【LeetCode】查找表相关问题汇总
查找表相关问题汇总
- 基础题目
- 349. 两个数组的交集
- 题目描述
- 方法1 两个set用来去重查找
- 350. 两个数组的交集 II
- 题目描述
- 方法1
- 方法2
- c++ Map的行为模式
- 其他思路 排序后双指针
- 242. 有效的字母异位词
- 题目描述
- 方法1 Map容器统计每个单词中字母出现的次数
- 方法2 使用数组记录每个单词出现次数 遍历数组
- 方法3 使用map简化方法2
- 202. 快乐数
- 题目描述
- 方法1 使用set容器查找是否重复
- 方法2 使用快慢指针破除循环
- 290. 单词规律
- 题目描述
- 分割函数1
- 分割函数2 遍历每一个字符
- 方法1 map容器字母单词对应 set解决重复问题
- 205. 同构字符串
- 题目描述
- 方法1 寻找每个字符第一次出现的位置
- 方法2 映射
- 451. 根据字符出现频率排序
- 题目描述
- 方法1 使用map和vector vector记录各个次数的字母
- 方法2 自己完成的
- 1.两数之和
- 题目描述
- 方法1
- 15. 三数之和
- 题目描述
- 方法1 遍历加内层双指针对撞
- 16. 最接近的三数之和
- 题目描述
- 方法1 排序后遍历 再用双指针
- 方法2 提前终止
- 18. 四数之和
- 题目描述
- 方法1 和三数之和一样 但是多了一层循环
- 方法2 关于++运算符leetcode提及版本
- 灵活键值选择
- 454. 四数相加 II
- 题目描述
- 方法1 每两个数组合并成一个map然后查找
- 方法2 只使用一个map第二个直接找
- 49. 字母异位词分组
- 题目描述
- 方法1 对每个字符串进行排序 之后查找 记录下标
- 方法2 减少内存空间 对子字符串排序
- 447. 回旋镖的数量
- 题目描述
- 方法1 对于中间的点进行遍历 map储存其他点和他的距离
- 方法2 优化统计个数的方法
- 149. 直线上最多的点数
- 题目描述
- 方法1 难点在于斜率计算时容易精度不够
- 滑动窗口+查找表
- 217. 存在重复元素
- 方法1 使用哈希表set容器
- 方法2 形成set 看大小是否变化 奇妙
- 方法3 排序后暴力搜索
- 219. 存在重复元素 II
- 题目描述
- 方法1 滑动窗口+容器
- 方法2 方法相似 但是是遍历 只用了一个i
- 方法3 储存重复元素最近的下标
- 220. 存在重复元素 III
- 题目描述
- 方法1 滑动窗口+容器 set的upper_bound函数的使用
基础题目
349. 两个数组的交集
题目描述

方法1 两个set用来去重查找
vector<int> intersection(vector<int>& nums1, vector<int>& nums2) {
set<int> set1;//储存一个集合中的元素
for (int i = 0;i < nums1.size();i++)
{
set1.insert(nums1[i]);
}
set<int> set2;//储存结果
for (int i = 0;i < nums2.size();i++)
{
if (set1.find(nums2[i]) != set1.end())
{
set2.insert(nums2[i]);
}
}
//for(set::iterator iter=set2.begin;iter!=set2.end();iter++)//使用迭代器遍历容器
vector<int> ret(set2.begin(),set2.end());
return ret;
}
350. 两个数组的交集 II
题目描述
方法1
vector<int> intersect1(vector<int>& nums1, vector<int>& nums2) {
map<int, int> map1;//第一个int为值 第二个为出现的次数
for (int i = 0;i < nums1.size();i++)
{
if (map1.find(nums1[i]) == map1.end())//不存在
{
map1.insert(make_pair(nums1[i], 1));
}
else
{
map1[nums1[i]]++;//次数增加
}
}
vector<int> ret;
for (int i = 0;i < nums2.size();i++)
{
if (map1.find(nums2[i]) != map1.end()&&map1[nums2[i]] > 0)//找到相同元素
{
ret.push_back(nums2[i]);
map1[nums2[i]]--;
if (map1[nums2[i]] == 0)//去掉元素后为空就减一
{
map1.erase(nums2[i]);
}
}
}
return ret;
}
方法2
vector<int> intersect2(vector<int>& nums1, vector<int>& nums2) {
map<int, int> map1;//第一个int为值 第二个为出现的次数
for (int i = 0;i < nums1.size();i++)
