jQuery 2.0.3 源码分析Sizzle引擎 - 词法解析
声明:本文为原创文章,如需转载,请注明来源并保留原文链接Aaron,谢谢!
- 浏览器从下载文档到显示页面的过程是个复杂的过程,这里包含了重绘和重排。各家浏览器引擎的工作原理略有差别,但也有一定规则。
- 简单讲,通常在文档初次加载时,浏览器引擎会解析HTML文档来构建DOM树,之后根据DOM元素的几何属性构建一棵用于渲染的树。渲染树的每个节点都有大小和边距等属性,类似于盒子模型(由于隐藏元素不需要显示,渲染树中并不包含DOM树中隐藏的元素)。
- 当渲染树构建完成后,浏览器就可以将元素放置到正确的位置了,再根据渲染树节点的样式属性绘制出页面。由于浏览器的流布局,对渲染树的计算通常只需要遍历一次就可以完成
所以我们知道浏览器最终会将HTML文档(或者说页面)解析成一棵DOM树,如下代码将会翻译成以下的DOM树。
<div id="text"> <p> <input type="text" /> </p> <div class="aaron"> <input type="checkbox" name="readme" /> <p>Sizzle</p> </div> </div>
如果想要操作到当中那个checkbox,我们需要有一种表述方式,使得通过这个表达式让浏览器知道我们是想要操作哪个DOM节点。
这个表述方式就是CSS选择器,它是这样表示的:div > p + .aaron input[type="checkbox"]
表达的意思是,div底下的p的兄弟节点,该节点的class为aaron 并且后代中有一个元素是input其属性type为checkbox的。
常见的选择器:
- #test表示id为test的DOM节点
- .aaron 表示class为aaron的DOM节点
- input表示节点名为input的DOM节点
- div > p表示div底下的p的DOM节点
- div + p表示div的兄弟DOM节点p
其实最终都是通过浏览器提供的接口实现的
获取id为test的DOM节点
document.getElementById(“test”)
获取节点名为input的DOM节点
document.getElementsByTagName(“input”)
获取属性name为checkbox的DOM节点
document.getElementsByName(“checkbox”)
高级的浏览器还提供
document.getElementsByClassName
document.querySelector
document.querySelectorAll
由于低级浏览器并未提供这些高级点的接口,所以才有了Sizzle这个CSS选择器引擎。Sizzle引擎提供的接口跟document.querySelectorAll是一样的,其输入是一串选择器字符串,输出则是一个符合这个选择器规则的DOM节点列表,因此第一步骤是要分析这个输入的选择器。
看看实际效果
window.onload = function() { console.log( Sizzle('div > div.Aaron p span.red') ) console.log( document.querySelectorAll('div > div.Aaron p span.red') ) }

在开始前,我们必须了解一个真相:为什么排版引擎解析 CSS 选择器时一定要从右往左解析?
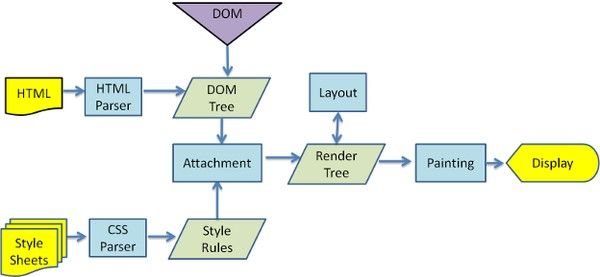
- HTML 经过解析生成 DOM Tree(这个我们比较熟悉);而在 CSS 解析完毕后,需要将解析的结果与 DOM Tree 的内容一起进行分析建立一棵 Render Tree,最终用来进行绘图。Render Tree 中的元素(WebKit 中称为「renderers」,Firefox 下为「frames」)与 DOM 元素相对应,但非一一对应:一个 DOM 元素可能会对应多个 renderer,如文本折行后,不同的「行」会成为 render tree 种不同的 renderer。也有的 DOM 元素被 Render Tree 完全无视,比如 display:none 的元素。
- 在建立 Render Tree 时(WebKit 中的「Attachment」过程),浏览器就要为每个 DOM Tree 中的元素根据 CSS 的解析结果(Style Rules)来确定生成怎样的 renderer。对于每个 DOM 元素,必须在所有 Style Rules 中找到符合的 selector 并将对应的规则进行合并。选择器的「解析」实际是在这里执行的,在遍历 DOM Tree 时,从 Style Rules 中去寻找对应的 selector。
