前 言
我们一说到教育,就不可避免地会谈到中考、高考,这些高风险考试(high-stakes tests)。虽然大家对“教育测量”这个概念可能不那么熟悉,但关心教育行业的伙伴对以下问题可能会比较有共鸣。比如:我们如何决定一张试卷是不是适合当年、当地的考生?我们如何为不同学科的试题赋值,应该使用等级、原始分数还是转换分数?新高考的计分逻辑和原始分数有什么不同?选科高考后,大家选择的科目都不一样,分数可比性怎么解决?这些问题背后的逻辑都与教育测量学密不可分。
其实,教育测量的理论和技术,不仅仅会应用在大型高风险考试,还可以应用在老师们日常教学的闭环中。比如,在面对一个新生的时候,我们如何知道学生初始的知识掌握水平?在教学期间,我们如何知道学生对一个知识点有没有掌握、掌握到什么程度?在一段学习之后,我们如何知道学生相比较刚来报班的时候有没有水平的进步或变化?学科能力水平这样的抽象概念,我们很难一眼看到,不像我们的身高、体重那么直观。所以我们就要依赖测量工具来对这些抽象、潜在的心理维度进行外化和量化,获得关键的学情信息,让我们直观地透过学生的作答信息和作答结果来回答这些问题,牵引着老师们在日常教学过程中的每一步动作。
1. 教育测量是什么?
那么,教育测量(Educational Measurement)到底是干什么的呢?实际上,教育测量要做的事儿就是对各种与教育相关的事物进行量化,给这些事物指派数字,最终来实现不同的教育决策(例如:选拔、评价、因材施教等)。以评价为例,我们可以通过各种不同形式的“考试”把学生的学习表现量化,用数字或者等级来代表,进而评价学生的学习效果。我们也可以通过对老师平时的教学行为进行量化,用数字或者等级来代表,来评价老师的教学效果。中国著名心理学家张厚粲老师说,“一个人的经验再丰富,也难免带有一定的局限性。再好的售货员不用尺或秤,而仅凭经验卖布卖糖时也会出错”。教育测量学就是希望可以用科学方法保证试卷的质量,确保可以精准地测量与教育相关的事务,保证根据分数做出的决策是合理的、公平的。
在教育测量学中,衡量测评工具最重要的两个指标是信度(reliability)和效度(validity)。其中,信度是指这个测量工具要可靠、稳定地测查我们关注的维度,比如:学生的学科能力。效度是指这个测量工具确实是在测试我们所关注的维度,而不是其他不相关的维度。比如:数学考试就是测试学生的数学能力,而不是学生的英语能力。这两个概念,会在我们后续的文章中为大家详细介绍。
在这篇文章中,我们将具体介绍在教育测量领域中被广泛使用和研究的一种现代测量理论,名为项目反应理论(Item Response Theory,IRT)以及这个理论下的常用技术和模型,让我们从一个科学、技术的眼光看看考试背后的故事。
2.项目反应理论(IRT)概述
在介绍测验理论之前,我们先从大家的做题和考试经验来入手体会一下不同理论的差异。传统考试里大家做一份题,做完以后老师反馈试卷总分,如果我们忽略每个题目的分值,其实每个人的考分可以表达为作答正确的百分比。比如,一份试卷20题,对了15题,那么最后试卷得分就是75%。那么,75%的正确率代表什么呢?首先,我们日常在出试卷的时候,一定不是只关心学生在这张试卷上表现怎么样,而是我们想通过这张试卷的20题,去推断他能力到底怎么样。这张试卷的20题是对学生知识掌握情况的抽样,如果再给这位学员40题,他是否可以做对75%的试题,也就是30题?如果是80题,他是否能够做对60题(依然是75%正确率)?这里隐含的假设是,我们老师抽选的20个题是无穷无尽的题海中的一个有代表性的样本。
但是,当老师们组出的20个题并不是对于一个年级有代表性的样本时,或者试卷间考察的知识点本身就不同时,则没有办法认为一个考生在试卷A的正确率是75%,他在试卷B上的正确率也是75%。这样只通过总体试卷正确率去评价学生的方法是有一个测量理论支持的,叫做经典测验模型(Classical Test Theory,CTT)。
