MDX Step by Step 读书笔记(七) - Performing Aggregation 聚合函数之 Max, Min, Count , DistinctCount 以及其它 TopCount, Generate
MDX 中最大值和最小值
MDX 中最大值和最小值函数的语法和之前看到的 Sum 以及 Aggregate 等聚合函数基本上是一样的:
Max( {Set} [, Expression])
Min( {Set} [, Expression])
直接看例子,先查询出所有 Sub Category 下的 Reseller Sales Amount。
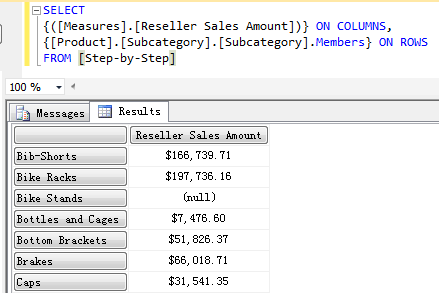
然后使用 MAX 函数查询出 Sub Category 下最大的 Reseller Sales Amount。在这里查询的范围即 SET 集合是 Sub Category 的所有成员,比较大小的依据是 Reseller Sales Amount,即在 SET 集合中查找 Reseller Sales Amount 的最大值。
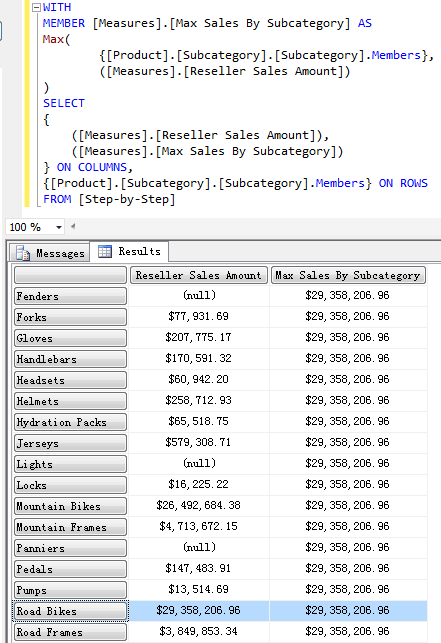
比较每个 Sub Category 的 Reseller Sales Amount 和最大值的百分比。
WITH
MEMBER [Measures].[Percent of Max]
AS
([Measures].[Reseller Sales Amount]) / ([Measures].[Max Sales By Subcategory])
, FORMAT_STRING="Percent"
MEMBER [Measures].[Max Sales By Subcategory] AS
Max(
{[Product].[Subcategory].[Subcategory].Members},
([Measures].[Reseller Sales Amount])
)
SELECT
{
([Measures].[Reseller Sales Amount]),
([Measures].[Percent of Max])
} ON COLUMNS,
{[Product].[Subcategory].[Subcategory].Members} ON ROWS
FROM [Step-by-Step]
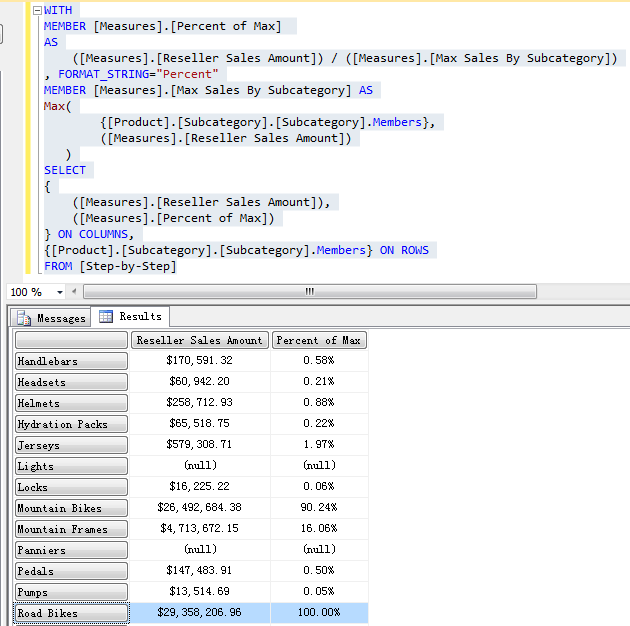
注意 Max、Min 函数与 TopCount 函数的区别:
Max、Min 函数返回的是在集合中元组对应表达式中最大或者最小的值,但 TopCount 是根据表达式查找集合中的成员。
下面查找 Reseller Sales Amount 最高的那个 Subcategory 成员。
SELECT
{
([Measures].[Reseller Sales Amount])
} ON COLUMNS,
TOPCOUNT
(
{[Product].[Subcategory].[Subcategory].Members},