{
map1[nums1[i]]++;//初始化为0
}
vector<int> ret;
for (int i = 0;i < nums2.size();i++)//方法相似 进行化简
{
if (map1[nums2[i]]!=0)
{
ret.push_back(nums2[i]);
map1[nums2[i]]--;
}
}
return ret;
}
c++ Map的行为模式
void maptest()//测试map容器
{
map<int, int> testmap;
if (testmap.find(42) == testmap.end())
{
cout << "can not find 42 in map\n";//输出
}
else
{
cout << "42 is in the map\n";
}
testmap[42]++;
cout << testmap[42] << endl;//访问相当于插入 并且值为默认值 输出为1
testmap[42]--;
cout << testmap[42] << endl;//输出0
if (testmap.find(42) == testmap.end())
{
cout << "can not find 42 in map\n";
}
else
{
cout << "42 is in the map\n";//找到
}
testmap.erase(42);//移除才删除
if (testmap.find(42) == testmap.end())
{
cout << "can not find 42 in map\n";//不能找到
}
else
{
cout << "42 is in the map\n";
}
}
其他思路 排序后双指针
242. 有效的字母异位词
题目描述

方法1 Map容器统计每个单词中字母出现的次数
bool isAnagram(string s, string t) {
hash_map<int, int> map1;
for (int i = 0;i < s.size();i++)
{
map1[s[i]]++;
}
for (int i = 0;i < t.size();i++)
{
if (map1.find(t[i]) != map1.end())
{
map1[t[i]]--;
if (map1[t[i]] == 0)
{
map1.erase(t[i]);
}
}
else {
return false;
}
}
if (map1.empty())return true;
else return false;
}
方法2 使用数组记录每个单词出现次数 遍历数组
bool isAnagram1(string s, string t) {
int hashTable[26] = { 0 };
if (s.size() != t.size())return false;
for (int i = 0;i < s.size();i++)
{
hashTable[s[i]-97]++;//出现字母就加一
hashTable[t[i]-97]--;//出现字母就减一
}
for (int i = 0;i < 26;i++)
{
if (hashTable[i] != 0)return false;//是否全为0
}
return true;
}
方法3 使用map简化方法2
bool isAnagram2(string s, string t) {
unordered_map<char, int> map1;
if (s.size() != t.size())return false;
for (int i = 0;i < s.size();i++)
{
map1[s[i]]++;
map1[t[i]]--;
}
for (int i = 0;i < map1.size();i++)
{
if (map1[i] != 0)
{
return false;
}
}
return true;
}
202. 快乐数
题目描述
方法1 使用set容器查找是否重复
int cauHappy(int n)//计算对应的平方和
{
int ret=0;
int tmp = n;
int i = 0;
while (n > 0)
{
tmp = n % 10;
n = n / 10;
ret += tmp * tmp;
}
return ret;
}
bool isHappy2(int n) {
unordered_set<int> set1;
int ret = n;
while (1)
{
if (ret == 1)return true;//是1就是快乐数
if (set1.find(ret) != set1.end())//循环就不是
{
return false;
}
else
{
set1.insert(ret);
}
ret = cauHappy(ret);
}
}
方法2 使用快慢指针破除循环
bool isHappy(int n) {
//unordered_set set1;
int fast = n;
int slow = n;
while (1)
{//慢指针走一个 快指针走两个 相同了说明循环了
