深度学习人体姿态估计纵览
声明:本文原文来源于medium博客,经本人翻译首发于CSDN,仅供技术交流所用。
原文:https://medium.com/beyondminds/an-overview-of-human-pose-estimation-with-deep-learning-d49eb656739b
基于深度学习的人体姿态估计技术介绍
作者: Bharath Raj

人体姿态骨架以图形格式表示人的活动。本质上,它是一组坐标,将坐标组合起来就可以描述人的姿态。骨架中的每个坐标都称为关键点(或关节)。两个关键点之间的有效连接称为肢体。请注意,并非所有关键点组合起来都会产生有效的配对(肢体)。人体姿势骨架示例如下所示。左图为:人体姿态骨架的COCO关键点格式。右图为渲染后的人体姿态骨架。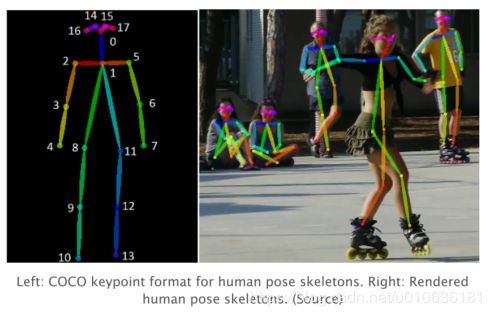
了解到一个人的姿态能够为几种真实的应用场景提供了便利之门,其中一些应用场景将在本博客最后讨论。经过多年的研究,这个领域已经引入了几种人体姿势估计的方法。其中,最早(也是最慢)的方法的典型特点是估计图像中仅有一个人的单个人活动的姿态。这些方法通常是首先识别人体的各个部位,接下来再在它们之间形成连接以创建姿态。
当然,这些方法在一些包含多个人的现实场景的图像中并不是特别有用。
多人姿态估计
由于图像中人的位置和人数未知,因此多人体姿态估计比单人体姿态估计更难。通常,我们可以使用以下两种方法之一解决上述问题:
- 最简单的方法是首先合并人物检测器,然后估计每个部位,最后计算每个人的姿态。这种方法称为自上而下的方法。如下图中的上半示意图所示。
- 另一种方法是检测图像中的所有部位(即每个人的部分),然后关联/分组属于不同人的部分。这种方法称为自下而上的方法。如下图中的下半示意图所示。
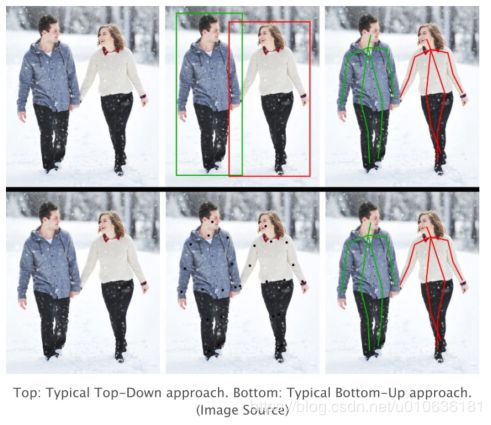
通常,自上向下的方法比自下而上的方法更容易实现,因为添加人检测器比添加关联/分组的算法简单得多。目前很难判断哪种方法总体上具有更好的性能,因为它真正归结为人物检测器和关联/分组算法中哪一种更好。
在这篇博客中,我们将重点介绍使用深度学习技术的多人人体姿势估计。在下一节中,我们将回顾一些流行的自上而下和自下而上的方法。
深度学习方法
1、 OpenPose
OpenPose是用于多人人体姿势估计的最流行的自下而上方法之一,相关代码已经开源在GitHub上,这种方法的确并表现出优良的性能。
与许多自下而上的方法一样,OpenPose首先检测属于图像中每个人的部位(关键点),然后将部位分配给不同的个体。下面显示的是OpenPose模型的体系结构。下图为OpenPose体系结构的流程图。
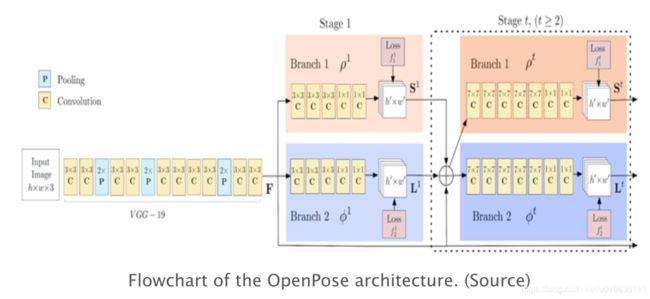
OpenPose网络首先使用前几个层(上面的流程图中的VGG-19)从图像中提取特征。然后将这些特征馈入两个平行的卷积层分支。第一个分支预测一组18个置信度的map,每个map代表人体姿势骨架的特定部分。第二个分支预测一组38个部位亲和力场(Part Affinity Fields,缩写为PAF),它表示部位之间的关联程度。下图为使用OpenPose进行人体姿势估计的步骤。