要了解项目反应理论(Item Response Theory, IRT),我们首先需要认识一下CTT——因为正是CTT的局限性,才有了IRT产生的契机。CTT是在随机抽样理论基础上建立的一套心理与教育测量理论体系,其核心假定是:在测验水平上,观察得分(observed score;也就是我们通常的考试得分)等于真分数(true score;真实能力应该体现的分数)加上随机误差分数(error score;其他不相干因素导致的误差)。由于我们假设误差是正态分布上的随机变量(均值为0的),因此,如果同一个测验或平行测验可以反复测量同一个人足够多次,观察分数的均值就会接近考生的真分数,随机误差的均值为0。那这样的理论主要有以下几个局限性:
- 在CTT下,用许多彼此平行的测验或同一个测验反复测量同一个人的同一种心理特质的做法在实际操作中往往是很难实现的,因此对个体真分数的精确估计也就主要停留在理论的层面上。
- CTT的信度估计精度并不高。在CTT中,测验信度被定义为真分数方差与原始分数方差之比。虽然我们可以获取原始分数,但真分数方差在实际中却无从获取,哪怕是使用平行测验估计信度,完美的平行测验也是不存在的,因此实际估计的信度也不可避免地存在误差。
- CTT各种参数(如:信度、效度、难度、区分度)的估计对样本的依赖性很大。例如:对于同一题目,若考生样本的群体水平较低,我们就会得到较高的难度估计值;反之,则得到较低的难度估计值。为了避免样本偏颇造成参数估计误差过大,CTT特别强调抽样时要注意保证样本对总体的代表性。
- CTT中,测验对考生的评价指标主要为测验总分,而测验总分是考生在各个项目上的观察分数的总和。在用总分评价考生时,不同考生之间水平的比较只能在他们考了同一份测验的情形下进行,但是如果不同的考生参加的测验不同,那么这些总分之间就是不可比的,也就限制了我们对测验分数的应用。
- 在CTT下试卷的难度量表和考生的能力量表之间的关系是不一致的。在CTT中,题目难度的参照系是考生群体。例如:难度0.8表示该试题有80%的考生得分,但难度会随着受试群体的变化而变化。考生能力参数的参照系是试题集合。例如:百分制试卷中某考生卷面得分是80分,表明该考生在此特定试卷上得分率为80%,但是该考生是否能答对某个难度为0.8的题目呢?一个能力水平参数已知的考生完成一份所有项目参数均已知的测验,其在各个项目上的反应情况又如何呢?由于在CTT中,项目难度参数和考生能力参数定义在不相关的两个度量系统上,所以两者之间无法进行比较,也就无法进行预测,对测验编制活动的指导价值是有限的。
既然CTT存在那么多局限性,是否有更科学、更实用的测量理论来弥补这些不足呢?我们接下来要介绍的项目反应理论(IRT)就是为解决这些局限应运而生的。
2.1 IRT的基本框架
IRT全称为Item Response Theory, 译为项目反应理论。其中所谓“项目”(item)其实就是指的我们试卷中的题目,“项目反应”(item response)就是考生在具体题目上的作答。简而言之,IRT就是建立在学生能力和作答正确率的关系上的。我们知道,影响考生在项目上作答结果的主要因素有两个方面:第一个方面是考生本身的能力水平;第二个方面是试题项目的测量学属性,如项目难度、区分度、猜测性。在日常教学活动中,我们都有这样的经验:对于一道编制质量很好的题目,全卷总分较低的考生在该题目上的正确作答概率较小,而全卷总分较高的考生在该题目上的正确作答概率相应较高。这种伴随着总分的由低到高,题目正确作答概率由小到大变化的过程基本上是一种连续性变化的曲线。在经典测量理论中(CTT),卷面总分可以被视作学生能力的代表,但是学生卷面总分是随测验的许多特性而变的。例如,随着试卷难度的改变,同一考生的卷面总分也会随之改变。那么能否用一种稳定反映考生水平的潜在特质(latent traits)变量来代替卷面总分呢?
