【数据分析 R语言实战】学习笔记 第三章 数据预处理 (下)
3.3缺失值处理
R中缺失值以NA表示,判断数据是否存在缺失值的函数有两个,最基本的函数是is.na()它可以应用于向量、数据框等多种对象,返回逻辑值。
> attach(data) The following objects are masked fromdata (pos = 3): city, price, salary > data$salary=replace(salary,salary>5,NA) > is.na(salary) [1] FALSEFALSE TRUE FALSE TRUE TRUE TRUE FALSE FALSE FALSE FALSEFALSE > sum(is.na(salary)) [1] 4
另一个判断缺失值的函数是complete.cases(),它同样返回逻辑值向量,但值与is.na()的相反:缺失值为FALSE,正常数据为TRUE,利用它来选取无缺失数据的行非常方便。
> complete.cases(data$salary) [1] TRUE TRUE FALSE TRUE FALSE FALSEFALSE TRUE TRUE TRUE TRUE TRUE
3.3.2判断缺失模式
存在缺失数据时,需要进一步判断数据的缺失模式,判断是否是随机的,然后才能确定处理的方法。
程序包mice,利用链式方程进行多元插补,可以处理混合变量类型的数据缺失,自动产生填补变量的预测变量,是处理缺失值的重要工具。
> library(mice) > data$price=replace(price,price>5,NA) > md.pattern(data) price salary city 5 1 1 0 1 3 0 1 0 2 4 1 0 0 2 3 4 12 19
输出结果中的“1”表示没有缺失数据,“0”表示存在缺失数据。第1列第1行的“5”表示有5个样本是完整的,下面的“3”表示有3个样本缺少了salary这一变量的值,第1列最后一个数字“4”表示有4条记录在salary和price上都有缺失。最后一行表示各个变量缺失的样本数合计。
程序包VIM提供了在R中探索数据缺失情况的新工具,实现缺失模式的可视化
> library(VIM) > aggr(data)
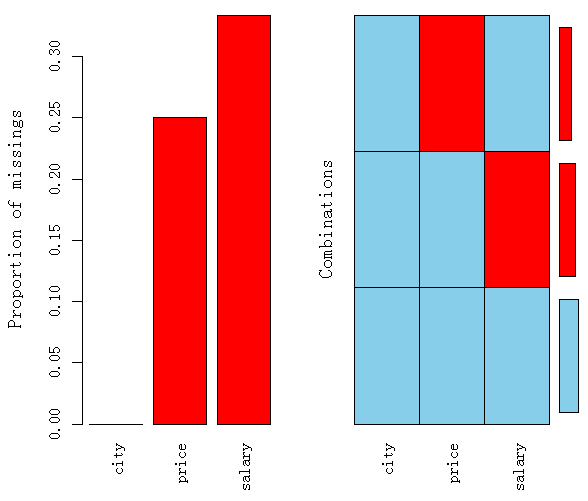
第一个图由小条形的长度显示各变量缺失数据比例
第二个图显示了综合的缺失模式,可以与md.pattern()生成的结果对照观察,其中浅色方框表示完整数据,深色框表示缺失值。底部的颜色框高度反映了相应组合的频率。
3.3.3处理缺失数据
(1)删除缺失样本
过滤掉缺失样本是最简单的方式,其前提是缺失数据的比例较少,而且缺失数据是随机出现的,这样删除缺失数据后对分析结果影响不大。 R可以使用complete.cases()指令选取完整的记录,有缺失值的行则删去不要。
> data1=data[complete.cases(data$salary),] > dim(data1) [1] 8 3
或
> data2=data[!is.na(salary),] > dim(data2) [1] 8 3
对于有多个变量缺失的数据,如果想直接删除所有的缺失值,可以通过na.omit()函数来完成,
> data3=na.omit(data) > dim(data3) [1] 5 3
(2)替换缺失值
> data[is.na(data)]=mean(salary[!is.na(salary)])
(3)多重插补法
多重插补(Multiple Imputation)是用于填补复杂数据缺失值的一种方法,该方法通过变量间关系来预测缺失数据,利用蒙特卡罗随机模拟方法生成多个完整数据集,再对这些数据集分别进行分析,最后对这些分析结果进行汇总处理。FSC是基于链式方程的插补方法,因此也称为MICE (Multiple Imputation by Chained Equations )。它与其他多重插补算法的本质区别是,它在进行插补时不必考虑被插补变量和协变量的联合分布,而是利用单个变量的条件分布逐一进行插补。在R语言中通过程序包mice中的函数mice()可以实现该方法,它随机模拟多个完整数据集并存入imp,再对imp进行线性回归,最后用pool函数对回归结果进行汇总。
3.4数据整理
3.4.1数据合并
(1)函数cbind(),rbind()
> a=c("hk",12,10)
> data1=rbind(data,a)
> data1
cityprice salary
………
12 qa 6 5
13 hk 12 10
(2)构造data.frame
对数据“整容”最简单的思路是把数据向量化,再按要求用向量构建其他类型的对象。一些结构相似的对象,如向量(数值型、字符型、逻辑型)、因子、数值矩阵、列表或其他数据框等,可以被合并为一个数据框。
> weight=c(150,135,210,140)
> height=c(65,61,70,65)
> gender=c("F","F","M","F")
> stu=data.frame(weight,height,gender)
> stu
weightheight gender
1 150 65 F
2 135 61 F
3 210 70 M
4 140 65 F
合并时,变量名称就白动变成了新数据框的列名,也可以用names()重新给其赋值。
> row.names(stu)=c("Alice","Bob","Cal","David")
> stu
weightheight gender
Alice 150 65 F
Bob 135 61 F
Cal 210 70 M
David 140 65 F
(3)函数merge()
在R中合并两个数据集可以通过专门的函数merge()来实现。merge通过相同的列或行名来识别,合并两个数据框或列表,其调用格式如下:
merge(x, y, by = intersect(names(x),names(y)),by.x = by, by.y = by, all = FALSE, all.x = all, all.y = all,sort =TRUE, suffixes = c(".x",".y"),
incomparables = NULL, ...)
