考的问题了。
男孩子喜欢女孩子,这时候 颜值,身材,脾气 可能是比较关键的特征值,喜欢可口可乐还是百事可乐则变得基本没有什么价值。如果你的数据里面,都是女孩子喜欢那个牌子的可乐,这样的数据训练出来的模型没有任何意义。当然,如果你有很多特征值,还是有一些自动化的计算帮你挑选用那些特征值的(主成因分析)。
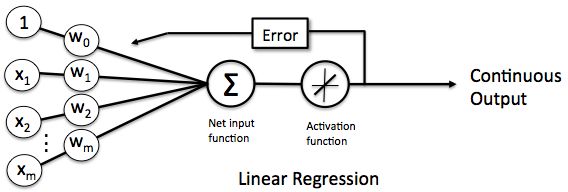
在机器学习中,有一些复杂的概念,往往都是由一个简单的概念扩展开来的。
卷积神经网络为首的一些神经网络的概念,都是从感知机这个小家伙来的。
感知机的输出,是由输入和权重决定的,在监督学习中,输入和输出是已知的,然后机器学习通过不停的调整权重,使得感知机的输出(模型)和实际的输出(样本)尽量一致。这个过程中,学习结果就是这些权重,权重知道了,模型就定下来了。一个最简单的感知机的应用就是线性单元。
零基础入门深度学习(1) - 感知器
零基础入门深度学习(2) - 线性单元和梯度下降
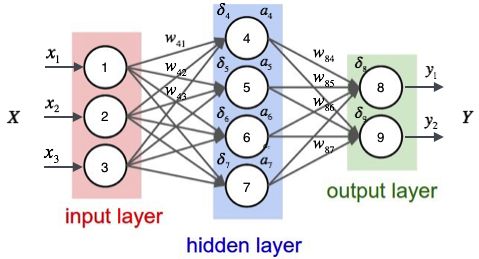
单个感知机是弱小的,但是,如果感知机有成千上万个,然后一层一层一层叠加起来呢。。这些小家伙就变成强大的神经网络了
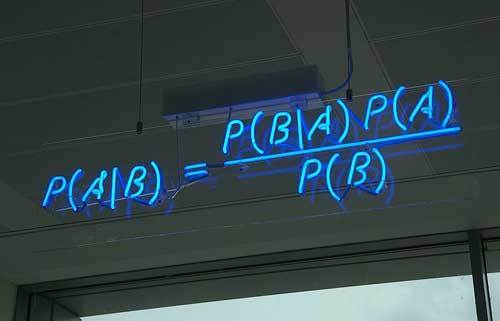
贝叶斯,马尔科夫同志则共享了很多关于概率的机器学习。
贝叶斯最大贡献如下。
在“你家隔壁住着老王(B)”的前提下,“你的孩子长得像隔壁老王(A)”的概率
等于“你的孩子长得像隔壁老王(A)”的前提下,“你家隔壁住着老王(B)”
乘以:“你的孩子长得像隔壁老王(A)”的概率(和隔壁是否住着老王无关)
除以:“你家隔壁住着老王(B)”的概率
 当然这个正统说法要牵涉到先验概率,后验概率。
当然这个正统说法要牵涉到先验概率,后验概率。
从最简单的伯努利分布,到关于分布的分布的变态级别的狄利克雷分布,很多机器学习都在追求模型最符合抽样的分布概率。换句话说,就是希望从概率学上看,我们做出来的模型,和我们看到的样本之间,看上去是最相似。(最大似然)
例如,我们要做一个模型,表示抛一枚硬币有多大概率正面向上。如果我们的样本告诉我们,10次里面,有7次正面向上,则我们说这枚硬币70%会出现正面向上。这个模型的结论和样本之间,从概率学上看是最有可能的。
我们做的模型,就是追求和实际样本的结果,在概率学上看,是最有可能发生的情况。
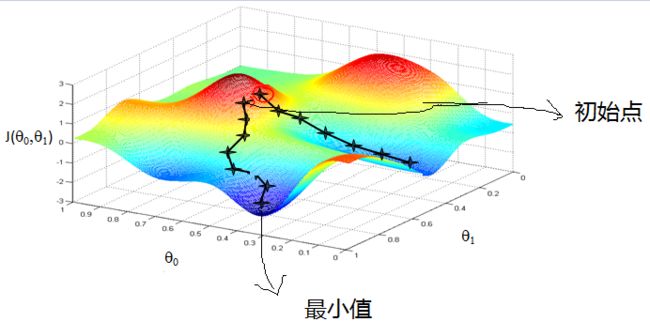
最快梯度下降则几乎出现在所有的迭代算法中。
为什么梯度下降特别重要,因为大部分的算法都是尽可能将损失函数降低,怎么才能将损失函数降低,就是不停调整参数(权重),权重调整的方向,和梯度下降的方向是一致的。当然,最快梯度下降有可能不会收敛到全局最低点。(能否收敛到全局最低点,和初始位置有关)
机器学习和自然语言处理也是密不可分的。在很多自然语言处理中,将大量使用机器学习的概念。马尔可夫链和条件随机场,狄利克雷分布这些都是自然语言处理的基础理论。
关注公众号 TensorFlow教室 深度学习,机器学习,自然语言处理。