if (fast == 1||slow==1)return true;
else if (slow == fast)return false;
slow = cauHappy(slow);//慢指针
fast = cauHappy(fast);//快指针
fast = cauHappy(fast);
}
}
290. 单词规律
题目描述
分割函数1
vector<string> splitStr1(string s)
{
int index;
string substr;
vector<string> ret;
while (1)
{
index = s.find_first_of(' ');
if (index ==-1)
{
break;
}
substr = string(s.begin(), s.begin() + index);
ret.push_back(substr);
s = string(s.begin() + index+1, s.end());
}
ret.push_back(s);
return ret;
}
分割函数2 遍历每一个字符
vector<string> splitStr(string str)
{
vector<string> v;
int j = 0;
int begin = 0;
while (str[j] != '\0')//对字符串str的单词进行切分
{
if (str[j] != ' ')
j++;
else {
v.push_back(str.substr(begin, j - begin));//遇到空格就进行切分
begin = j + 1;
j++;
}
}
return v;
}
方法1 map容器字母单词对应 set解决重复问题
bool wordPattern(string pattern, string str) {
map<char, string> map1;//字母和单词
int j = 0;
set<string> set1;
vector<string> splitstr= splitStr(str);//分割字符串
if (pattern.size() != splitstr.size())return false;
for (int i = 0;i < pattern.size();i++)
{
if (map1.find(pattern[i]) == map1.end())//字母没有用过
{
if (set1.find(splitstr[i]) == set1.end())//单词没有出现过
{
map1[pattern[i]] = splitstr[i];//字母单词映射添加
set1.insert(splitstr[i]);//单词添加
}
else//单词出现过
return false;//解决了ab dog dog问题
}
else
{
if (map1[pattern[i]] != splitstr[i])
{
return false;
}
}
}
return true;
}
205. 同构字符串
题目描述
方法1 寻找每个字符第一次出现的位置
直接找映射比较麻烦 不能确定1对1的映射
bool isIsomorphic(string s, string t) {
int len = s.size();
for (int i = 0;i < s.size();i++)
{
if (s.find(s[i]) != t.find(t[i]))
{
return false;
}
}
return true;
}
方法2 映射
和上一题一样 就不写了
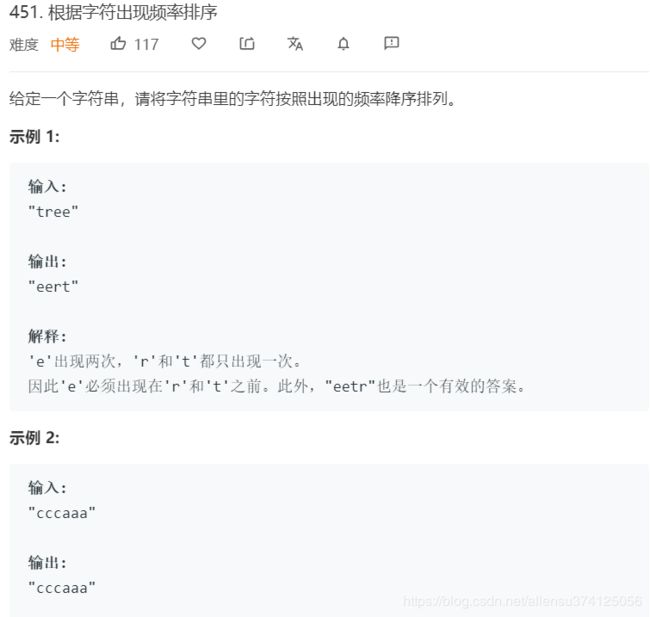
451. 根据字符出现频率排序
题目描述
方法1 使用map和vector vector记录各个次数的字母
string frequencySort1(string s) {
int n = s.size();
string ret(n, 'a');
unordered_map<char, int> m;
for (auto ch : s) {
++m[ch];//统计每个字母出现的次数
}
vector<vector<char>> box(n + 1);//分配内存
for (auto iter = m.begin();iter != m.end();++iter) {
for (int k = 0;k < iter->second;k++) {
box.at(iter->second).push_back(iter->first);//添加元素
}
}
int count = 0;
for (int i = box.size() - 1;i >= 0;--i) {
for (int j = 0;j < box.at(i).size();++j) {
ret[count] = box.at(i).at(j);
++count;
if (count == n) return ret;
}
}
return ret;
}
方法2 自己完成的
string frequencySort(string s) {
int n = s.size();
string ret;