x,y 要合并的数据集
by指定合并的依据(相同的行或列)
by.x by.y分别为第一个数据框和第二个数据框要连接的列名
all, all.x, all.y逻辑值,默认为FALSE。
> index=list("city"=data$city,"index"=1:12)
> index
$city
[1]"bj" "sh" "gz" "ab" "cd""as" "ac" "fa" "ff" "ee""er" "qa"
$index
[1] 1 2 3 4 5 6 7 8 9 10 11 12
> data.index=merge(data,index,by="city")
> data.index
cityprice salary index
1 ab 6 5 4
2 ac 5 NA 7
3 as 3 NA 6
4 bj 1 2 1
5 cd 1 NA 5
6 ee 3 4 10
7 er 5 3 11
8 fa 6 1 8
9 ff 1 2 9
10 gz 5 NA 3
11 qa 6 5 12
12 sh 3 4 2
3.4.2选取数据的子集
在R中,选取数据子集用中括号[]
> data[data$salary>6]
3.4.3数据排序
R中的排序函数sort()只能对向量进行简单的排序,对含有多变量的数据集,需要用order指令来完成,其调用格式如下:
order(..., na.last = TRUE, decreasing =FALSE)
> order.price=order(data$price)
或
> sort.list(data$price)
指令order返回向量排序后各数字的原始位置,与之非常相关的指令是秩(rank ),它返回每个数字在整个向量中的秩,可以简单地理解为各个数字的大小顺序。
> rank(data$price)
3.5长宽格式的转换.
>t (data)
3.5.1揉数据函数
R中有两个揉数据函数stack()和unstack|(),用于数据长格式和宽格式之间的转换.
stack()把一个数据框转换成两列:一列为数据,另一列为数据对应的列名称。
unstack()是stack的逆过程,被转换的对象包含两列,它把数据列按照因子列的不同水平重新排列,分离为不同的列。
3.5.2揉数据的最佳伴侣
程序包reshape2是reshape的重写版,是专门用于数据集形状转换的,一般用户常使用melt(), acast()和dcast(),它们却可以把数据“揉成各种形状。
melt本身的意思是溶解、分解,其作用在一个数据集上其实就是拆分数据,它的对象一可以是数组(array )、数据框或列表。
> library(reshape2)
> data(airquality)
> str(airquality)
'data.frame': 153obs. of 6 variables:
$Ozone : int 41 36 12 18 NA 28 23 19 8 NA ...
$ Solar.R:int 190 118 149 313 NA NA 299 99 19 194...
$Wind : num 7.4 8 12.6 11.5 14.3 14.9 8.6 13.8 20.1 8.6...
$Temp : int 67 72 74 62 56 66 65 59 61 69 ...
$Month : int 5 5 5 5 5 5 5 5 5 5 ...
$ Day : int 1 2 3 4 5 6 7 8 9 10 ...
> longdata=melt(airquality,id.vars=c("Ozone",'Month',"Month","Day"),measure.vars=2:4)
> str(longdata)
'data.frame': 459obs. of 6 variables:
$Ozone : int 41 36 12 18 NA 28 23 19 8 NA ...
$Month : int 5 5 5 5 5 5 5 5 5 5 ...
$Month : int 5 5 5 5 5 5 5 5 5 5 ...
$ Day : int 1 2 3 4 5 6 7 8 9 10 ...
$variable: Factor w/ 3 levels "Solar.R","Wind",..: 1 1 1 1 11 1 1 1 1 ...
$value : num 190 118 149 313 NA NA 299 99 19 194 ...
利用ggplot2在一个图形中多维度地展示value值
> library(ggplot2) > p=ggplot(data=longdata,aes(x=Ozone,y=value,color=factor (Month))) > p+geom_point(shape=20,size=4)+facet_wrap(~variable,scales="free_y")+geom_smooth(aes(group=1),fill="gray80")
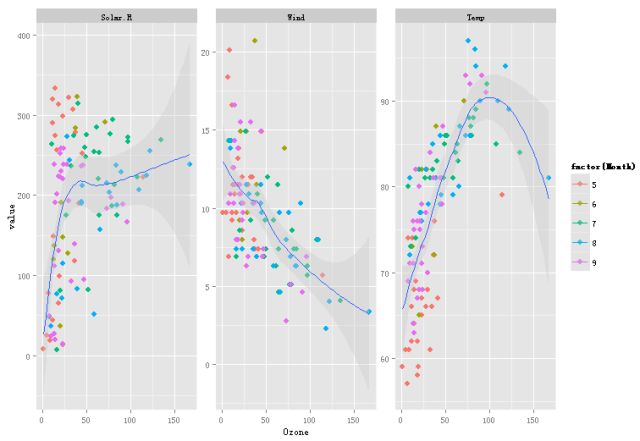
和stack()一样,melt()也有对应的函数用来还原数据:acast()用于数组,dcast()用于数据框,其中的参数formula是一个公式,左边的每个变量都会成为新数据集中的一列,右边的变量是因子,其每个水平行在新数据集中成为一列,从而把长格式数据转换为短格式。