假设这种潜在特质(即考生的能力)是存在且可被测量的,我们用θ来表示,那么随着考生的能力水平的变化,考生答对某题目的概率P(θ)也相应变化。这种描述考生能力水平与项目作答结果之间关系的数学模型被称为项目特征函数(item characteristic function, ICF),以图像表示则称为项目特征曲线(item characteristic curve, ICC)。下图1为一典型的ICC:横轴表示考生的能力水平,纵轴表示答对某题目的概率。每一个题目会有自己的ICC。
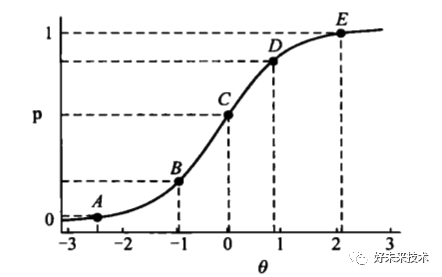
图1. 项目特征曲线(ICC)
考生潜在特质θ在特征函数ICF中是一个自变量,从理论上说θ的定义域是无穷的,从负无穷到正无穷都可取。P(θ)的值随着θ的增大而增大,但以P(θ) = 1为它的上渐近线。参数θ与卷面总分有一定的联系,正常情况下两者呈正相关。但是,θ是考生水平更为本质、精确的描写。习惯上θ采用标准Z分数的表达形式,其上下限一般设定为[-3,3]。
ICC的走势除了受到考生潜在特质的影响外,还受到三个反映测验试题特征的未知题目参数alphaα、betaβ、c的影响,这三个参数决定了S形曲线的走向 (图2)。alphaα参数被称为题目的区分度,它刻画了测验题目对考生水平区分能力的高低。在题目的ICC中,alphaα值是曲线拐点处切线斜率的函数值。曲线在拐点处越陡峭,值则越大,同时意味着能力θ在拐点处稍有变化,则在该题目上正确作答的概率差别较大,因此也就说明该试题起到了精细区分考生的作用。

图2. 不同参数在项目特征曲线上的含义
参数c被称为猜测参数,是指实际测验中考生纯凭猜测而作答成功的概率。直线P(θ) = c是ICC的下渐近线。若题目的猜测参数为c,则意味着θ为负无穷的考生在该题上正确作答的概率也为c。
betaβ参数被称为题目难度。难度为betaβ的题目,若排除c的影响,潜在特质θ恰好等于betaβ的考生,TA在该题目上正确作答的概率为0.5。随着题目betaβ值的升高,ICC在横轴方向上向右平移,这时只有潜在特质更高的考生才可能在新题目上获得相同的正确作答概率。因此,betaβ值确定了,ICC在横轴上的位置也就确定了。与CTT中的难度参数不同,这里的位置参数是定义在考生能力量尺下的,而不是单纯考虑题目的作答情况。
2.2 IRT理论下的不同模型
项目反应理论(IRT)中题目参数和潜在特质水平参数共同影响测验的结果和精度。题目参数越多,对题目性质刻画越精细,但相对来说,模型也就越复杂,应用越困难。那么什么样的函数形式可以整合考生潜在特质和题目特征呢?研究者根据大量、可观测到的作答反应曲线,拟合提出了IRT的两个基础模型——正态肩型模型(the normal ogive model)和逻辑回归模型(logistic model)。
由于正态概率分布曲线是一S形曲线,因此研究者(Lord, 1952)首先想到了用它来拟合ICC,而正态肩型模型也从理论上奠定了IRT初始模型的基本形式。但是由于其模型中采用了积分函数的形式,在实际参数估计和使用中不方便,因此在1957年,Birnbaum将其改换成了logistic形式 (如下公式)。
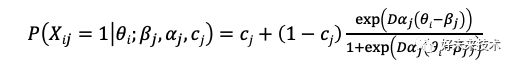