1,
([Measures].[Reseller Sales Amount])
)ON ROWS
FROM [Step-by-Step]
统计集合中的元组 Count( {Set} [, Flag])
与前面的 MDX 聚合函数一样操作的对象都是集合 SET。Flag 的作用是:如果没有 Flag 或者指定 INCLUDEEMPTY,那么 Count 函数就直接返回集合中元组的数量;如果指定了 EXCLUDEEMPTY ,那么将返回与当前度量值相关联的非空的元组。
查询 Product 级别下所有成员的 Internet Sales Amount 和 Reseller Sales Amount,可以从下面的查询中看出不是所有产品都有 Internet Sales Amount 或者 Reseller Sales Amount 的销售记录。
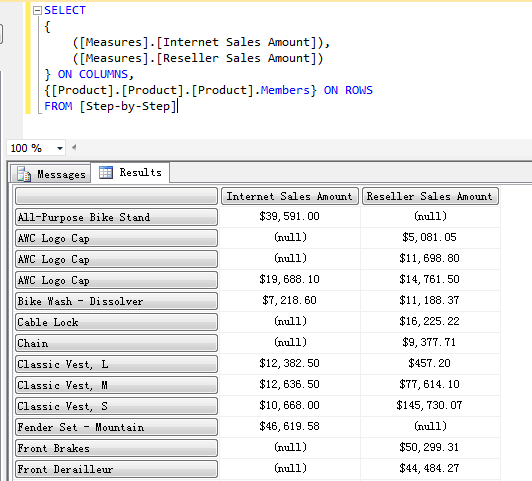
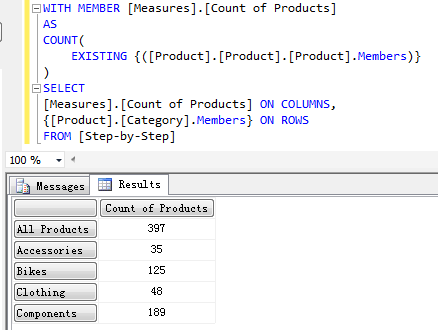
COUNT 一下各个 Category 下 Product 成员的个数 -
WITH MEMBER [Measures].[Count of Products]
AS
COUNT(
EXISTING {([Product].[Product].[Product].Members)}
)
SELECT
[Measures].[Count of Products] ON COLUMNS,
{[Product].[Category].Members} ON ROWS
FROM [Step-by-Step]
统计 Category 下 Reseller Sales Amount 大于等于 Internet Sales Amount 的 Products。
WITH MEMBER [Measures].[Count of Products]
AS
COUNT(
EXISTING {([Product].[Product].[Product].Members)}
)
MEMBER [Measures].[Reseller vs Internet Count of Products]
AS
COUNT(
FILTER(
EXISTING {([Product].[Product].[Product].Members)},
[Measures].[Reseller Sales Amount] >= [Measures].[Internet Sales Amount]
)
)
SELECT
{[Measures].[Count of Products],
[Measures].[Reseller vs Internet Count of Products]} ON COLUMNS,
{[Product].[Category].Members} ON ROWS
FROM [Step-by-Step]
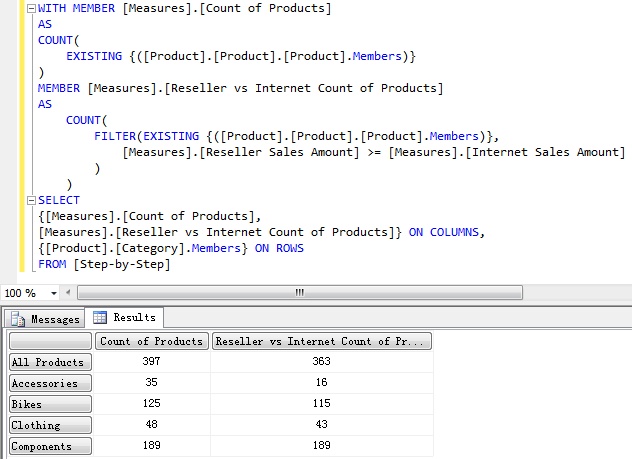
