大数据 Spark :利用电影观看记录数据,进行电影推荐 | 原力计划


作者 | lomtom
责编 | 王晓曼
出品 | CSDN博客

准备
1、任务描述
在推荐领域有一个著名的开放测试集,下载链接是:http://grouplens.org/datasets/movielens/,该测试集包含三个文件,分别是ratings.dat、sers.dat、movies.dat,具体介绍可阅读:README.txt。
请编程实现:通过连接ratings.dat和movies.dat两个文件得到平均得分超过4.0的电影列表,采用的数据集是:ml-1m。

2、数据下载
下载(大小约为5.64M)后解压,会有movies.dat、ratings.dat、ReadMe、users.dat四个文件。
3、部分数据展示
movies.dat 部分数据:
MovieID::Title::Genres
1::Toy Story (1995)::Animation|Children's|Comedy
2::Jumanji (1995)::Adventure|Children's|Fantasy
3::Grumpier Old Men (1995)::Comedy|Romance
4::Waiting to Exhale (1995)::Comedy|Drama
5::Father of the Bride Part II (1995)::Comedy
6::Heat (1995)::Action|Crime|Thriller
7::Sabrina (1995)::Comedy|Romance
8::Tom and Huck (1995)::Adventure|Children's
9::Sudden Death (1995)::Action
10::GoldenEye (1995)::Action|Adventure|Thriller
11::American President, The (1995)::Comedy|Drama|Romance
12::Dracula: Dead and Loving It (1995)::Comedy|Horror
13::Balto (1995)::Animation|Children's
14::Nixon (1995)::Drama
15::Cutthroat Island (1995)::Action|Adventure|Romance
16::Casino (1995)::Drama|Thriller
17::Sense and Sensibility (1995)::Drama|Romance
18::Four Rooms (1995)::Thriller
19::Ace Ventura: When Nature Calls (1995)::Comedy
20::Money Train (1995)::Action
ratings.dat 部分数据:
UserID::MovieID::Rating::Timestamp
1::1193::5::978300760
1::661::3::978302109
1::914::3::978301968
1::3408::4::978300275
1::2355::5::978824291
1::1197::3::978302268
1::1287::5::978302039
1::2804::5::978300719
1::594::4::978302268
1::919::4::978301368
1::595::5::978824268
1::938::4::978301752
1::2398::4::978302281
1::2918::4::978302124
1::1035::5::978301753
1::2791::4::978302188
1::2687::3::978824268
1::2018::4::978301777
1::3105::5::978301713
1::2797::4::978302039

