
互联网上有很多很棒的机器学习教程。但是,它们大多数都专注于机器学习的特定部分,例如,探索数据,建立模型,训练和评估。其中很少有人介绍构建机器学习模型的完整步骤。
最受欢迎的文章之一概述了进行机器学习的步骤,这是Google云端平台推出的郭玉峰的《机器学习的7个步骤》。
提出了以下七个步骤:
- Gathering data
- Preparing data (and exploring data)
- Choosing a model
- Training
- Evaluation
- Hyperparameter tuning
- Prediction (and save model)
在本文中,我们将实践上述步骤,并从头开始构建机器学习模型。
定义问题和环境设置
在开始讨论细节之前,对于任何机器学习项目,我们要做的第一件事是为我们的机器学习模型定义问题。
对于本教程,我们将使用Kaggle的Titanic Dataset。这是一个非常著名的数据集,通常是学生学习机器学习的第一步。
假设我们被要求创建一个可以预测泰坦尼克号生存时间的系统。
环境设置
为了运行本教程,您需要安装
TensorFlow 2, TensorBoard 2, numpy, pandas, matplotlib, seaborn
它们都可以直接通过PyPI安装,我强烈建议创建一个新的虚拟环境。最好避免使用base(root),因为它可能会破坏系统。
有关创建Python虚拟环境的教程,您可以看一下:
1. Gathering data
定义好问题后,就该进行机器学习的第一步,那就是收集数据。这一步是最重要的,因为您收集的数据的质量和数量将直接决定您的预测模型的质量。
在本教程中,数据将来自Kaggle。让我们导入一些库并加载数据以开始使用:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline让我们将train.csv和test.csv文件加载到pandas DataFrame中。
df_train_raw = pd.read_csv('data/titanic/train.csv')
df_test_raw = pd.read_csv('data/titanic/test.csv')
df_train_raw.head()
preview of Titanic data
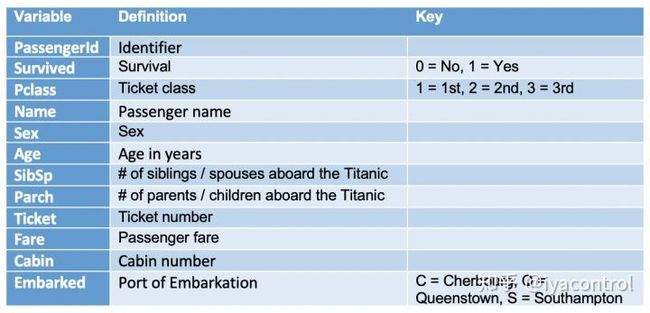
Data Dictionary from Kaggle
2. Preparing data
让我们从一些探索性数据分析(EDA)开始。我们将从检查缺失值开始。
2.1 Missing values
我们可以使用seaborn来创建一个简单的热图,以查看缺少的值:
sns.heatmap(df_train_raw.isnull(),
yticklabels=False,
cbar=False,
cmap='viridis')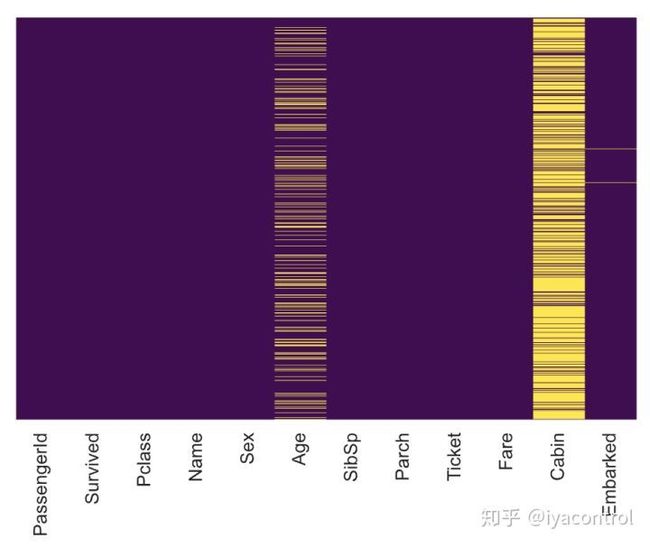
output of seaborn heatmap plot for missing values