上面的查询结果中仍然有不准确的地方,因为在统计过程中包含了 Reseller Sales Amount 为 NULL, Internate Sales Amount 为 NULL 或者两者都为 NULL 的元组,实际上这类元组应该在统计的时候要被排除掉。
因此,加上 EXCLUDEEMPTY 关键字再来查询一下 -
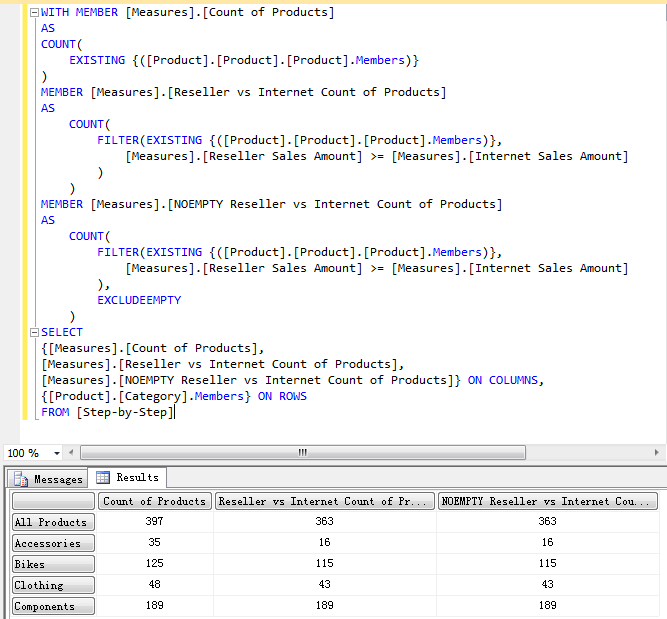
但是通过观察最后的查询结果发现尽管使用了 EXCLUDEEMPTY 关键字也没有什么变化,但是确实有一些 Products 是没有 Reseller Sales Amount 数据的。其原因就在于这里会造成 Infinite Recursion 错误,只不过在这里被自动处理掉了。
有关 Infinite Recursion 的内容可以参看 MDX Step by Step 读书笔记(五) - Working with Expressions (MDX 表达式) - Infinite Recursion 和 SOLVE_ORDER 原理解析
可以通过 CrossJoin {[Measures].[Reseller Sales Amount]} 来解决这个问题,因为这样 COUNT 的时候就知道了上下文环境,元组中关联的度量值对象是 {[Measures].[Reseller Sales Amount]}。
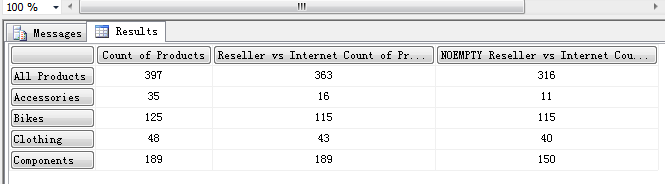
WITH MEMBER [Measures].[Count of Products]
AS
COUNT(
EXISTING {([Product].[Product].[Product].Members)}
)
MEMBER [Measures].[Reseller vs Internet Count of Products]
AS
COUNT(
FILTER(
EXISTING {([Product].[Product].[Product].Members)},
[Measures].[Reseller Sales Amount] >= [Measures].[Internet Sales Amount]
)
)
MEMBER [Measures].[NOEMPTY Reseller vs Internet Count of Products]
AS
COUNT(
FILTER(
EXISTING {([Product].[Product].[Product].Members)},
[Measures].[Reseller Sales Amount] >= [Measures].[Internet Sales Amount]
)* {[Measures].[Reseller Sales Amount]},
EXCLUDEEMPTY
)
SELECT
{[Measures].[Count of Products],
[Measures].[Reseller vs Internet Count of Products],