- 因为所有样式规则可能数量很大,而且绝大多数不会匹配到当前的 DOM 元素(因为数量很大所以一般会建立规则索引树),所以有一个快速的方法来判断「这个 selector 不匹配当前元素」就是极其重要的。
- 如果正向解析,例如「div div p em」,我们首先就要检查当前元素到 html 的整条路径,找到最上层的 div,再往下找,如果遇到不匹配就必须回到最上层那个 div,往下再去匹配选择器中的第一个 div,回溯若干次才能确定匹配与否,效率很低。
- 逆向匹配则不同,如果当前的 DOM 元素是 div,而不是 selector 最后的 em,那只要一步就能排除。只有在匹配时,才会不断向上找父节点进行验证。
- 但因为匹配的情况远远低于不匹配的情况,所以逆向匹配带来的优势是巨大的。同时我们也能够看出,在选择器结尾加上「*」就大大降低了这种优势,这也就是很多优化原则提到的尽量避免在选择器末尾添加通配符的原因。
简单的来说浏览器从右到左进行查找的好处是为了尽早过滤掉一些无关的样式规则和元素
例如:
<title>aQuery</title> <script src="sizzle.js"></script> <script src="core.js"></script> <style> div > div.Aaron p span.red{ color:red; } </style> <div> <div class="Aaron"> <p><span>s1</span></p> <p><span>s2</span></p> <p><span>s3</span></p> <p><span class='red'>s4</span></p> </div> </div>
CSS选择器:
div > div.Aaron p span.red
而如果按从左到右的方式进行查找:
1. 先找到所有div节点
2. 第一个div节点内找到所有的子div,并且是class=”Aaron”
3. 然后再一次匹配p span.red等情况
4. 遇到不匹配的情况,就必须回溯到一开始搜索的div或者p节点,然后去搜索下个节点,重复这样的过程。这样的搜索过程对于一个只是匹配很少节点的选择器来说,效率是极低的,因为我们花费了大量的时间在回溯匹配不符合规则的节点。
如果换个思路,我们一开始过滤出跟目标节点最符合的集合出来,再在这个集合进行搜索,大大降低了搜索空间
从右到左来解析选择器:
则首先就查找到<span class='red'>的元素。
firefox称这种查找方式为key selector(关键字查询),所谓的关键字就是样式规则中最后(最右边)的规则,上面的key就是span.red。
紧接着我们判断这些节点中的前兄弟节点是否符合p这个规则,这样就又减少了集合的元素,只有符合当前的子规则才会匹配再上一条子规则
要知道DOM树是一个什么样的结构,一个元素可能有若干子元素,如果每一个都去判断一下显然性能太差。而一个子元素只有一个父元素,所以找起来非常方便。你可以看看css的选择器的设计,完全是为了优化从子元素找父元素而决定的。
打个比如 p span.showing
你认为从一个p元素下面找到所有的span元素并判断是否有class showing快,还是找到所有的span元素判断是否有class showing并且包括一个p父元素快 ?
所以浏览器解析CSS的引擎就是用这样的算法去解析
关于解析机制
就拿javascript而言,解析过程可以分为预编译与执行两个阶段,具体这里不说多,但是有一个重要的点
在预编译的时候通过词法分析器与语法分期器的规则处理
在词法分析过程中,js解析器要下把脚本代码的字符流转换成记号流
比如:
a=(b-c);
解析后转换成:
NAME "a" EQUALS OPEN_PARENTHESIS NAME "b" MINUS NAME "c" CLOSE_PARENTHESIS SEMICOLON
把代码解析成Token的阶段在编译阶段里边称为词法分析
代码经过词法分析后就得到了一个Token序列,紧接着拿Token序列去其他事情
大概就是这个意思,在JS征途这本书看的,没有研究V8过引擎,反正大家有兴趣去看看书吧
这里只想引申出一个思想:
CSS选择器其实也就是一段字符串,我们需要分析出这个字符串背后对应的规则,在这里Sizzle用了简单的词法分析。
所以在Sizzle中专门有一个tokenize处理器干这个事情
我们简单的看看处理后的结果:
选择器
selector: "div > div.Aaron p span.red"
经过tokenize处理器处理过后分解为

一个数组对象,展开后

其实就是对每一个标记都做了分解了
Sizzle的Token格式如下 :
Token:{ value:'匹配到的字符串', type:'对应的Token类型', matches:'正则匹配到的一个结构' }
这样拿到匹配后的结构Token就去干别的相关处理了!