年龄,机舱和出发缺少值。年龄缺失的比例可能很小,不足以用某种形式的估算合理地替代。查看“机舱”列,该数据似乎缺少太多值,无法做有用的事情。我们可能会在以后放下机舱,或将其更改为其他功能,例如“机舱已知:1或0”。出发的比例很小,在本教程中,我们保留它。
2.2 Visualizing some more of the data
让我们继续可视化更多数据:
sns.countplot(x='Survived', data=df_train_raw, palette='RdBu_r')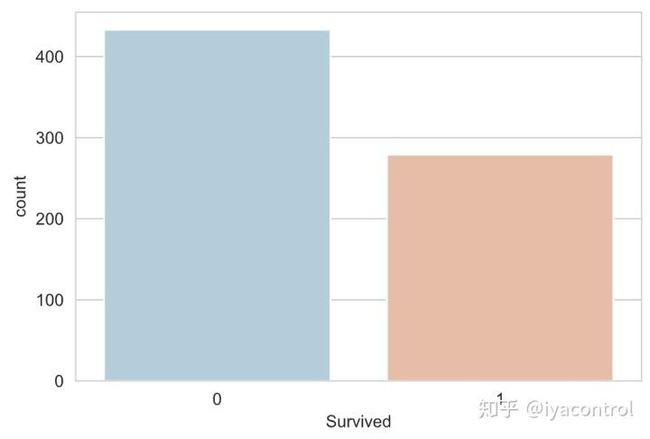
plot of Survived
sns.countplot(x='Survived',
hue='Sex',
data=df_train_raw,
palette='RdBu_r')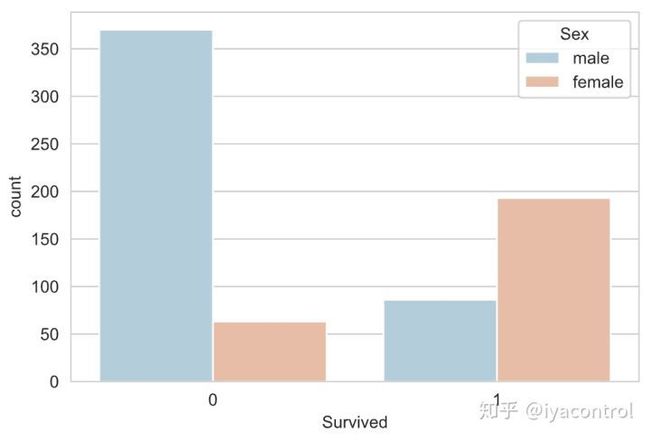
sns.countplot(x='Survived',
hue='Pclass',
data=df_train_raw,
palette='rainbow')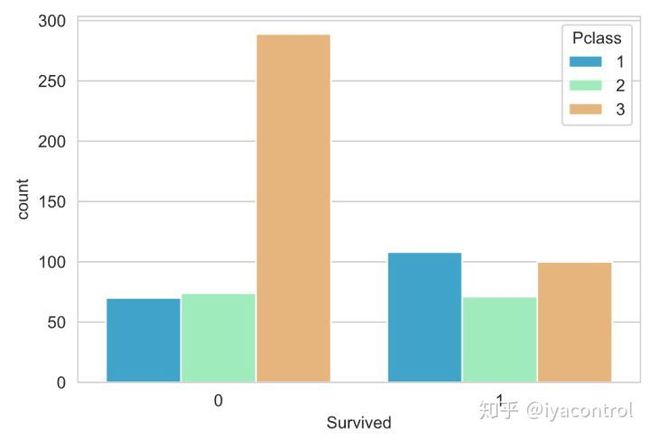
sns.distplot(df_train_raw['Age'].dropna(),
kde=True,
color='darkred',
bins=30)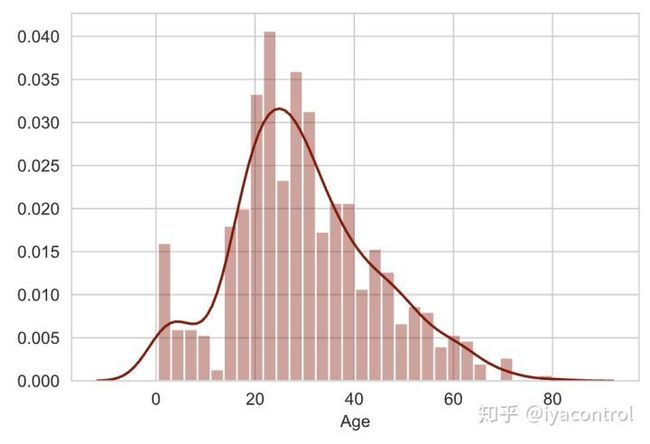
sns.countplot(x='SibSp',data=df_train_raw)
df_train_raw['Fare'].hist(color='green',
bins=40,
figsize=(8,4))
2.3 Data cleaning
我们想用某种形式的估算来代替失踪的时代。一种方法是填写所有乘客的平均年龄。但是,我们可以对此有所了解,并按旅客等级检查平均年龄。例如:
sns.boxplot(x='Pclass',
y='Age',
data=df_train_raw,
palette='winter')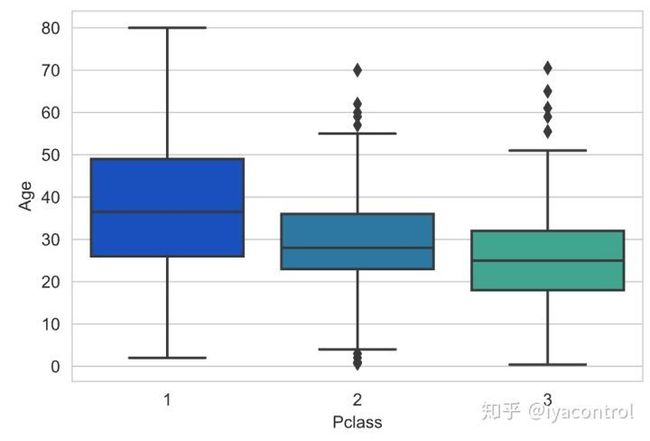
我们可以看到,较高阶层的较富裕乘客往往年龄较大,这是有道理的。我们将使用这些平均年龄值根据年龄的Pclass进行估算。
def impute_age(cols):
Age = cols[0]
Pclass = cols[1]
if pd.isnull(Age):
if Pclass == 1:
return 37
elif Pclass == 2:
return 29
else:
return 24
else:
return Age现在,我们应用该功能并检查其是否有效:
# Make a copy for test only
train_copy = df_train_raw.copy()
train_copy['Age'] = train_copy[['Age','Pclass']]
.apply(impute_age, axis=1)
# check that heat map again
sns.heatmap(train_copy.isnull(),
yticklabels=False,
cbar=False,
cmap='viridis')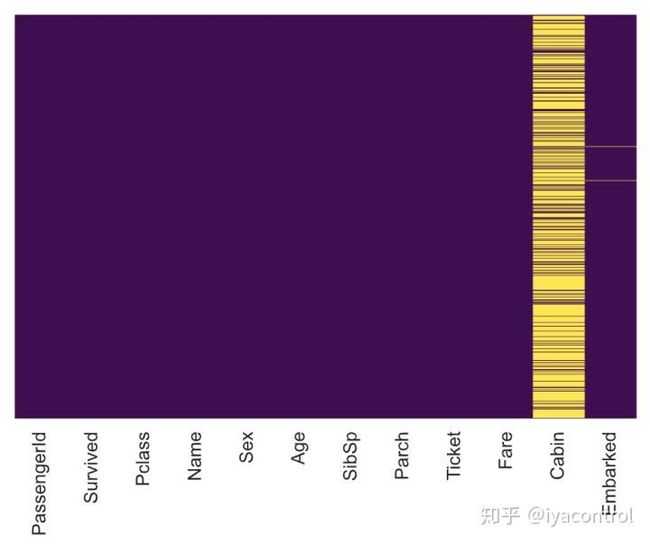
