本文主要介绍Hadoop的一些基本信息及完全分布式安装,每一步都是笔者亲自操作所记录下来的,现分享出来希望能帮助到正准备研究Hadoop的朋友
Hadoop介绍
Hadoop由HDFS、MapReduce、Hbase、Hive和ZooKeeper等成员组成,其中最基础最重要元素为底层用于存储集群中所有存储节点文件的文件系统HDFS(Hadoop Distributed File System)来执行MapReduce程序的MapReduce引擎。
Hadoop子项目家族

- Pig是一个基于Hadoop的大规模数据分析平台,Pig为复杂的海量数据并行计算提供了一个简单的操作和编程接口;
- Hive是基于Hadoop的一个工具,提供完整的SQL查询,可以将sql语句转换为MapReduce任务进行运行;
- ZooKeeper:高效的,可拓展的协调系统,存储和协调关键共享状态;
- HBase是一个开源的,基于列存储模型的分布式数据库;
- HDFS是一个分布式文件系统,有着高容错性的特点,适合那些超大数据集的应用程序;
- MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。
- Avro是一个基于二进制数据传输高性能的中间件
- chukwa 是一个开源的用于监控大型分布式系统的数据收集系统,Chukwa 还包含了一个强大和灵活的工具集,可用于展示、监控和分析已收集的数据。
Hadoop项目架构

Namenod(名称节点):HDFS的守护程序,纪录文件是如何分割成数据块的,以及这些数据块被存储到哪些节点上,对内存和I/O进行集中管理,是个单点,发生故障将使集群崩溃
Secondary Namenode(辅助名称节点):监控HDFS状态的辅助后台程序,每个集群都有一个,与NameNode进行通讯,定期保存HDFS元数据快照,当NameNode故障可以作为备用NameNode使用
DataNode (数据节点):每台从服务器都运行一个,负责把HDFS数据块读写到本地文件系统
JobTracker(作业跟踪器):用于处理作业(用户提交代码)的后台程序,决定有哪些文件参与处理,然后切割task并分配节点,监控task,重启失败的task(于不同的节点),每个集群只有唯一一个JobTracker,位于Master节点
Tasktracker(任务跟踪器):与负责存储数据的DataNode相结合,其处理结构上也遵循主/从架构。
master:Namenode、Secondary Namenode、Jobtracker
slave:Tasktracker、Datanode
运行模式
- 单机模式:安装简单,几乎不用作任何配置,但仅限于调试用途
- 伪分布模式:在单节点上同时启动namenode、datanode、jobtracker、tasktracker、secondary namenode等5个进程,模拟分布式运行的各个节点
- 完全分布式模式:正常的Hadoop集群,由多个各司其职的节点构成 (至少3台否则无法构成集群)
安装环境
虚拟机、3台CentOS(linux其他发行版本均可以),java jdk,xshell5(连接工具)
完全分布式安装
这里我使用了3台虚拟机模拟3个节点进行安装

下载解压
下载解压Hadoop安装包,我这里选用0.20.2版本,目前版本已经发行至2.8.0版本
地址:http://hadoop.apache.org/releases.html
进入文件目录对Hadoop进行解压,使用如下命令
[grid@h1 ~]$ tar –zxvf hadoop-0.20.2.tar.gz
配置文件介绍
| 文件名 | 格式 | 描述 |
|---|---|---|
| hadoop-env.sh | bash脚本 | 在运行Hadoop的脚本中使用的环境变量 |
| core-site.xml | hadoop配置XML | Hadoop核心配置,例如HDFS和MapReduce中很普遍的I/O设置 |
| hdfs-site.xml | hadoop配置XML | HDFS后台程序设置的配置:名称节点,第二名称节点和数据节点 |
| mapred-site.xml | hadoop配置XML | MapReduce后台程序设置的配置jobtracker和tasktracker |
| masters | 纯文本 | 记录运行第二名称节点的机器(一行一个)的列表 |
| slaves | 纯文本 | 记录运行数据节点和tasktracker的器(一行一个)的列表 |
-
编辑conf/hadoop-env.sh文件(注意0.23版后配置文件的位置有所变化)将jdk配置为你jdk安装目录,如下:
 jdk变量
jdk变量 -
编辑conf/core-site.xml配置文件
fs.default.name:指定namenode的端口和ip地址(若模拟伪分布模式,写localhost即可,若是集群应该写实际的ip地址或ip地址的hosts映射)
 core-site.xml
core-site.xml 编辑配置文件conf/hdfs-site.xml
dfs.data.dir:指定数据节点要存放的数据的目录
dfs.replication:在分布式节点里面要把这个数据块复制多少份,我这里是3台应该改为3,控制最多要写多少份(若模拟伪分布式写1即可)