看看整个源码的解析:
//假设传入进来的选择器是:div > p + .aaron[type="checkbox"], #id:first-child //这里可以分为两个规则:div > p + .aaron[type="checkbox"] 以及 #id:first-child //返回的需要是一个Token序列 //Sizzle的Token格式如下 :{value:'匹配到的字符串', type:'对应的Token类型', matches:'正则匹配到的一个结构'} function tokenize( selector, parseOnly ) { var matched, match, tokens, type, soFar, groups, preFilters, cached = tokenCache[ selector + " " ]; //这里的soFar是表示目前还未分析的字符串剩余部分 //groups表示目前已经匹配到的规则组,在这个例子里边,groups的长度最后是2,存放的是每个规则对应的Token序列 //如果cache里边有,直接拿出来即可 if ( cached ) { return parseOnly ? 0 : cached.slice( 0 ); } //初始化 soFar = selector; groups = []; //这是最后要返回的结果,一个二维数组 //比如"title,div > :nth-child(even)"解析下面的符号流 // [ [{value:"title",type:"TAG",matches:["title"]}], // [{value:"div",type:["TAG",matches:["div"]}, // {value:">", type: ">"}, // {value:":nth-child(even)",type:"CHILD",matches:["nth", // "child","even",2,0,undefined,undefined,undefined]} // ] // ] //有多少个并联选择器,里面就有多少个数组,数组里面是拥有value与type的对象 //这里的预处理器为了对匹配到的Token适当做一些调整 //自行查看源码,其实就是正则匹配到的内容的一个预处理 preFilters = Expr.preFilter; //递归检测字符串 //比如"div > p + .aaron input[type="checkbox"]" while ( soFar ) { // Comma and first run // 以第一个逗号切割选择符,然后去掉前面的部分 if ( !matched || (match = rcomma.exec( soFar )) ) { if ( match ) { //如果匹配到逗号 // Don't consume trailing commas as valid soFar = soFar.slice( match[0].length ) || soFar; } //往规则组里边压入一个Token序列,目前Token序列还是空的 groups.push( tokens = [] ); } matched = false; // Combinators //将刚才前面的部分以关系选择器再进行划分 //先处理这几个特殊的Token : >, +, 空格, ~ //因为他们比较简单,并且是单字符的 if ( (match = rcombinators.exec( soFar )) ) { //获取到匹配的字符 matched = match.shift(); //放入Token序列中 tokens.push({ value: matched, // Cast descendant combinators to space type: match[0].replace( rtrim, " " ) }); //剩余还未分析的字符串需要减去这段已经分析过的 soFar = soFar.slice( matched.length ); } // Filters //这里开始分析这几种Token : TAG, ID, CLASS, ATTR, CHILD, PSEUDO, NAME //将每个选择器组依次用ID,TAG,CLASS,ATTR,CHILD,PSEUDO这些正则进行匹配 //Expr.filter里边对应地 就有这些key /** * * *matchExpr 过滤正则 ATTR: /^\[[\x20\t\r\n\f]*((?:\\.|[\w-]|[^\x00-\xa0])+)[\x20\t\r\n\f]*(?:([*^$|!~]?=)[\x20\t\r\n\f]*(?:(['"])((?:\\.|[^\\])*?)\3|((?:\\.|[\w#-]|[^\x00-\xa0])+)|)|)[\x20\t\r\n\f]*\]/ CHILD: /^:(only|first|last|nth|nth-last)-(child|of-type)(?:\([\x20\t\r\n\f]*(even|odd|(([+-]|)(\d*)n|)[\x20\t\r\n\f]*(?:([+-]|)[\x20\t\r\n\f]*(\d+)|))[\x20\t\r\n\f]*\)|)/i CLASS: /^\.((?:\\.|[\w-]|[^\x00-\xa0])+)/ ID: /^#((?:\\.|[\w-]|[^\x00-\xa0])+)/ PSEUDO: /^:((?:\\.|[\w-]|[^\x00-\xa0])+)(?:\(((['"])((?:\\.|[^\\])*?)\3|((?:\\.