编译原理:实现简单数学公式排版
这是大三下上编译原理时老师要求做的大作业
1、实验具体要求 [题目和测试程序来自 李卫海老师:http://staff.ustc.edu.cn/~whli]
一、 符号集
小写字母a、b、c、d、e、f、g、h、i、j、l、m、n、o、p、q、r、s、t、u、v、w、x、y、z
数字0、1、2、3、4、5、6、7、8、9
特殊符号:\、(、)、{、}、_、^、$
分隔符:空格、换行
二、 记号定义
标识符:由字母开始,由字母和数字组成
数字:无符号整型数
三、 语言规则
- 句子:
$$α$$
- 上下标:
上标^{α},下标_{α},上下标同时有用_^{α}{β}其中α是下标,β是上标。
- 括号:
()表示自己
- 空格:
\blank
四、 基础文法
Sà$$B$$
BàTB|T
TàR_^{B}{B}
TàR^{B}
TàR_{B}
TàR
Ràid | num | \blank | (B)
五、 输入输出
1. 输入:文本文件,文件名:sample??.txt,一个输入文件中仅包含一个公式。公式后的内容可忽略。
2. 输出:文本文件,文件名:typeset??.txt
3. 样例:
(1):
sample01.txt
$$a^{2}$$
typeset01.txt
240,250,30,a
260,265,20,2
(2):
sample02.txt
$$a_^{c2}{b}$$
typeset02.txt
240,250,30,a
260,235,20,c2
260,265,20,b
六、 题目要求
1、编程语言及环境:
(1)编程语言和环境不限,可以用lex和yacc工具,也可以用java、matlab、c等高级语言。
(2)画布大小500*500点,字体大小可自定义。
2、测试环境:
Windows,不含任何工具包。
如不能保证在该环境下使用,请自己准备笔记本和环境。
提供排版测试程序(matlab),用于测试输出文件是否达到要求。如使用自己的笔记本,请安装matlab,并将排版测试程序准备好。或者也可以自己编写同等功能的测试程序(注意,不得将测试程序与编译器程序合并)。
测试样例中有合法的、也有错误的。
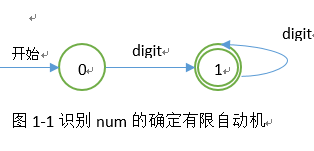
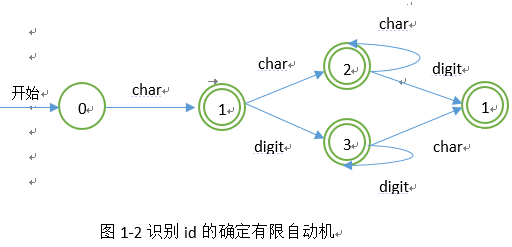
2、 词法分析的正规式和确定的有限自动机
正规式如下:
(1) char → [a-z]
(2) digit → [0-9]
(3) num → digit(digit)*
(4) id → char(char|digit)*
相应的确定有限自动机图如下图1-1和图1-2所示:
3、 语法分析器的伪代码


1 void start_S(){ 2 /* S() 函数对应于文法"S->$$B$$" */ 3 match($); 4 match($); 5 B(start_x,start_y,start_ps); /*初始值*/ 6 match($); 7 match($); 8 } 9 10 int B(int x,int y, int ps){ 11 /* B()函数对应于文法 ""B->TB|T" 输入参数 x:公式开始的横坐标;y:公式开始的纵坐标;ps:公式字体大小 返回值为表达式公式的结束横坐标*/ 12 finish_x = T(x, y, ps); 13 if(lookahead == |id|num|\blank|){ 14 endx = B(finish_x,y,ps); 15 } 16 return finish_x; 17 } 18 19 int T(int x, int y, int ps){ 20 /* T() 函数对应于文法 21 T -> R_^{B}{B} 22 T -> R^{B} 23 T -> R_{B} 24 T -> R 25 */ 26 finish_x = R(x,y,ps); 27 if(lookahead == "_"){ 28 match("_"); 29 if(lookahead == "^"){ 30 match("^"); 31 match("{"); 32 finish_x1 = B(sub(x, y, ps)); /* sub 为下标时调用 处理x,y,ps*/ 33 match("}"); 34 mathc("{"); 35 finish_x2 = B(sup(x, y, ps)); /* sup 为下标时调用 处理x,y,ps*/ 36 match("}"); 37 return max{finish_x1,finish_x2}; 38 } 39 else{ 40 match("{"); 41 finish_x = B(sub(x, y, ps)); 42 match("}"); 43 } 44 else if(lookahead == "^"){ 45 match("^"); 46 match("{"); 47 finish_x = B(sup(x, y, ps)); 48 match("}"); 49 return finish_x; 50 } 51 else{ 52 return x; 53 } 54 } 55 } 56 57 int R(int x, int y, int ps){ 58 /* R() 函数对应于文法 R -> id|num|\blank|(B) */ 59 if (lookahead == id){ 60 match(id); 61 return x+ps*length(id)*factor; //length(id)是计算id的长度 factor常数表示控制因子,用以自定义排版间距 62 } 63 else if(lookahead == num){ 64 match(num); 65 return x+ps*length(num)*factor; 66 } 67 else if (lookahead == "\blank"){ 68 match("\blank"); 69 return x+ps*length("\blank")*factor; 70 } 71 else if(lookahead == "("){ 72 match("("); 73 end_x = B(x, y, ps); 74 match(")"); 75 return end_x; 76 } 77 else{ 78 error(); 79 } 80 } 81 82 void match(terminal t){ 83 /* match()函数用于匹配输入并取下一个记号 */ 84 if(lookahead == t){ 85 lookahead = nextToken(); 86 } 87 else{ 88 error(); 89 } 90 }