unordered_map<char, int> map1;
for (int i = 0;i < s.size();i++)
{
map1[s[i]]++;
}
vector<vector<char>> vec(n+1);
for (unordered_map<char, int>::iterator iter = map1.begin();iter != map1.end();iter++)
{
int atimes = iter->second;
vec[atimes].push_back(iter->first);
}
for (int i = vec.size()-1;i > 0;i--)
{
for (int j = 0;j < vec[i].size();j++)
{
ret += string(i, vec[i][j]);
}
}
return ret;
}
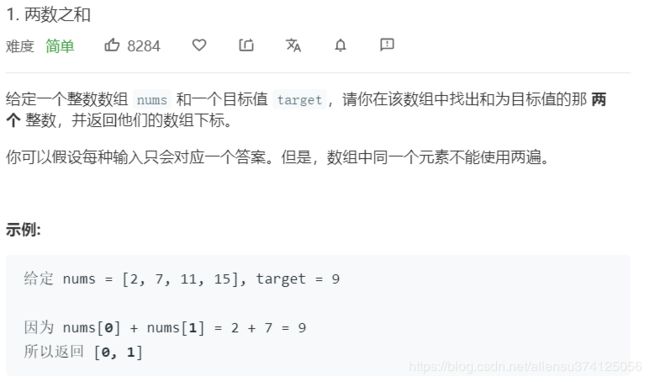
1.两数之和
题目描述
方法1
vector<int> twoSum(vector<int>& nums, int target) {
int size = nums.size();
vector<int> result;
result.push_back(0);
result.push_back(0);
unordered_map<int, int> map1;
for(int i=0;i<size;i++)
{
if (map1.find(target - nums[i]) != map1.end())//查找target-i
{
//result[0] = map1.find(target - nums[i])->second;
result[0] = map1[target - nums[i]];
result[1] = i;
return result;
}
else
{
//map1[nums[i]] = i;//直接赋值
map1.insert(make_pair(nums[i], i));
}
}
return result;
}
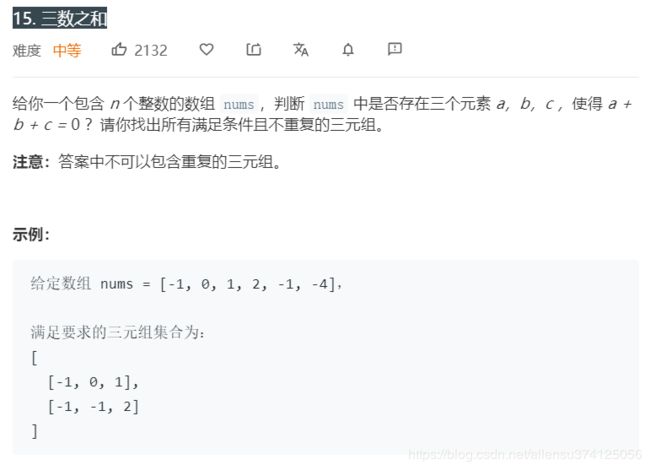
15. 三数之和
题目描述
方法1 遍历加内层双指针对撞
重点在于如何去除重复 采用先排序 然后找到目标结果后再对后面两个值去重
vector<vector<int>> threeSum(vector<int>& nums) {
vector<vector<int>> ret;
if(nums.size()<3)return ret;
int l;
int r;
sort(nums.begin(),nums.end());//先进行排序
/* vector newnums;
for(int i=0;i//======不可以提前去重=========
// newnums.push_back(nums[nums.size()-1]);
for(int i=0;i<nums.size()-2;i++)//第一层遍历
{
//if(i>=nums.size()-2)break;
//if(nums[i]==newnums[i+1])
//continue;
int tmptar=0-nums[i];
int tmpret[3];
tmpret[0]=nums[i];
r=nums.size()-1;
l=i+1;
while(l<r)//使用双指针对撞
{
if(nums[l]+nums[r]==tmptar)
{
tmpret[1]=nums[l];
tmpret[2]=nums[r];
ret.push_back(vector<int>(tmpret,tmpret+3));
while(l<nums.size()-1&&nums[l]==nums[l+1])//跳过重复
// while(nums[l]==nums[l+1]&&)
{l++;}
l++;
while(r>0&&nums[r]==nums[r-1])//跳过右边重复
{r--;}
r--;
}
else if(nums[l]+nums[r]<tmptar)
{
//while(nums[l]==nums[l+1])
// {
// l++;
//}
l++;
}
else{r--;}
}
while(i<nums.size()-1&&nums[i]==nums[i+1])
i++;
}
return ret;
}
16. 最接近的三数之和
题目描述

方法1 排序后遍历 再用双指针
int threeSumClosest(vector<int>& nums, int target) {
int ret = 0;
if (nums.size() < 3)
{
for (auto i : nums)
{
ret += i;
}
return ret;
}
ret=target-nums[0]-nums[1]-nums[2];
int l, r;
for (int i = 0;i < nums.size() - 2;i++)
{
l = i + 1;
r = nums.size() - 1;
int tmptar = target - nums[i];
while (l < r)
{