非常好! impute_age()有效。让我们继续进行转换,并删除“机舱”列。
2.4 Converting Categorical Features
我们需要将分类功能转换为一键编码。否则,我们的机器学习算法将无法直接将这些功能作为输入。
让我们使用info()检查列数据类型:
df_train_raw.info()
RangeIndex: 712 entries, 0 to 711
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 712 non-null int64
1 Survived 712 non-null int64
2 Pclass 712 non-null int64
3 Name 712 non-null object
4 Sex 712 non-null object
5 Age 566 non-null float64
6 SibSp 712 non-null int64
7 Parch 712 non-null int64
8 Ticket 712 non-null object
9 Fare 712 non-null float64
10 Cabin 168 non-null object
11 Embarked 710 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 66.9+ KB 有5列具有对象数据类型的列。其中,不需要名称,机票和机舱。另外,根据上面看到的数据字典,我们注意到Pclass是分类数据。让我们做一个函数preprocessing()来保留这些有用的数字功能,并将Pclass,Sex和Embarked转换为一键编码。
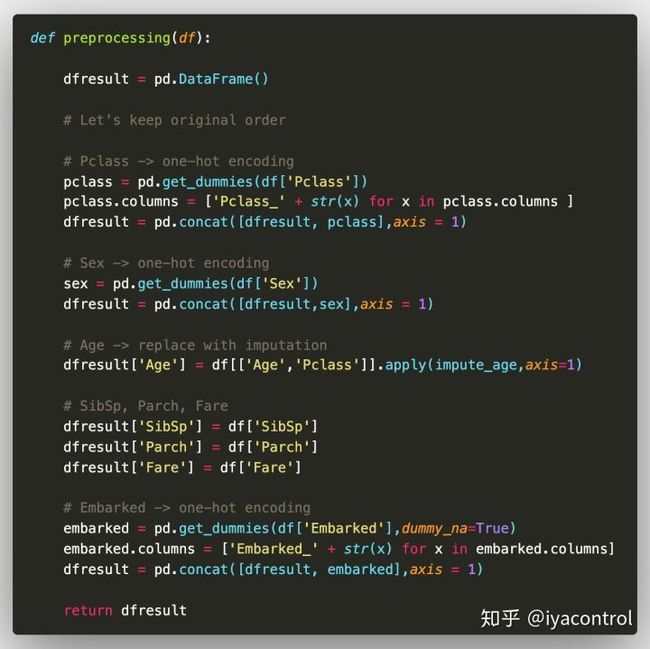
让我们应用该功能并创建训练和测试数据集以构建我们的机器学习模型。
x_train = preprocessing(df_train_raw)
y_train = df_train_raw['Survived'].values
x_test = preprocessing(df_test_raw)
y_test = df_test_raw['Survived'].values
print("x_train.shape =", x_train.shape )
print("x_test.shape =", x_test.shape )通过在上面运行,您应该获得如下训练和测试数据集的形状:
x_train.shape = (712, 13)
x_test.shape = (179, 13)让我们看看x_train.head()的数据:

我们的数据已准备好用于模型。
3. Choose a model
在TensorFlow 2.0中有三种方法来实现神经网络架构:
- Sequential API: 是使用Keras入门和运行的最简单方法。
- Functional API: 适用于更复杂的模型。
- Model Subclassing: 完全可自定义,使您能够实现自己的模型自定义前向传递。
为简单起见,让我们使用最简单的方法:带有Sequential()的Sequential API。让我们继续前进,构建一个具有3个密集层的神经网络。每一层中的所有参数均已进行硬编码,如下所示:
import tensorflow as tf
from tensorflow.keras import models, layers
tf.keras.backend.clear_session()
model = models.Sequential()
model.add(layers.Dense(10, activation='relu', input_shape=(13,)))
model.add(layers.Dense(20, activation='relu' ))
model.add(layers.Dense(1, activation='sigmoid'))
model.summary()下面是model.summary() 的输出:

4. Training
首先,让我们使用model.compile()配置模型:
- 使用优化程序随机梯度下降(SGD)
- 使用二进制交叉熵损失函数(binary_crossentropy)进行二进制分类
- 为简单起见,请在培训和测试期间使用“准确性”作为我们的评估指标来评估模型
对于训练,有三种方法可以训练Keras模型:
- 对模型使用model.fit()以获取固定数量的纪元。
- 使用model.train_on_batch() 可以只对一个批次进行一次训练。
- 创建自定义训练循环。
在本教程中,让我们继续最简单的方式model.fit()。
# Convert DataFrame into np array
x_train = np.asarray(x_train)
y_train = np.asarray(y_train)
# Get around with KMP duplicate issue
import os
os.environ['KMP_DUPLICATE_LIB_OK']='True'
# Use binary cross entropy loss function for binary classification
model.compile(optimizer='sgd',
loss='binary_crossentropy',
metrics=['accuracy'])
history = model.fit(x_train,y_train,
batch_size= 64,
epochs= 30,
validation_split=0.2
)如果一切运行顺利,我们应该得到如下输出。
Train on 569 samples, validate on 143 samples
Epoch 1/30
569/569 [==============================] - 1s 2ms/sample - loss: 0.5568 - accuracy: 0.7206 - val_loss: 0.6139 - val_accuracy: 0.6713
Epoch 2/30
569/569 [==============================] - 0s 91us/sample - loss: 0.5639 - accuracy: 0.7047 - val_loss: 0.6212 - val_accuracy: 0.6643
Epoch 3/30