4、 Python 实现的可运行代码
1 # -*- coding: utf-8 -*- 2 __author__ = 'YOU' 3 4 5 import sys 6 import re 7 inp = [] # 是全局列表变量,记录输入的字符串 8 9 10 def s(init): 11 ''' s() 函数用于处理文法 "S -> $$B$$" 其中传入的参数init = {"x":init_x,"y":init_y,"ps":init_ps} 分别为公式的初始横坐标、纵坐标、字体大小 ''' 12 match1("$") # match1() 函数用以匹配相应记号,并将其弹出inp 13 match1("$") # 匹配并弹出"$" 14 b(init) # 调用 b()函数 15 match1("$") # 匹配并弹出 “$” 16 match1("$") # 匹配并弹出"$" 17 18 19 def b(a): 20 ''' b()函数用于处理文法 "B -> TB|T" 输入参数 a={"x":x,"y":y,"ps":ps}分别是记号B的起始横坐标、纵坐标以及字体大小;返回值是记号B的结尾横坐标''' 21 endx = t(a) # 由文法 "B -> TB|T" 知需要先处理记号T, 22 # 此处t()函数即是对记号T处理,返回记号T的结尾横坐标 23 if lookahead() in ["id", "num", r"\blank", "("]: # 判断记号T后面是否还有记号B 24 a['x'] = endx # 记号B的开始坐标是记号T的结尾坐标 25 endx = b(a) # 处理B记号,返回记号B的结尾横坐标 26 return endx 27 28 29 def t(a): 30 ''' t()函数用于处理文法" T -> R_^{B}{B}|R^{B}|R_{B}|R" 输入参数 a={"x":x,"y":y,"ps":ps}分别是记号T的起始横坐标、纵坐标以及字体大小;返回值是记号T的结尾横坐标''' 31 endx = r(a) # 由文法知需要先处理记号R, 32 # 此处r()函数即是对记号R处理,返回记号R的结尾横坐标 33 a['x'] = endx # 将T的结尾横坐标作为下一个记号的起始横坐标 34 if lookahead() == "_": # 判断下一个输入是否为 "_" 35 match1("_") # 匹配记号"_" 36 if lookahead() == "^": # 判断下一个记号是否为 "^" 37 match1("^") # 匹配记号 "^" 此时对应用文法 "T -> R_^{B}{B}" 处理 38 match1("{") 39 endx1 = b(sub(a)) # 由文法知需要处理B记号,故调用b()函数, 40 # 因为此时B是下标,故调用sub()返回对应下标的参数 41 match1("}") 42 match1("{") 43 endx2 = b(sup(a)) # sup()返回上标的参数 44 match1("}") 45 return max(endx1, endx2) # 将上标和下标中的最大值结尾横坐标返回 46 else: # 对应于应该按文法 "T -> R_{B}" 处理 47 match1("{") 48 endx = b(sub(a)) 49 match1("}") 50 return endx 51 elif lookahead() == "^": # 判断下一个输入是否为 "^" 52 match1("^") # 对应于文法 "T -> R^{B}" 53 match1("{") 54 endx = b(sup(a)) 55 match1("}") 56 return endx 57 else: # 对应于文法"T -> R" 58 return endx # 返回T的为坐标 59 60 61 def r(a): 62 ''' r()函数用于处理文法 "R -> id|num|\blank|(B)" 输入参数 a={"x":x,"y":y,"ps":ps}分别是记号R的起始横坐标、纵坐标以及字体大小;返回值是记号R的结尾横坐标''' 63 if lookahead() == "id": # 如果下一个记号是id,则表示需要按文法"R ->id"处理 64 c = match2("id") # match2用来匹配id、num、\blank等终结符, 65 # 返回c[0]该终结符由多少个字符组成,用来决定结尾横坐标,c[1]为该终结符 66 # id 是终结符,并将它的属性(x,y,ps,id)写入文件 67 fpw.write(str(int(a["x"]))+","+str(int(a["y"]))+","+str(int(a["ps"]))+","+c[1]+'\n') 68 print "output:", int(a['x']), ",", int(a['y']), ",", int(a['ps']), ",", c[1] # 输出id的各属性 69 