其中, θ为考生能力,alphaα为题目区分度参数,betaβ为题目难度参数,c为猜测参数,D为常量。P为能力为θ的考生正确作答某题目的概率。当D取值为1.702时,此函数的概率密度与正态肩型曲线的差异小于0.01。由于计算方便,目前多用此函数形式来描述ICC曲线。以上方程被称为三参数模型,当c=0时,该方程简化为双参数模型;当c=0且alphaα值一致时,该方程只有项目难度参数betaβ,因此被简化为单参数模型。有一种特殊并被广泛应用的单参数项目特征曲线被称为Rasch模型,由丹麦学者Rasch (1960)独立提出,对于不同的题目,其alphaα值恒定为1。
2.3 IRT模型参数估计
当我们精心设计了一张试卷,并大费周章地得到学员的作答数据后,应该怎样利用这些数据估计学员的能力呢?针对具体的模型,IRT参数估计的过程就是要通过实测数据(即考生的作答数据),有时可能还需要借助一些人们积累的经验信息,获取测验中每个项目参数的估计值,以及参加测验的考生能力水平参数估计值。然而,在参数估计中,我们只有考生的得分矩阵和一些先验信息,考生的能力参数和项目参数均未知,我们要如何估计这些参数呢?一种经典的估计方法需要用到一种名为联合极大似然估计(Joint Maximum Likelihood Estimation, JMLE)的方法对考生能力水平参数和项目参数进行联合估计。
所谓联合估计,具体来说就是首先以考生能力初始估计值作为已知条件,利用极大似然估计的方法估计项目参数;然后以该估计的项目参数为已知条件,重新校正初始考生能力参数;将能力估计值标准化,并且将项目参数做相应变换,即将两类参数放到同一量尺下;然后又以校正后的能力参数进一步校准项目参数,如此循环递推新值,直至两类参数达到某个预先设定的标准为止。
尽管JMLE的方法可以同时估计考生参数和项目参数,但这种方法在实际运用中也存在很大的问题。例如:为了更精确地估计项目参数,一个常用的方法是增加项目样本量,但是增加样本量的同时也会导致考生参数估计量的增加,因此就会有更多没有额外项目信息的考生参数需要估计。同时,把考生参数和项目参数绑定在一起也不是一种有效的计算方法,因为只要一个项目的模型拟合没有做好,就需要重新进行整个项目参数和考生参数的估计。因此,在实际操作中,研究者普遍采用一种更有效的项目参数估计方法——边际极大似然估计(Marginal Maximum Likelihood Estimation, MMLE)。MMLE的方法是把考生看成是来自于某个已知分布总体的代表性随机群体,可以通过基于对该已知分布进行积分的方式来估计项目参数。
已有考生作答数据信息,且项目参数确定的情形下,一种常用的能力参数估计方法为贝叶斯后验期望估计的方法 (Expected a Posterior Estimation, EAPE)。EAPE的方法与极大似然估计的过程不一样,可以通过直接计算就得到期望估计值,因此计算过程更简单,速度更快,也符合传统的贝叶斯思想,使它成为能力参数估计的一个上佳选择。
2.4 IRT的优势
在以上内容中,我们介绍了IRT的理论框架、相关模型以及参数估计的内容,可以看出IRT和CTT有很大的不同,那么IRT是怎么克服CTT的局限的呢?它的优势又体现在哪里?