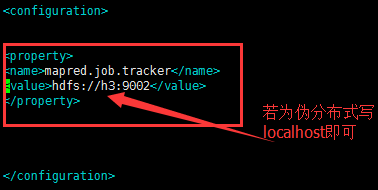
4.编辑配置文件conf/mapred-site.xml
mapred.job.tracker:配置作业跟踪器在什么地方,这项配置为核心,端口配置与core-site.xml不一致即可
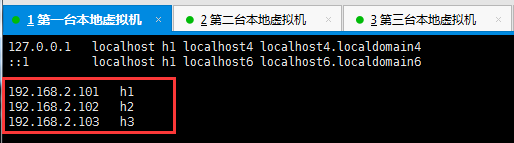
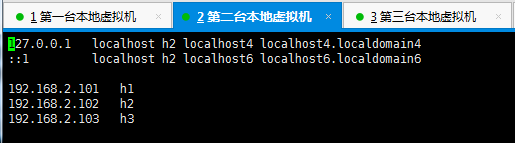
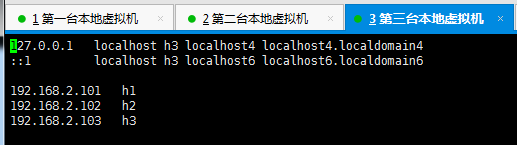
配置hosts
为3台机器分别配置hosts,hosts为一台机器的映射,后续使用ip的地方我们直接使用配置的映射名即可,配置如下:
配置秘钥
生成秘钥对
配置后可以免密码连接其他服务器,方便集群运行时一个节点调用另外一个节点,进入当前目录用户,运行如下命令,我这里是grid用户,所以进入/home/grid目录
[grid@h1 ~]$ ssh-keygen -t rsa
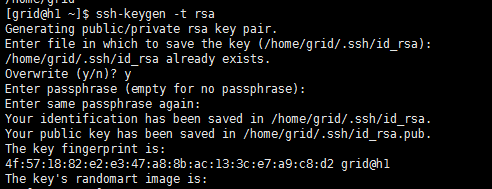
运行后会生成.ssh目录,.ssh默认是隐藏文件,可使用ls –a进行查看隐藏目录,接下来进入.ssh目录
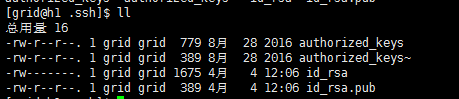
执行如下命令,复制id_rsa.pub文件去覆盖authorized_keys
[grid@h1 .ssh]$ cp id_rsa.pub authorized_keys
注:(如果某一台服务器的authorized_keys里面记录了某一把公钥,对方用此公钥来连接这台服务器时,你会去查authorized_keys里面有没有这把公钥,如果有的话,你就会让他免密码连入)
配置免密登录
将3台机器各自的authorized_keys文件中的内容复制出来组成一个含3台机器公钥的大文件,然后覆盖authorized_keys,3台机器的authorized_keys相同,做完这些事这些节点就能够免密码互相进行登录,这里我列举了其中一台配置,如下图:
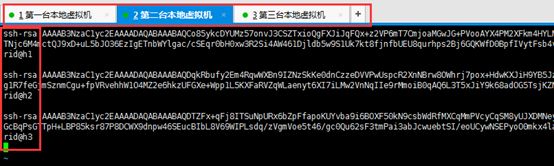
配置另外两台
若不想一台台去配置可使用如下命令跨节点拷贝,然后修改每个配置文件属性即可
scp命令是ssh所带的命令,在前面我们配置过免密登录,因此在此处使用该命令跨节点拷贝是可行的,命令如下:
[grid@h1 ~]$ scp -r ./hadoop-0.20.2 h2:/home/grid
[grid@h1 ~]$ scp -r ./hadoop-0.20.2 h3:/home/grid
格式化分布式文件系统
分别对三台机器进行如下操作,进入bin目录执行如下命令,格式化这个名称节点,主要是在名称节点上面建立一系列的结构用来存放整个hdfs的元数据,输出如下图则成功:
[grid@h1 bin]$ ./hadoop namenode –format

启动进程

使用jps命令查看进程统计
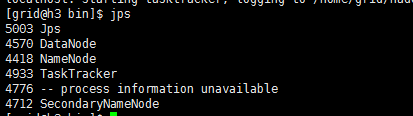
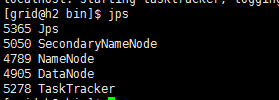
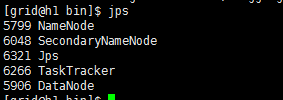
发现我们3台机器的jps都是一样每台都是master并没有slave的信息
what happened?##
配置masters和slaves
不知道同学们有没有发现,其实我们一路下来压根没有配置主从之类的配置,下面我们接着配置3台机器的masters和slaves,进入conf目录编辑3台机器的masters和slaves文件
-
masters这里我设置为h1机器
 masters
masters slaves设置为h2和h3机器

这时我们重新启动master来看效果,启动master机器后日志信息如下

从h1的日志中发现h2和h3都已起来,我们去分别查看3台机器的jps


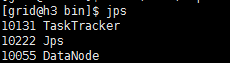
那么这里一共出现TaskTracker DataNode NameNode SecondaryNameNode JobTracker,出现这5个进程才算成功启动,1.x版本以上的好像已经没有JobTracker进程了
hadoop的集群安装就介绍到这里,如有不对的地方希望朋友们指出,及时改正