实操
将我们刚刚下载的数据存放到我们的项目中,项目目录结构如下,创建我们的主程序 movie.scala。
1、设置输入输出路径
这里使用数组保存我们的输入输出文件,方便后面的修改以及使用:
val files = Array("src/main/java/day_20200425/data/movies.dat",
"src/main/java/day_20200425/data/ratings.dat",
"src/main/java/day_20200425/output")
2、配置 spark
val conf = new SparkConf().setAppName("SparkJoin").setMaster("local")
val sc = new SparkContext(conf)
3、读取 Rating 文件
读取 Ratings.dat 文件,根据其内容格式我们将其用::分隔开两个部分,最后计算出电影评分。
// Read rating file
val textFile = sc.textFile(files(1))
//提取(movieid, rating)
val rating = textFile.map(line => {
val fileds = line.split("::")
(fileds(1).toInt, fileds(2).toDouble)
})
//get (movieid,ave_rating)
val movieScores = rating
.groupByKey()
.map(data => {
val avg = data._2.sum / data._2.size
(data._1, avg)
})
4、读取 movie 文件
Join 操作的结果 (ID,((ID,Rating),(ID,MovieName))),RDD的keyBy(func)实际上是为每个 RDD 元素生成一个增加了 ke y的
由于有时候数据的列数很多,不只是按一项作为 key 来排序,有时候需要对其中两项进行排序,Spark 的 RDD 提供了 keyBy 的方法。
val movies = sc.textFile(files(0))
val movieskey = movies.map(line => {
val fileds = line.split("::")
(fileds(0).toInt, fileds(1)) //(MovieID,MovieName)
}).keyBy(tup => tup._1)
5、保存结果
保存评分大于4的电影:
val result = movieScores
.keyBy(tup => tup._1)
.join(movieskey)
.filter(f => f._2._1._2 > 4.0)
.map(f => (f._1, f._2._1._2, f._2._2._2))
// .foreach(s =>println(s))
val file = new File(files(2))
if(file.exists()){
deleteDir(file)
}
result.saveAsTextFile(files(2))
6、结果
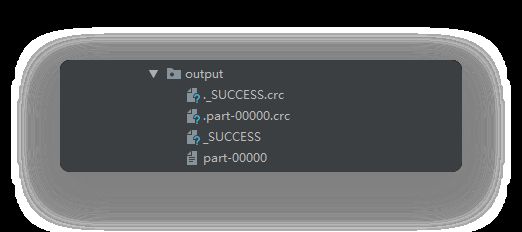
它会自动生成 output 文件夹,里面有四个文件,_SUCECCESS 代表成功的意思,里面没有任何内容,part-00000 就是我们的需要的数据。
部分结果:
(1084,4.096209912536443,Bonnie and Clyde (1967))
(3007,4.013559322033898,American Movie (1999))
(2493,4.142857142857143,Harmonists, The (1997))
(3517,4.5,Bells, The (1926))
(1,4.146846413095811,Toy Story (1995))
(1780,4.125,Ayn Rand: A Sense of Life (1997))
(2351,4.207207207207207,Nights of Cabiria (Le Notti di Cabiria) (1957))
(759,4.101694915254237,Maya Lin: A Strong Clear Vision (1994))
(1300,4.1454545454545455,My Life as a Dog (Mitt liv som hund) (1985))
(1947,4.057818659658344,West Side Story (1961))
(2819,4.040752351097178,Three Days of the Condor (1975))
(162,4.063136456211812,Crumb (1994))
(1228,4.1875923190546525,Raging Bull (1980))
(1132,4.259090909090909,Manon of the Spring (Manon des sources) (1986))
(306,4.227544910179641,Three Colors: Red (1994))
(2132,4.074074074074074,Who's Afraid of Virginia Woolf? (1966))
(720,4.426940639269406,Wallace & Gromit: The Best of Aardman Animation (1996))
(2917,4.031746031746032,Body Heat (1981))
(1066,4.1657142857142855,Shall We Dance? (1937))
(2972,4.015384615384615,Red Sorghum (Hong Gao Liang) (1987))

你可能会遇到的问题
1、问题一:结果输出目录已存在
描述:
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory file:/D:/Projects/JAVA/Scala/src/main/java/day_20200425/data/output already exist
分析:由于运行,然后输出文件夹已存在,则需要删除该目录
解决:方法一:手动删除;方法二:加入以下代码:
1、主程序中
val file = new File(files(2))
if(file.exists()){
deleteDir(file)
}
2、删除函数
/**
* https://www.cnblogs.com/honeybee/p/6831346.html
* 删除一个文件夹,及其子目录
*
* @param dir 目录
*/
def deleteDir(dir: File): Unit = {
val files = dir.listFiles()
files.foreach(f => {
if (f.isDirectory) {
deleteDir(f)
} else {
f.delete()
println("delete file " + f.getAbsolutePath)
}
})
dir.delete()
println("delete dir " + dir.getAbsolutePath)
}
2、问题二:缺少 hadoop 环境变量
描述:
ERROR util.Shell: Failed to locate the winutils binary in the hadoop binary path java.io.IOException
分析:
在 Windows 环境下没有配置 hadoop 环境的原因。
解决:
下载:https://github.com/amihalik/hadoop-common-2.6.0-bin,并且将其bin目录配置为系统的环境变量(path),然后再代码中加入以下代码,例如我的目录为E:\\Program\\hadoop\\hadoop-common-2.6.0-bin,那么则需要加入:
System.setProperty("hadoop.home.dir", "E:\\Program\\hadoop\\hadoop-common-2.6.0-bin")
版权声明:本文为CSDN博主「lomtom」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_41929184/article/details/105762156

推荐阅读
如何成为一名黑客?
一篇与众不同的 String、StringBuilder 和 StringBuffer 详解
干货 | 大白话彻底搞懂 HBase RowKey 详细设计
发送0.55 ETH花费近260万美元!这笔神秘交易引发大猜想
Python 爬取周杰伦《Mojito》MV 弹幕,这个评论亮了!
谷歌 Chrome 将弃用“黑名单”,“Master/Slave”主从模式也要换名?
真香,朕在看了!