2.4.1 项目参数与考生能力参数具有不变性的特征
我们在本节的开头提到CTT参数的估计对参测样本的依赖性很大,但是在IRT中测验的题目参数具有跨群体不变性,即题目参数估计独立于参测样本。具体来说,只要测试同一特质的测验项目的参数具有足够宽的覆盖,也就是测验中既有难的题目,又有中等难的题目,也有容易的题目,那么不管题目分布形态如何,考生能力参数的估计就不依赖具体的题目。同时,只要在同一维度上考生的能力水平分布足够宽,也就是在考生样本中,既要有部分能答对该题目的考生,也要有些无法答对的考生。那么,不管考生分布形态如何,项目参数的估计也不会依赖于具体的考生样本群体及其分布形态。
2.4.2 项目参数与考生能力参数具有统一的量表
根据IRT模型估计出来的考生能力参数与项目难度参数具有统一的量表,即考生参数与项目参数可以被标定在同一个参照尺度上。例如,能力估计值为0.5的考生答对难度值为0.4的题目的概率大于答错的概率,而答对难度估计值为0.6的题目的概率则小于答错的概率。同时,在实际应用中,用于测试能力水平为0.5的考生的最佳题目的难度也应该在0.5左右。距离0.5太远的题目,对该考生来说或者太容易或者太难,并不能有效测量出考生的水平。
2.4.3 可以针对不同考生精确估计每个项目和测验的测量误差
IRT相比于CTT引进了题目信息函数的概念,并用信息量来替代信度的概念。信度与测量标准误差之间存在反比关系,一个试题提供的信息函数越大,测试的误差就越小。信息函数不仅与参测题目性质有关,还与参测群体的水平有关,即对不同能力的考生施测相同试题,其测验误差并不相同。同时,测验题目信息函数具有可加性,一个测验包含多个题目,它们的信息函数的累加值可以被称为测验信息函数。有了不同题目对不同考生单独计算信息量值的方法,我们就可以对每个考生的特质水平估计误差进行主动控制,从而更加有利于指导测验的编制。
3. 结论
综上,我们为大家简单介绍了教育测量的含义,并深入描述了教育测量中广泛应用的现代测验理论IRT(项目反应理论),包括其背后的逻辑和涵盖的不同模型。相较于老师们主观组合、实施的考试和经典测验理论,应用IRT理论和技术可以更加精准地测量学生的学科水平。其实,关于IRT的相关技术还有很多,能帮助我们实现各种不同的测评目的,指引我们的测评设计。而在应用场景方面,IRT除了应用在大型测评中的具体测验设计和计分中以外(如:我国大学英语四六级考试),IRT的技术理论还可以用于题库建设和自适应测评的开发,感兴趣的伙伴可以持续关注硅谷研发部发表的文章,我们会在之后的专题文章中和大家分享不同的测验理论和技术的应用。欢迎大家持续关注!
参考文献
- Birnbaum, A. (1957). Efficient design and use of tests of a mental ability for various decision-making problems. (Series Report no. 58-16, Project no. 7755-23, USAF School of Aviation Medicine, Randolph Air Force Base, Texas.)
- De Ayala, R. J. (2008). The theory and practice of item response theory. Guilford Publications.
- Lord, F. (1952). A theory of test scores. Psychometric monographs.
- Rasch, G. (1960). Probabilistic models for some intelligence and attainment tests. Copenhagen: Danish Institute for Educational Research.
- 戴海崎, 张锋. (2018). 心理与教育测量. 暨南大学出版社.
- 罗照盛. (2012). 项目反应理论基础. 北京师范大学出版社.
- 张厚粲. (2017). 教育测量学: 高考科学化的技术保障. 中国考试, (8), 4.
![]()
招聘信息
好未来技术团队正在热招测试、后台、运维、客户端等各个方向高级开发工程师岗位,大家可扫描下方二维码或微信搜索“好未来技术”,点击公众号“技术招聘”栏目了解详情,欢迎感兴趣的伙伴加入我们!
也许你还想看
摩比秀换装游戏系统设计与实现(基于Egret+DragonBones龙骨动画)
