基于机器学习场景,如何搭建特征数据管理中台?

「免费学习 60+ 节公开课:投票页面,点击讲师头像」
作者 | 陈迪豪,第四范式资深架构师
编辑 | Jane
出品 | AI科技大本营(ID:rgznai100)
本文为CSDN即将推出的《新战场:决胜中台》专刊的第 5 篇文章。
一、机器学习场景与高性能特征管理中台
理想的机器学习场景是给到数据,训练模型后就能直接上线服务。然而真实的 AI 应用落地过程非常复杂,并不是有数据、懂算法就可以了。
首先建模具有一定门槛,建模科学技术人才除了要懂机器学习算法,还要知道熟悉建模业务场景,会使用 SQL、Python 做数据处理、特征拼接、支持时序特征;建模完成到上线,要保持在线与离线一致性,实现高性能硬实时预估服务;工程上涉及特征监控、读写分离、实时特征计算,这些情况在真实的 AI 应用场景中都要考虑到。
以我们合作的某银行事中反欺诈场景下的性能要求为例:首先实时性要求 P99 响应时间在 20 毫秒以内 ,比大家在业务里统计的平均延时要小很多,只有 1% 的时间可以在 20 毫秒以上;二是建模特征非常复杂,在线和离线的模型特征超过1000个;三是窗口特征需要能够在实时场景中生成;四是模型迭代周期短,需要定期上线更新。
在这种情况下,对企业特征管理中台有什么要求?
1、存储和计算必须是高性能的;
2、对离线特征的支持要与在线保持一致性;
3、训练得到的模型要支持端到端的预估;
4、支持单行和时序特征;
5、预估服务支持分布式高可用。
其中为什么强调特征的离线在线一致性?
用开源软件一般可以做到的是,离线积累一部分数据,然后用开源的深度学习框架训练模型,模型上线时把模型加载进来,但是机器学习除了模型预估还包括前面的处理过程,每个离线特征要支持在线预估都需要花几倍时间进行维护,以确保离线数据到在线预估的特征数据是一致的。
我们如何保证离线在线一致性呢?
通过一个统一的特征描述语言,用户离线环境中用这种统一特征描述语言进行表示与建模,在线环境中直接使用这个建模脚本来上线。
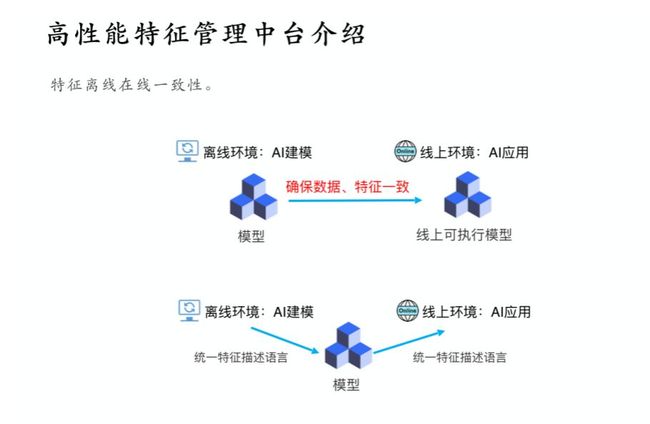
它的基本逻辑架构:
1、离线阶段是模型训练阶段,使用分布式存储存储原始数据;大数据处理引擎获得数据后进行划窗,窗口有不同的聚合计算逻辑,通过聚合计算得到一系列特征,这种特征可能是跨行和跨表的;最后,生成的数据处理经过特征签名可以直接给深度机器学习框架做训练。这是离线的阶段,将数据处理部分翻译成Spark,以分布式任务的方式运行。
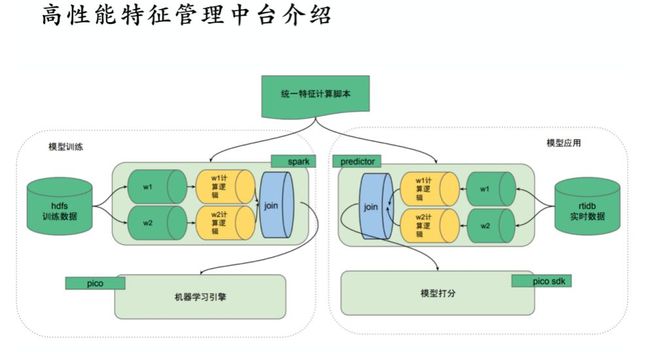
2、在线阶段肯定不能依赖 Spark 做实时预估,只可以使用流式接口实现近实时的计算;但因为我们有一个统一的特征描述语言,所以可以保证特征计算生成的代码与离线阶段是一样的,这样也就保证了离线在线保持了计算逻辑的一致性。
3、特征抽取的数据怎么来?离线阶段可以通过读分布式存储然后通过划窗来获取,AI特征管理中台中的存储组件包括一个实时特征时序数据库,通过这个时序数据库可以获取在线的窗口数据,然后实现一个高性能的模型评分服务。