return a['x'] + a['ps']*c[0]*0.5 # 返回id的结尾横坐标作为r的结尾横坐标,0.5为调节排版因子 70 elif lookahead() == "num": # 如果下个记号是num,则需按文法"R ->num"处理 71 c = match2("num") # 将num的各属性写入文件 72 fpw.write(str(int(a["x"]))+","+str(int(a["y"]))+","+str(int(a["ps"]))+","+str(c[1])+"\n") 73 print "output:", int(a['x']), ",", int(a['y']), ",", int(a['ps']), ",", c[1] 74 return a['x'] + a['ps']*c[0]*0.55 # 返回num的结尾横坐标作为R的结尾横坐标 75 elif lookahead() == r'\blank': # 如果下一个记号是"\blank",按文法"R -> \blank"处理 76 c = match2(r"\blank") 77 return a['x']+a['ps']*c[0]*0.6 78 elif lookahead() == "(": # 如果下一个记号是"(",那文法"R -> (B)"处理 79 match1("(") 80 endx = b(a) 81 match1(")") 82 return endx 83 else: # 如果上面的都没匹配到,这说明输入发生错误 84 errlen = len(list2str(in_string))-len(list2str(inp)) # errlen计算错误在输入字符串中的发生位置 85 # 输出错误信息 86 print ("ERROR: while get input char in line 1:"+str(errlen+1)+"\n"+ in_string+"\n"+" "*errlen + "^") 87 exit(1) # 退出程序 88 89 90 def sub(a): 91 ''' sub()函数用于求下标记号的参数,返回输入参数对应的下标的参数 ''' 92 b1 = {} 93 b1['x'] = a['x'] # 横坐标不变 94 b1['y'] = a['y'] -a['ps']*0.5 # 纵坐标减小0.5×ps 95 b1['ps'] = a['ps']*0.6 # 字体减小到 ps*0.6 96 return b1 # 返回参数 97 98 99 def sup(a): 100 ''' sup函数用于求上记号的参数,返回输入参数对应的上标的参数 ''' 101 b1 = {} 102 b1['x'] = a['x'] # 横坐标不变 103 b1['y'] = a['y'] +a['ps']*0.5 # 纵坐标增加0.5×ps 104 b1['ps'] = a['ps']*0.6 # 字体变小到 0.6×ps 105 return b1 # 返回参数 106 107 108 def lookahead(): 109 ''' lookahead()函数向前搜索记号 ''' 110 a = inp[0] # a取剩余记号的第一个字符 111 if a in ("$", "^", "_", "(", ")","{","}"): 112 return a # 直接返回上述记号 113 elif re.match('[a-z]', a, 0): # 若第一个字符是以字母开头,匹配到id 114 return "id" 115 elif re.match('[0-9]', a, 0): # 若第一个字符是数字,则匹配到num 116 return"num" 117 elif list2str(inp[0:6]) == r"\blank": # 若前6个字符是"\blank",则匹配到"\blank" 118 return r"\blank" 119 120 121 def match1(get_in): 122 ''' 简单匹配记号 {、}、(、)、^、_ ''' 123 if get_in == lookahead(): # 判断要匹配的记号与lookahead()一致,则匹配成功,从串中弹出该记号 124 a = inp.pop(0) 125 else: # 否则输出错误信息 126 errlen = len(list2str(in_string))-len(list2str(inp)) 127 print ("ERROR: while get input char in line 1:"+str(errlen+1)+"\n"+ in_string+"\n"+" "*errlen + "^") 128 exit(1) 129 130 131 def match2(get_in): 132 ''' 匹配记号id、num、\blank ''' 133 if get_in == "id": # 如果是id 134 i = 1 # i 记录id字符的长度 135 ch =[] # ch 记录该id的组成 136 while re.match('[a-z0-9]', inp[0], 0): # 当剩余字符串中的第一个字符在正规式[a-z0-9]中时,执行循环 137 ch.append(inp.pop(0)) # 将inp中第一个字符加入ch中 138 i += 1 # ch中的字符个数加1 139 ch1 = "" 140 for j in ch: # 将列表的ch转化为字符串类型返回 141 ch1 += j 142 return i, ch1 # 返回id的长度和组成 143 elif get_in == "num": # 如果要匹配的是id 144 i =1 145 ch =[] 146 while re.match('[0-9]', inp[0], 0): # 