ret = abs(ret) < abs(tmptar - nums[l] - nums[r]) ? ret : tmptar - nums[l] - nums[r];//选择较小值
if (nums[l] + nums[r] < tmptar)
{
l++;
}
else //if (nums[l] + nums[r] > tmptar)
{
r--;
}
//else
//return target;
}
}
return target - ret;
}
方法2 提前终止
class Solution {
public:
int threeSumClosest(vector<int>& nums, int target) {
int ret = 0;
sort(nums.begin(),nums.end());
if (nums.size() < 3)
{
for (auto i : nums)
{
ret += i;
}
return ret;
}
ret=target-nums[0]-nums[1]-nums[2];
int l, r;
for (int i = 0;i < nums.size() - 2;i++)
{
l = i + 1;
r = nums.size() - 1;
int tmptar = target - nums[i];
while (l < r)
{
ret = abs(ret) < abs(tmptar - nums[l] - nums[r]) ? ret : tmptar - nums[l] - nums[r];
if (nums[l] + nums[r] < tmptar)
{
l++;
}
else if (nums[l] + nums[r] > tmptar)
{
r--;
}
else//找到了就提前终止 可以节省很多时间
return target;
}
}
return target - ret;
}
};
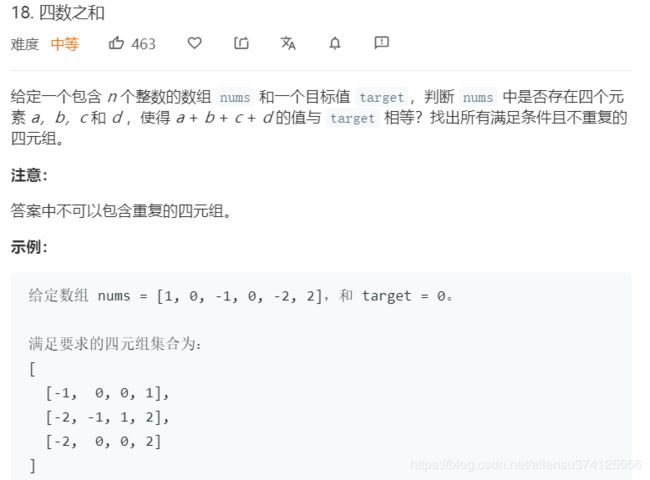
18. 四数之和
题目描述
方法1 和三数之和一样 但是多了一层循环
需要注意++运算符的问题
vector<vector<int>> fourSum(vector<int>& nums, int target) {
vector<vector<int>>ret;
int l, r;
if (nums.size() < 4)return ret;
sort(nums.begin(), nums.end());
for (int i = 0;i < nums.size() - 3; i++)
{
for (int j = i + 1;j < nums.size() - 2;j++)
{
int tmptar = target - nums[i] - nums[j];
l = j + 1;
r = nums.size() - 1;
while (l < r)
{
if (nums[l]+nums[r]==tmptar)
{
ret.push_back({ nums[i],nums[j],nums[l],nums[r] });
while (l < r && nums[l] == nums[l++]);//leetcode编译器不能这么写 会报错
while (l < r && nums[r] == nums[r--]);
}
else if (nums[l] + nums[r] <= tmptar)
{
l++;
}
else
{
r--;
}
}
while (j < nums.size() - 2 && nums[j] == nums[j + 1])
{
j++;
}
}
while (i < (nums.size() - 3) && nums[i+1] == nums[i])
{
i++;
}
}
return ret;
}
方法2 关于++运算符leetcode提及版本
vector<vector<int>> fourSum(vector<int>& nums, int target) {
vector<vector<int>>ret;
int l, r;
if (nums.size() < 4)return ret;
sort(nums.begin(), nums.end());
for (int i = 0;i < nums.size() - 3; i++)
{
for (int j = i + 1;j < nums.size() - 2;j++)
{
int tmptar = target - nums[i] - nums[j];
l = j + 1;
r = nums.size() - 1;
while (l < r)
{
if (nums[l]+nums[r]==tmptar)
{
ret.push_back({ nums[i],nums[j],nums[l],nums[r] });
while (l < r && nums[l] == nums[l+1])
{
l++;
}
l++;
while (l < r && nums[r] == nums[r-1])
{
r--;
}
r--; }
else if (nums[l] + nums[r] < tmptar)
{
l++;
}
else
{
r--;
}
}