[Measures].[NOEMPTY Reseller vs Internet Count of Products]} ON COLUMNS,
{[Product].[Category].Members} ON ROWS
FROM [Step-by-Step]
DistinctCount 函数
MDX 提供了另外一种 COUNT 的形式 - DistinctCount,它可以在执行 COUNT 之前先忽略掉空的以及重复的元组然后进行统计。它其实在操作上等同于在 COUNT 函数中使用 DISTINCT 关键字:COUNT(DISTINCT ({SET}), EXCLUDEEMPTY)
它的实际语法是:DistinctCount({SET})
但是如果仅仅是需要去掉重复元组后再统计 COUNT ,并且也允许包含空的元组的统计,那么就应该使用:
COUNT(DISTINCT ({SET})) 或者 COUNT(DISTINCT ({SET}), INCLUDEEMPTY)
Generate 函数
Generate ({Set}, Expression) ,Generate 函数在这一篇笔记中已经介绍过了 -
MDX Step by Step 读书笔记(六) - Building Complex Sets (复杂集合的处理) - Generate 和 Extract 函数的使用
简单回顾一下这个函数,它类似于一个循环,相当于在集合中的每一个元组都去匹配一下表达式,符合要求的元组留下来并最终和其它一样满足要求的元组共同组成一个新的集合 SET 返回。
它还有另外的一种形式可以在聚合中用到:Generate({Set}, Expression [, Delimiter])
在这个形式中,Generate 函数仍然会迭代 SET 集合中的每一个元组并匹配表达式中的内容,符合条件的元组根据 Delimiter 分割符与其它元组形成一个字符串。
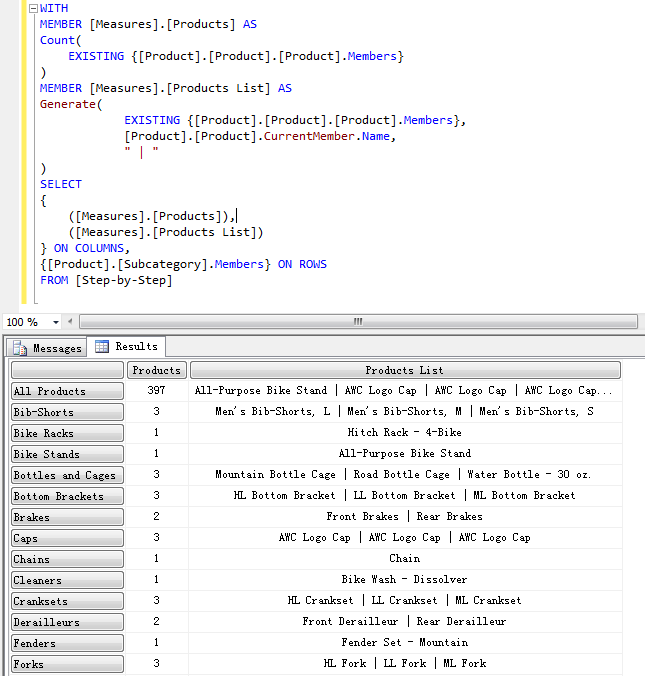
WITH
MEMBER [Measures].[Products] AS
Count(
EXISTING {[Product].[Product].[Product].Members}
)
MEMBER [Measures].[Products List] AS
Generate(
EXISTING {[Product].[Product].[Product].Members},
[Product].[Product].CurrentMember.Name,
" | "
)
SELECT
{
([Measures].[Products]),
([Measures].[Products List])
} ON COLUMNS,
{[Product].[Subcategory].Members} ON ROWS
FROM [Step-by-Step]
更多 BI 文章请参看 BI 系列随笔列表 (SSIS, SSRS, SSAS, MDX, SQL Server) 如果觉得这篇文章看了对您有帮助,请帮助推荐,以方便他人在 BIWORK 博客推荐栏中快速看到这些文章。