569/569 [==============================] - 0s 112us/sample - loss: 0.5705 - accuracy: 0.6907 - val_loss: 0.6379 - val_accuracy: 0.6573
Epoch 4/30
569/569 [==============================] - 0s 109us/sample - loss: 0.5538 - accuracy: 0.7065 - val_loss: 0.6212 - val_accuracy: 0.6713
......
......
Epoch 30/30
569/569 [==============================] - 0s 102us/sample - loss: 0.5597 - accuracy: 0.7065 - val_loss: 0.6056 - val_accuracy: 0.72035. Model Evaluation
训练结束后,就可以使用“模型评估”来查看模型是否良好。模型评估通常涉及:
- 绘制损失和准确性指标的进度图
- 针对从未用于训练的数据测试我们的模型。这是我们前面放置的测试数据集
df_test发挥作用的地方。
让我们创建一个函数plot_metric()来绘制指标。
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
def plot_metric(history, metric):
train_metrics = history.history[metric]
val_metrics = history.history['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
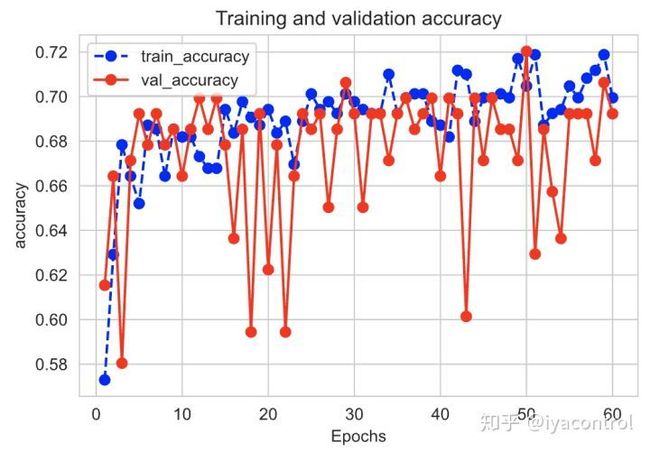
plt.show()通过运行plot_metric(history,'loss')绘制损失进度。
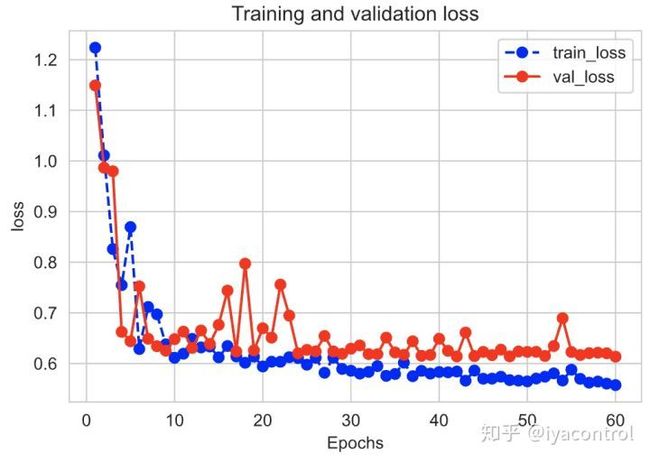
通过运行plot_metric(history,'accuracy')绘制准确性进度。
针对测试数据集测试我们的模型:
# Convert DataFrame into np array
x_test = np.asarray(x_test)
y_test = np.asarray(y_test)
model.evaluate(x = x_test,y = y_test)而且我们应该得到具有损失和准确性的输出,如下所示:
179/1 [====] - 0s 43us/sample - loss: 0.5910 - accuracy: 0.6760
[0.5850795357586951, 0.67597765]6. Hyperparameter tuning
太酷了,我们已经对第一个机器学习模型进行了评估。现在该看看我们是否可以通过任何方式进一步改进它。我们可以通过旋转超参数来做到这一点。当我们进行第一次训练时,我们隐式假设了一些参数,现在是时候回过头来测试这些假设并尝试其他值了。
对于本教程,我们只关注模型中以下三个超参数的实验:
- 第一密集层中的单位数
- 第二致密层中的单位数