while (j < nums.size() - 2 && nums[j] == nums[j + 1])
{
j++;
}
}
while (i < (nums.size() - 3) && nums[i+1] == nums[i])
{
i++;
}
}
return ret;
}
灵活键值选择
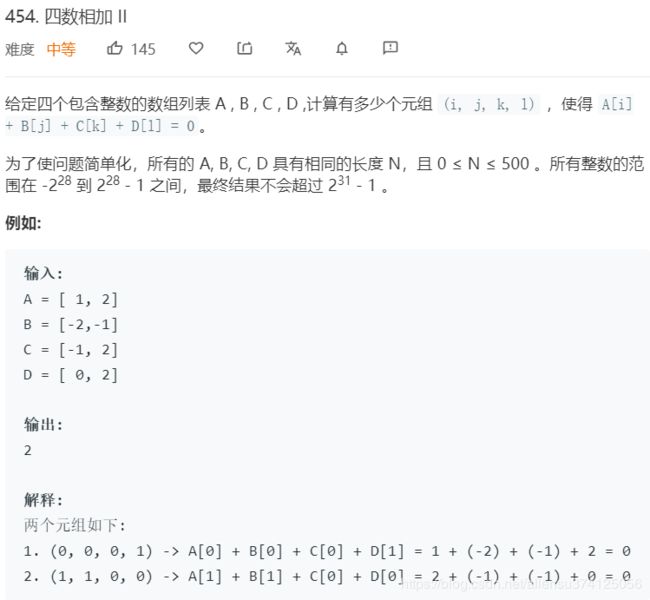
454. 四数相加 II
题目描述
方法1 每两个数组合并成一个map然后查找
int fourSumCount(vector<int>& A, vector<int>& B, vector<int>& C, vector<int>& D) {
unordered_map<int, int>map1;
unordered_map<int, int>map2;
int ret=0;
for (int i = 0;i < A.size();i++)
{
for (int j = 0;j < B.size();j++)
{
map1[A[i] + B[j]] += 1;
}
}
for (int i = 0;i < A.size();i++)
{
for (int j = 0;j < B.size();j++)
{
map2[C[i] + D[j]] += 1;
}
}
for (auto iter:map1)
{
int tmp = 0 - iter.first;
//unordered_map::iterator iter2=map2.find(tmp);
if (map2.find(tmp) != map2.end())
{
ret += (map2[tmp]*iter.second);//两个数量相乘
}
}
return ret;
}
方法2 只使用一个map第二个直接找
int fourSumCount1(vector<int>& A, vector<int>& B, vector<int>& C, vector<int>& D) {
unordered_map<int, int>map1;
//unordered_mapmap2;
int ret = 0;
for (int i = 0;i < A.size();i++)
{
for (int j = 0;j < B.size();j++)
{
map1[A[i] + B[j]] += 1;
}
}
for (int i = 0;i < A.size();i++)
{
for (int j = 0;j < B.size();j++)
{
int tmp = 0 - C[i]-D[j];
//unordered_map::iterator iter2 =
if (map1.find(tmp)!= map1.end())
{
ret += map1[tmp];
}
}
}
return ret;
}
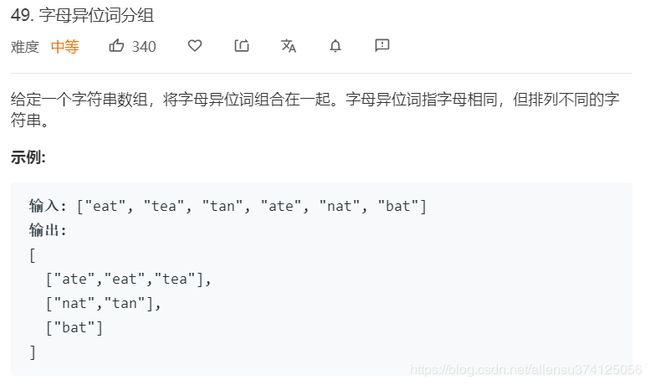
49. 字母异位词分组
题目描述
方法1 对每个字符串进行排序 之后查找 记录下标
vector<vector<string>> groupAnagrams1(vector<string>& strs) {
vector<vector<string>>ret;
vector<string> newstr = strs;
for (int i = 0;i < newstr.size();i++)
{
sort(newstr[i].begin(), newstr[i].end());//字符串复制后排序
}
unordered_multimap<int, int>map2;//每个字符串对于的原来数组的下标
unordered_map<string, int>map1;//每个子字符串对应的值是第几个不重复的字符串
//unordered_map
int num = 0;
for (int i = 0;i < newstr.size();i++)
{
if (map1.find(newstr[i]) != map1.end())//找到直接在map2添加
{
map2.insert(make_pair(map1[newstr[i]], i));
}
else//找不到维护两个map
{
int size = map1.size();
map1[newstr[i]] = size;
map2.insert(make_pair(map1[newstr[i]], i));
num++;
}
}
ret.resize(num);
for (auto i : map2)
{
ret[i.first].push_back(strs[i.second]);
}
return ret;
}
方法2 减少内存空间 对子字符串排序
vector<vector<string>> groupAnagrams(vector<string>& strs) {
vector<vector<string>>ret;
vector<string> newstr = strs;
string tmpstr;
//unordered_multimapmap2;
unordered_map<string, int>map1;
//unordered_map