|[^\\()[\]]|\[[\x20\t\r\n\f]*((?:\\.|[\w-]|[^\x00-\xa0])+)[\x20\t\r\n\f]*(?:([*^$|!~]?=)[\x20\t\r\n\f]*(?:(['"])((?:\\.|[^\\])*?)\8|((?:\\.|[\w#-]|[^\x00-\xa0])+)|)|)[\x20\t\r\n\f]*\])*)|.*)\)|)/ TAG: /^((?:\\.|[\w*-]|[^\x00-\xa0])+)/ bool: /^(?:checked|selected|async|autofocus|autoplay|controls|defer|disabled|hidden|ismap|loop|multiple|open|readonly|required|scoped)$/i needsContext: /^[\x20\t\r\n\f]*[>+~]|:(even|odd|eq|gt|lt|nth|first|last)(?:\([\x20\t\r\n\f]*((?:-\d)?\d*)[\x20\t\r\n\f]*\)|)(?=[^-]|$)/i * */ //如果通过正则匹配到了Token格式:match = matchExpr[ type ].exec( soFar ) //然后看看需不需要预处理:!preFilters[ type ] //如果需要 ,那么通过预处理器将匹配到的处理一下 : match = preFilters[ type ]( match ) for ( type in Expr.filter ) { if ( (match = matchExpr[ type ].exec( soFar )) && (!preFilters[ type ] || (match = preFilters[ type ]( match ))) ) { matched = match.shift(); //放入Token序列中 tokens.push({ value: matched, type: type, matches: match }); //剩余还未分析的字符串需要减去这段已经分析过的 soFar = soFar.slice( matched.length ); } } //如果到了这里都还没matched到,那么说明这个选择器在这里有错误 //直接中断词法分析过程 //这就是Sizzle对词法分析的异常处理 if ( !matched ) { break; } } // Return the length of the invalid excess // if we're just parsing // Otherwise, throw an error or return tokens //放到tokenCache函数里进行缓存 //如果只需要这个接口检查选择器的合法性,直接就返回soFar的剩余长度,倘若是大于零,说明选择器不合法 //其余情况,如果soFar长度大于零,抛出异常;否则把groups记录在cache里边并返回, return parseOnly ? soFar.length : soFar ? Sizzle.error( selector ) : // Cache the tokens tokenCache( selector, groups ).slice( 0 ); }
这里要提出几点:
比如解析的规则
div > p + .aaron[type="checkbox"], #id:first-child
1:groups收集并联关系的处理
div > p + .aaron[type="checkbox"], #id:first-child
分解成
groups:[
0:div > p + .aaron[type="checkbox"],
1:#id:first-child
]
然后往下还是会细分的
看看匹配第一个逗号切割选择符,然后去掉前面的部分
match = rcomma.exec( soFar )
//并联选择器的正则 // /^[\x20\t\r\n\f]*,[\x20\t\r\n\f]*/ rcomma = new RegExp( "^" + whitespace + "*," + whitespace + "*" ),
科普一下:
空白符正则:
whitespace = [\x20\t\r\n\f]
\xnn 由十六进制数nn指定的拉丁字符,如,\x0A等价于\n;
\uxxxx 由十六进制数xxxx指定的Unicode字符,例如\u0009等价于\t;
所以上面:
\x20 化为二进制数为 0010 0000;
ASCII码表 http://ascii.911cha.com/
字符编码笔记 http://www.ruanyifeng.com/blog/2007/10/ascii_unicode_and_utf-8.html

\t 制表符;
\r 回车;
\n 换行;
\f 换页;
Sizzle这么多正则关系,我就不信是直接写出来的,呵呵
2:过滤简单的单字符,几个特殊的Token : >, +, 空格, ~
放入Token序列中,然后踢掉soFar中处理的字符
3: 将每个选择器组依次用ID,TAG,CLASS,ATTR,CHILD,PSEUDO这些正则进行匹配
通过递归soFar 其实就是 selector = div > p + .aaron[type="checkbox"], #id:first-child
matchExpr就定义了匹配规则
4: tokenCache( selector, groups ).slice( 0 );
缓存到tokenCache 词法分析阶段需要的缓存器
画一张直观图便于理解