- 优化器
6.1 Experiment setup
首先,首先加载TensorBoard notebook扩展程序:
# Load the TensorBoard notebook extension
%load_ext tensorboard然后,添加一条语句以清除上一次运行中的所有日志。如果您不清除仪表盘,则会弄乱仪表盘。
# Clear any logs from previous runs
!rm -rf ./logs/导入TensorBoard HParams插件:
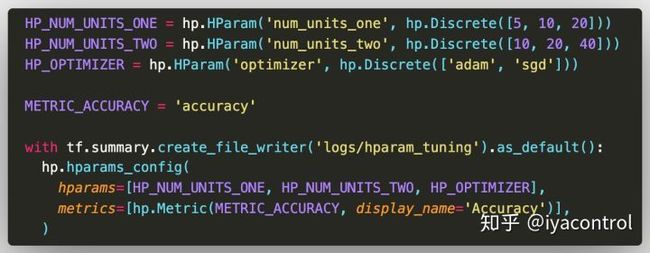
from tensorboard.plugins.hparams import api as hp列出要尝试的值,并将实验配置记录到TensorBoard。
- 第一层中的单元数为
5、10和20 - 第二层的单元数为
10、20和40 -
adam和sgd用于优化程序
6.2 Adapt TensorFlow runs to log hyperparameters and metrics
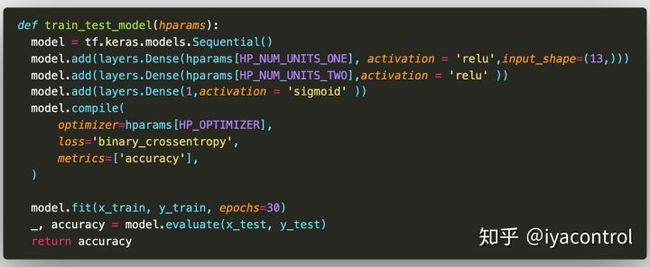
我们的模型非常简单:3个密集层。尽管不再对超参数进行硬编码,但代码看起来很熟悉。相反,超参数在hyparams字典中提供,并在整个训练功能中使用:
对于每次运行,请记录具有超参数和最终精度的hparams摘要:
def run(run_dir, hparams):
with tf.summary.create_file_writer(run_dir).as_default():
hp.hparams(hparams) # record the values used in this trial
accuracy = train_test_model(hparams)
tf.summary.scalar(METRIC_ACCURACY, accuracy, step=1)6.3 Start runs and log them
现在,我们可以尝试进行多个实验,并使用不同的一套超级血压计来训练每个实验。为简单起见,让我们使用网格搜索来尝试离散参数的所有组合以及实值参数的上限和下限。
session_num = 0
for num_units_one in HP_NUM_UNITS_ONE.domain.values:
for num_units_two in HP_NUM_UNITS_TWO.domain.values:
for optimizer in HP_OPTIMIZER.domain.values:
hparams = {
HP_NUM_UNITS_ONE: num_units_one,
HP_NUM_UNITS_TWO: num_units_two,
HP_OPTIMIZER: optimizer,
}
run_name = "run-%d" % session_num
print('>> Starting trial: %s' % run_name)
print({h.name: hparams[h] for h in hparams})
run('logs/hparam_tuning/' + run_name, hparams)