int num = 0;
for (int i = 0;i < strs.size();i++)
{
string tmpstr = strs[i];//复制
sort(tmpstr.begin(), tmpstr.end());//排序
if (map1.find(tmpstr) != map1.end())
{
ret[map1[tmpstr]].push_back(strs[i]);
}
else
{
vector<string> tmpret(1,strs[i]);
ret.push_back(tmpret);
map1[tmpstr] = num++;//下面为另外一种写法
//map1.insert(make_pair(tmpstr, num));
//num++;
}
}
return ret;
}
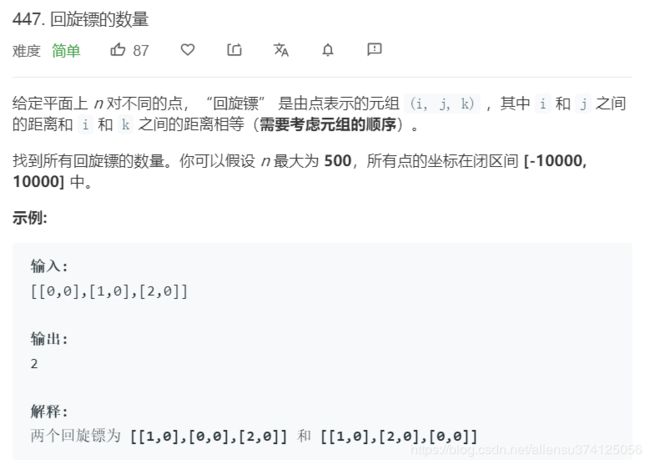
447. 回旋镖的数量
题目描述
方法1 对于中间的点进行遍历 map储存其他点和他的距离
int numberOfBoomerangs1(vector<vector<int>>& points) {
int ret = 0;
for (int i = 0;i < points.size();i++)
{
unordered_map<int, int> map1;
for (int j = 0;j < points.size();j++)
{
if (j == i)
{
continue;
}
int d = (points[i][0] - points[j][0]) * (points[i][0] - points[j][0]) + (points[i][1] - points[j][1]) * (points[i][1] - points[j][1]);//距离的平方
map1[d]++;//出现次数
}
for (auto i : map1)
{
if (i.second > 1)
{
ret += i.second * (i.second - 1);
}
}
}
return ret;
}
方法2 优化统计个数的方法
增加一个点 增加(n-1)*2种结果
int numberOfBoomerangs(vector<vector<int>>& points) {
int ret=0;
for (int i = 0;i < points.size();i++)
{
unordered_map<int, int> map1;
for (int j = 0;j < points.size();j++)
{
if (j == i)
{
continue;
}
int d = pow(points[i][0] - points[j][0],2) + pow(points[i][1] - points[j][1],2);
map1[d]++;
if (map1[d] > 1)
{
ret += (map1[d] - 1) * 2;
}
}
}
return ret;
}
149. 直线上最多的点数
题目描述
方法1 难点在于斜率计算时容易精度不够
对于每一个点 计算其它点到它的斜率 斜率相等说明在同一直线
//======================将斜率转化为string的方法=======
string Slope(int a, int b) {
string s = "";
char c;
int p;
stringstream ss; //使用字符流将整数部分直接转换成字符串。
p = a / b;
ss << p;
ss >> s;
s += '.';
for (int i = 0; i < 20; i++) //小数点后模拟除法过程,此时精度为20位。
{
a = a % b * 10;
c = (char)(a / b + 48);
s += c;
}
return s;
}
int maxPoints(vector<vector<int>>& points) {
int ret = 0;
if(points.size()==0)return 0 ;
for (int i = 0;i < points.size();i++)
{
int tmp=0;
unordered_map<string, int> map1;
int countsame=0;
for (int j = 0;j < points.size();j++)
{
if (i == j)continue;
if (points[i][0] == points[j][0] && points[i][1] == points[j][1])countsame++;
else if (points[i][0] != points[j][0])
{
string k = Slope((points[i][1] - points[j][1]) , (points[i][0] - points[j][0]));
map1[k]++;
}
else
{
tmp++;
}
}
for (auto iter : map1)
{
ret = max(iter.second+countsame, ret);
}
ret = max(ret, tmp+ countsame);
}
return ret+1;