当剩余字符串中的第一个字符在正规式[0-9]中时,执行循环 147 ch.append(inp.pop(0)) 148 i += 1 149 150 ch1 = "" 151 for j in ch: 152 ch1 += j 153 return i, eval(ch1) # 返回num的长度和组成 154 elif get_in == r"\blank": # 若是要匹配\blank 155 for j in range(6): # 直接从输入中弹出"\blank" 156 inp.pop(0) 157 return 1, ' ' # 返回 1长度的 空格 158 159 160 def list2str(a): 161 ''' 辅助用于输出函数,功能是将列表转化为字符串''' 162 str = "" 163 for i in a: 164 str += i 165 return str 166 167 168 if __name__ == '__main__': 169 # 主函数,程序运行的入口 命令行下运行需要传入两个参数 170 # in_file为输入文件路径 out_file 为输出文件路径 171 # 如 python EQN.py input.txt output.txt 172 in_file = sys.argv[1] # 获取输入文件路径 173 out_file = sys.argv[2] # 获取输出文件路径 174 fpr = open(in_file, 'r') # 输入文件 175 fpw = open(out_file, "w") # 输出文件 176 in_string = fpr.read() # 读取输入文件内容给in_string 177 file_name = in_file.split("\\")[-1] 178 print "input_file:"+file_name 179 print "input:", in_string 180 inp.extend(list(in_string)) # 将in_string 的值转化为列表添加到全局变量inp中 181 init = {'x': 200, 'y': 250, 'ps': 30} # 初始的参数设定 182 s(init) # 调用 s()函数开始执行文法
5、matlab测试程序
1 function typeset(filename) 2 MAX=500; 3 scale=1/MAX; 4 set(gcf,'color','w'); 5 set(gcf,'Position',[100 100 MAX MAX]); 6 set(gca,'Position',[0 0 1 1]); 7 axis off; 8 9 sf=fopen(filename,'r'); 10 line=1; 11 while (~feof(sf)) 12 str=fgetl(sf); 13 [par,n,~,p]=sscanf(str,'%f,%f,%f,',3); 14 if (n<3) 15 fprintf('line %d is error! Missing parameters.\n',line); 16 line=line+1; 17 continue; 18 end 19 x0=par(1); y0=par(2); fontsize=par(3); 20 str=str(p:length(str)); 21 if (isempty(str)) 22 fprintf('line %d is error! Missing text.\n',line); 23 line=line+1; 24 continue; 25 end 26 str=substitute(str); 27 x=x0*scale; y=y0*scale; 28 set(text(x,y,str),'FontName','cour.ttf','FontSize',fontsize); 29 line=line+1; 30 end 31 fclose(sf); 32 end 33 34 function [str]=substitute(str) 35 sub={'##';'#blank';'#int';'#sum'}; 36 rep={'#';' ';'∫';'∑'}; 37 L=size(sub,1); 38 for i=1:L 39 str=strrep(str,sub{i},rep{i}); 40 end 41 end
6、实验结果
(1) 正确样例
下面是正确的样例的输入输出以及相对应的排版结果。



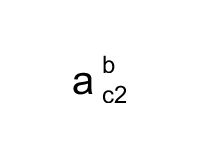
(2) 错误样例
本程序能够发现错误并且提示是在输入字符串的那个位置出现了错误,用“ ^ ”指出具体位置具体输入以及显示如下所示。


7、 体会
就说说自己的实验过程和体会吧,刚开始时准备用lex和yacc写的,也上网和到图书馆找了不少相关的资料,不过都没有找到用lex、yacc实现数学公式排版相关的。找到的都是用来实现计算器、识别SQL相关的;所以就只能自己根据一些lex、yacc知识动手写了,然而悲剧的是写好后能够编译为C代码,但是运行后就出错了;接着就是无聊的不断调试,也不知道到底哪里错了,只知道是在识别ID记号后返回yacc程序时就崩了。网上也找不到原因(关于这方面的资料真的好少),就转投高级语言实现了。我自己是用python写的,感觉高级语言写起来思路比较清楚,调试起来也很方便,所以我很快就写完了。
对比下我自己感觉的用yacc工具和高级语言实现的区别:
Yacc工具实现时更容易让你看到词法分析与语法分析的过程,以及各个记号的继承或综合属性之间的关系,与课本关系更近;缺点是对于不太熟悉yacc工具的人上手比较难。而用高级语言词法分析和语法分析之间的关系不明显,而各个记号之间的属性关系(继承、综合)也不明显,更多的是通过函数的参数传递和返回值的方式建立关联。