二、特征管理中台的计算和存储核心剖析
这部分将主要介绍整体架构和计算、存储两大引擎。
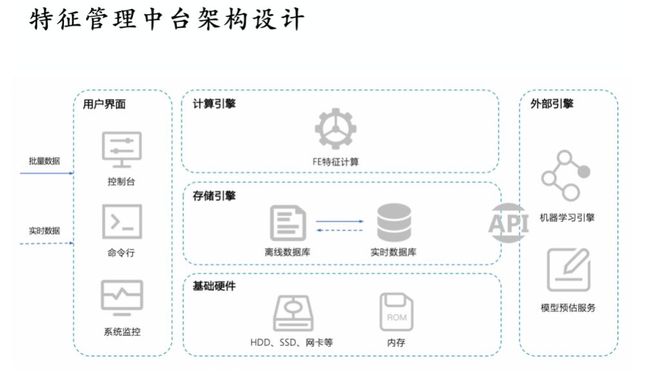
如上图所示,整体架构的左侧是用户接口,用户可以用控制台、命令行、SDK的方式访问核心组件。底层是硬件包括 HDD、SSD、网卡等;中间层是特征管理的两个重要组件,FE特征计算与存储引擎,在线有超高性能全内存时序数据库,得到的数据可以给自研的机器学习框架使用,或者给 TensorFlow 等开源的框架使用。
我们的特征描述语言是什么?其实是针对机器学习场景中定制的 DSL,有针对这种语法的编译器和解析器。语法可以参考下面的例子,第 1 行代码表示创建一个窗口,通过窗口的参数可以保证后续每一行的特征计算都在一个窗口数据内,在窗口数据内可以做很多复杂的计算。第 3 行是单行计算特征,很简单,像大家用过的 Spark 或 Python 都包含了很多特征计算,如内置支持日期处理;像条件表达式这类复杂的计算,大家可以用 SQL 或者 Spark。另外,我们自己跟标准窗口不一样的部分是根据科学家反馈设计跨表的窗口计算、拼表计算特征、特殊拼表特征也可以在 DSL 中描述。
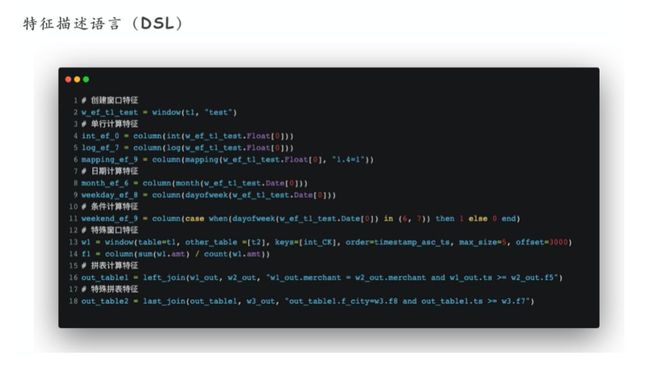
为什么要设计DSL?首先,机器学习产品中数据处理的逻辑是固定的,它跟 SQL 不一样。SQL是通用数据处理语言,很多方法是标准 SQL 中没有的,对条件表达式的处理或某种时间特征的计算,都是通过自定义来支持的。通过这种描述语言生成一个特征可以保证在线也能够使用 。
第二种接口是 SQL。SQL是目前最流行的数据处理语言,可以对全表做Partion分区,分区后可以排序或者做聚合计算,也可以做全表的数据处理,但标准的 SQL 是没办法上线的,有很多 支持SQL 的系统,如 MySQL、Spark、Hive 等,虽然支持了丰富的数据处理逻辑,但都是不可以直接上线的。
为什么SQL上线这么困难了?因为 SQL 的聚合计算可以是当前行,也可以是当前一段时间的窗口数据,实际上如果在 SQL 里对当前行以后的数据做聚合计算就会造成差数据穿越问题。用一个机器学习场景中的例子进行解释,你要计算当前交易是否属于欺诈交易,取得的时间是在这个时间以前某一天的时间和当前时间以后的某一个时间进行特征计算,但在实际上线时是没办法获取未来数据作为特征计算的,这种建模时就出现的穿越特征也会严重影响模型上线后的效果。
这种特征可以通过SQL的窗口函数来获得,我们称之为穿越特征,也就是在特征计算时是不应该引用当前行以后的数据,因为在真实线上预估中无法获取比当前行以后的数据。在我们的特征管理平台中,对于时间窗口的定义就限制了following参数必须是 Current Row,不计算当前行以后的特征。在这种限制的情况下,在线预估时就确保了窗口数据不会超过当前行,前面的数据可以通过时序特征数据库来做聚合,这种方式也保证优化后的 SQL 是符合机器学习在线预估的要求的,可以直接上线到实时预估服务中。