}
滑动窗口+查找表
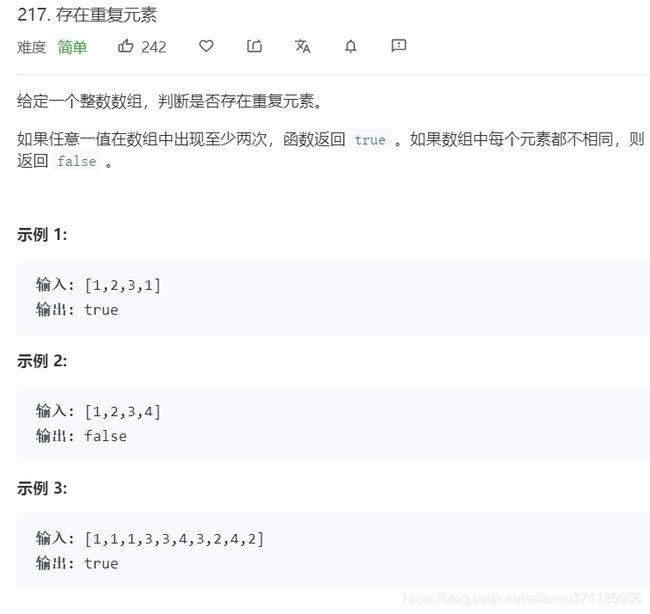
217. 存在重复元素
方法1 使用哈希表set容器
bool containsDuplicate2(vector<int>& nums) {
unordered_set<int> set1;
for (int i = 0;i < nums.size();i++)
{
if (set1.find(nums[i]) != set1.end())
{
return true;
}
set1.insert(nums[i]);
}
return false;
}
方法2 形成set 看大小是否变化 奇妙
bool containsDuplicate1(vector<int>& nums) {
unordered_set <int> st(nums.begin(), nums.end());
return nums.size() > st.size();//如果原数组的大小大于集合的大小,则说明存在重复元素
}
方法3 排序后暴力搜索
bool containsDuplicate(vector<int>& nums) {
sort(nums.begin(), nums.end());
for (int i = 0;i < nums.size() - 1;i++)
{
if (nums[i] == nums[i + 1])
{
return true;
}
}
return false;
}
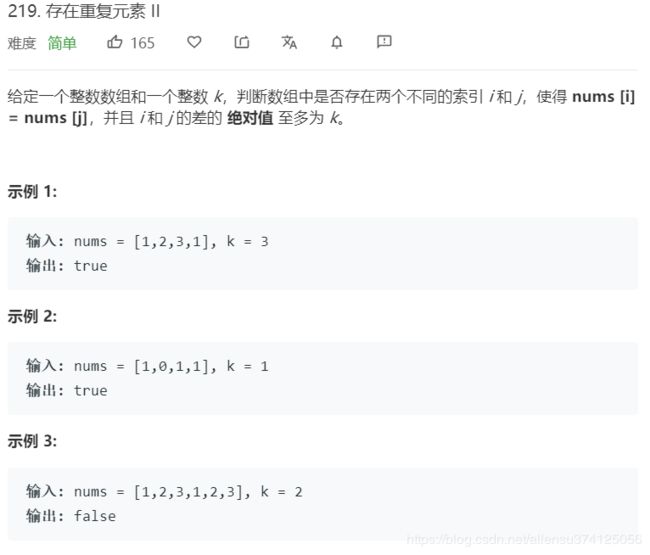
219. 存在重复元素 II
题目描述
方法1 滑动窗口+容器
bool containsNearbyDuplicate1(vector<int>& nums, int k) {
int l = 0;
int r = -1;
unordered_set<int> set1;
while (l < nums.size())
{
if (r - l >= k)//尺寸太大了
{
set1.erase(nums[l]);
l++;
}
else //普通操作
{
r++;
if(set1.find(nums[r])!=set1.end())
{
return true;
}
set1.insert(nums[r]);//找不到就插入
}
if (r == nums.size() - 1)break;
}
return false;
}
方法2 方法相似 但是是遍历 只用了一个i
bool containsNearbyDuplicate(vector<int>& nums, int k) {
unordered_set<int> set1;
for (int i = 0;i < nums.size();i++)
{
if (set1.find(nums[i]) != set1.end())
{
return true;
}
set1.insert(nums[i]);//插入该元素
if (set1.size() > k)
{
set1.erase(nums[i - k]);
}
}
return false;
}
方法3 储存重复元素最近的下标
这个没有自己实现 不是自己写的代码
bool containsNearbyDuplicate(vector<int>& nums, int k) {
unordered_map<int,int> M; //存储最近下标
for(int i=0;i<nums.size();i++){
unordered_map<int,int>::iterator iter=M.find(nums[i]);
if(iter==M.end())
M[nums[i]]=i;
else{
if(i-(iter->second)<=k)
return 1;
iter->second=i;
}
}
return 0;
}
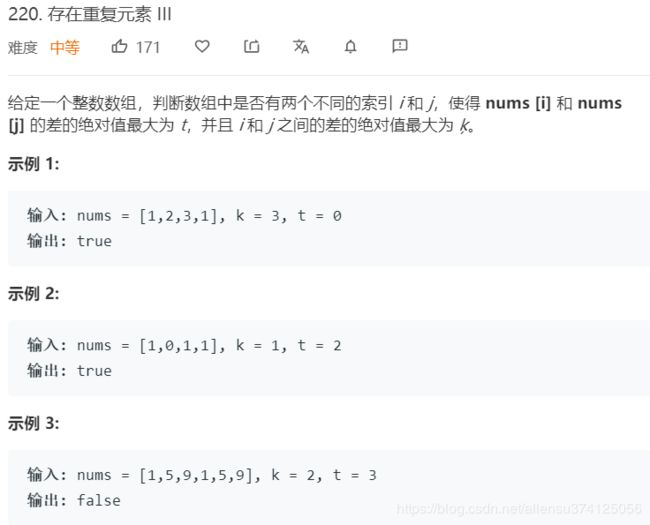
220. 存在重复元素 III
题目描述
方法1 滑动窗口+容器 set的upper_bound函数的使用
直接遍历会超时 计算改成longlong类型变量 防止数据溢出
bool containsNearbyAlmostDuplicate(vector<int>& nums, int k, int t) {
set<long long> map1;
long long t1 = t;
int l = 0;
int r = -1;
while (l < nums.size()&&r+1<nums.size())
{
r++;
if (map1.lower_bound((long long)nums[r] - t1) != map1.end() && *map1.lower_bound((long long)nums[r] - t) <= (long long)nums[r] + t)
{
return true;
}
map1.insert(nums[r]);
if (map1.size()>k)
{
map1.erase(nums[l++]);
}
//if (r == nums.size() - 1)break;
}
return false;
}