session_num += 1如果一切运行顺利,我们应该得到如下输出:
6.4 Visualize the results in TensorBoard’s HParams plugin
运行完成后,打开终端并cd进入项目目录。然后,现在可以通过在终端中运行以下命令来打开HParams仪表板:
admin@Mac:~/Code/WorkSpace/machine-learning/tf2
⇒ tensorboard --logdir logs/hparam_tuning
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all
TensorBoard 2.0.0 at http://localhost:6006/ (Press CTRL+C to quit)在浏览器中打开仪表板,然后直接转到HPARAMS-> PARALLEL COORDINATES VIEW
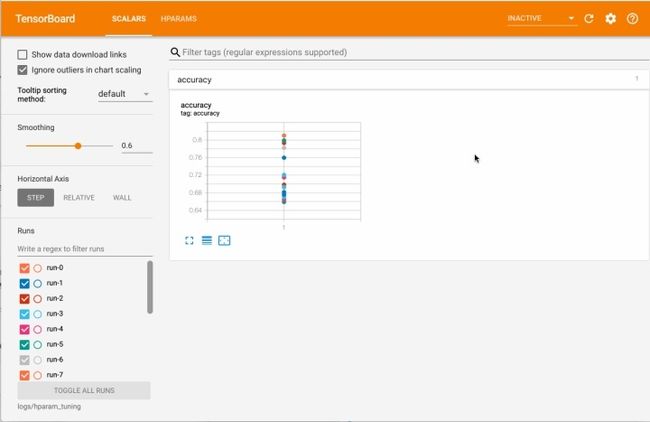
通过查看“平行坐标”视图,然后在精度轴上单击并拖动,可以选择精度最高的运行。
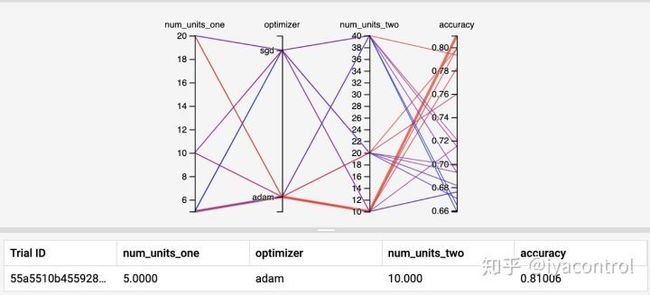
当这些运行通过不同的超参数时,我们可以得出以下结论:
- 第一层5个单元
- 第二层10个单位
- “ adam”优化器
在这些实验中表现最好。
7. Prediction (and save model)
现在,就准确度而言,我们已经有了最好的机器学习模型。最后一步是使用此模型进行预测或推断。这是所有这些工作的重点,在那里机器学习的价值得以实现。我们最终可以使用我们的模型来预测乘客是否存活。
使用模型进行预测:
model.predict(x_test[0:10])
array([[0.56895125],
[0.37735564],
[0.5005745 ],
[0.60003537],
[0.5371451 ],
[0.36402294],
[0.49169463],
[0.49049523],
[0.4984674 ],
[0.1470165 ]], dtype=float32)使用该模型为输入样本生成类别预测。
model.predict_classes(x_test[0:10])
array([[1],
[0],
[1],
[1],
[1],
[0],
[0],
[0],
[0],
[0]], dtype=int32)最后,我们可以将整个模型保存到单个HDF5文件中:
model.save('data/keras_model.h5')并加载通过save()保存的模型:
model = models.load_model('data/keras_model.h5')
# Predict class
model.predict_classes(x_test[0:10])结论
本文是一个快速教程,主要向所有人展示如何将Google的机器学习的7个步骤付诸实践。我试图避免使用许多机器学习概念,并尽量简化本教程。
在实际的应用程序中,它们还有很多要考虑的地方。例如,选择评估指标,特征缩放,选择有意义的特征,拆分数据集,处理过度拟合和欠拟合等。此外,本教程仅适用于结构化数据,而实际数据并不总是结构化数据,所有诸如图像,音频或文本之类的东西都是非结构化数据。
PS:本文属于翻译,原文