我们对 SQL 还有一些定制化拓展,例如对数据处理后的列可以做连续或者离散的特征签名计算,这是针对稠密和稀疏特征常用的签名方法。因为机器学习的输入数据不一定是大宽表,推荐系统中的输入一般都是非常稀疏离散的,这种稀疏数据结构在 SQL中是无法表示的,我们通过语法的拓展让它直接生成样本文件,这种样本文件本身支持稀疏和稠密的格式,可以直接对接开源的机器学习框架。
除了面向用户的特征描述语言,特征管理中台还支持 AutoML自动特征工程,用户只需输入原始的多个表数据,AutoML 程序可以对它进行自动分组与自动特征筛选,给出组合后的特征效果的评估,在一定的计算资源下进行迭代优化,最后生成SQL和特征描述语言配置,在线服务也可以直接使用导出的配置来上线。
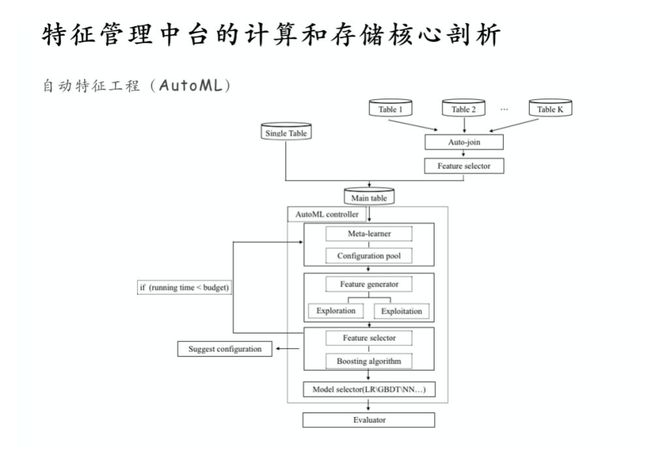
在计算引擎中还有非常多的功能优化点:1、支持多行时序特征,不只是针对单行计算,还可以对多行做聚合;2、支持强类型检查,支持 Map、List 复杂结构和 Lambda 表达式;3、实现 Last Join功能,实现超高性能的多表拼接功能;4、实现定制化跨表Window功能,实现高效的跨表划窗特征生成;什么是跨表Window?就是划窗的主表数据跟获取窗口数据的副表可以不是同一个表;5、支持 TensorFlow、LightGBM 和自研究机器学习机器等;6、预热编译以及内存编译器,使用Javac的编译优化;7、支持动态加载 UDF、UDAF 等用户自定义函数和功能。
计算性能也有很多优化:1、优化Spark的Window实现,支持 CodeGen 函数以及跨表窗口计算;2、同一进程内的内存编译优化,充分利用 Java 编译器优化生成高性能 byte code;3、支持特征级别的异常隔离,用户在同个窗口的多个特征计算,不会因为数据异常导致特征失败,也不会影响其他特征;4、对表达式也做了重写优化,常量表达式可以直接替换,对重复计算没有结果的表可以做提前剪枝,并且复用中间表达式的变量;5、在反欺诈机器学习场景中,相同特征下与 PySpark、SparkSQL相比提升了10倍性能;6、支持 RDMA 和 FPGA 硬件加速 ,对生成样本做高性能压缩 ,高性能版本比纯软件版本提升了3倍性能。
上面提到的都是计算核心的组件,再说说实现高性能、高并发、时序优化的存储核心——自研的全内存分布式时序数据库。为什么是时序数据库?因为我们在机器学习场景中很多特征都是基于时窗聚合而成的,窗口的特征就要求数据按时间序列进行排序和计算。
对于常见的机器学习场景,例如每笔交易都需要了解前序交易的情况;IoT的场景下,需要提前获得不同设备在不同时间段类的数据信息,所以面向 AI 的时序数据库在机器学习场景中非常有价值。
我们的时序数据库还支持多维度的查询和聚合;支持常见的按行数的数据淘汰策略和TTL。在特征管理中台中还有基于英特尔傲腾持久内存AEP的优化,这是一种全新的存储技术,介于内存和 SSD 之间的非易失性的存储,跟写到 SSD 一样数据不会丢失,同时可以把它当成内存来用。AEP存储的成本比内存低很多,但是会像内存一样优化,实现高性能,使用AEP优化以后性能可以提高 3 倍以上。基于这种新的存储介质可以实现根据热度的分层存储,对非常热的数据可以把表放在全内存里,对没那么热的数据可以放在AEP或者硬盘存储中。

三、特征管理中台在生产环境的应用实践
在一个真实场景 B2C Antifraud 业务中,交易表原始数据表有 2 张交易表和 7 张属性表。它的数据量非常大,总体特征超过 800 个,特征包括基于卡号维度做窗口聚合等数据;或者基于设备维度来定义窗口大小和时间段。
模型训练需要的基础特征包括交易特征、卡特征、客户特征、商户特征以及这几个特征的交叉组合 。时序特征包括每张卡和每个设备维度所统计过去交易的最大值、最小值、数量、是不是第一次交易等。最后用到的单表有 5000 万数据,生成的特征有 19 亿维,为什么这么高维?因为用户的设备ID、所在的城市都会离散化,为了避免冲突会用使用超高维稀疏值来存,生成的总特征就有 19 亿维,需要 3T 内存来计算。
在特征管理中台还包括不同类型的数据和特征脚本的管理,支持远程调试环境,支持单机 的Notebook 运行;支持全流程的一键上线,上线后预估接口是原始数据表输入,不需要在原始输入上再做数据的预处理和特征抽取处理。对此,我们还提供了 Python 客户端,用户可以写 Python来执行特征抽取逻辑,也可以使用支持的SQL语法,后面可以基于这个特征描述脚本来进行模型训练和应用上线了。

同时,我们也支持 TensorFlow 的分布式训练和内部机器学习框架的分布式计算,模型部署只需要一个简单的命令;部署成高可用的模型预估服务,可以看到,在线预估的输入数据都是原始的表数据,训练时输入表有多少列,这里输入多少列就可以;最后预估后返回特征抽取已经模型预估的结果。
《新战场:决胜中台》专刊已发布文章链接:
平安科技智能认知的“中台战事”
易观的大数据中台之路
知识图谱,下一代数据中台的核心技术
新战场路在何方——详解360金融数据中台之旅
(*本文为AI科技大本营原创文章,转载请微信联系1092722531)
◆
精彩推荐
◆
点击阅读原文,或扫描文首贴片二维码
所有CSDN 用户都可参与投票和抽奖活动
加入福利群,每周还有精选学习资料、技术图书等福利发送

推荐阅读
被追捧为“圣杯”的深度强化学习已走进死胡同
阿里达摩院2020趋势第一弹:感知智能的“天花板”和认知智能的“野望”
11年艺术学习“转投”数学,他出版首本TensorFlow中文教材,成为蚂蚁金服技术大军一员
召回→排序→重排:技术演进趋势的深度之旅,2020 必备!
如何写出让同事膜拜的漂亮代码?
AMD或推出64核128线程HEDT平台;地平线即将推出新一代自动计算平台;阿里达摩院公布2020十大科技趋势……
2019 最烂密码榜单出炉,教你设置神级密码!
GitHub Action 有风险?!
骗了马云 10 亿被骂 4 年后,院士王坚留下 4 条人生启示
万字长文回望2019:影响区块链行业发展的9大事件

你点的每个“在看”,我都认真当成了AI