接下来的阶段用于细化每个分支的预测。使用部位置信度map,在部位对之间形成二分图(bipartite graphs,如上图所示)。利用PAF值,修剪二分图中较弱的连接。通过上述步骤,可以估计人体姿势骨架并将其分配给图像中的每个人。有关该算法的更全面说明,您可以参考他们的论文和博文。
2、DeepCut
DeepCut是一种自下而上的多人人体姿态估计方法。作者通过定义以下问题来完成任务:
1、生成一组身体部位的候选域 D 。该组候选域表示图像中每个人的身体部位的所有可能位置。从上面的身体部位候选集中选择身体部位的子集。
2、使用一个身体部位类(class)C标记每个选定的身体部位。身体部位类C代表部位的类型,例如“手臂”,“腿”,“躯干”等。
3、分配属于同一个人的身体部位类。
如下示意图所示。

通过将其建模为整数线性规划(ILP)问题来联合解决上述问题。它通过考虑(x, y, z)具有域的二元随机变量的三元组来建模,如下图所示。
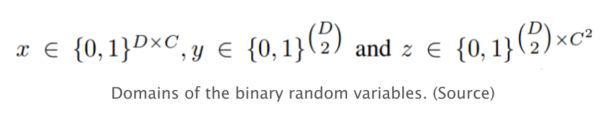
考虑某组身体部位域D中的两个候选域d和d’以及和某组类C中的两个类c与c’。身体部位候选域可以通过Faster RCNN或Dense CNN获得。现在,我们可以得到以下一组陈述:
- 如果x(d,c) = 1,那么它意味着身体部位候选域d属于类c。
- 如果y(d,d’) = 1 ,那么表示身体部分候选域d和d’属于同一个人。
- 定义z(d,d’,c,c’) = x(d,c) * x(d’,c’) * y(d,d’)。如果上述值为1,则表示身体部位候选域d属于类c,身体部位候选域d’属于类c’,最后身体部位候选域d,d’属于同一个人。
最后一个语句可用于分割属于不同人的姿势。显然,上述陈述可以用线性方程表示为函数(x,y,z)。通过这种方式,我们就可以建立整数线性规划(ILP)问题,并且可以估计多个人的姿势。对于精确的方程组和更详细的分析,您可以在这里查看他们的论文。
3、 RMPE(AlphaPose)
RMPE是一种流行的自上而下的姿态估计方法。作者认为,自上而下的方法通常取决于人物检测器的准确性,因为姿势估计是在人体所在区域中进行的。因此,由于人体定位和边界框重复预测引起的错误会导致姿势提取算法的结果次优。下图:重复预测(左)和低置信度边界框(右)的影响
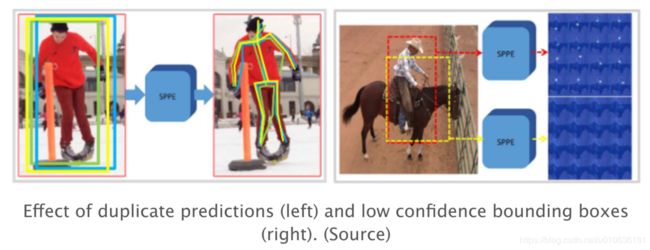
为了解决这个问题,作者提出使用对称空间变换器网络(SSTN)从不准确的边界框中提取高质量的单人区域。在该提取的区域中使用单人姿势估计器(SPPE)来估计该人的人体姿势骨架。空间去变换器网络(SDTN)用于将估计的人体姿势重新映射回原始图像坐标系。最后,利用非最大抑制(NMS)技术用于处理冗余姿势减少的问题。
此外,作者还引入了Pose Guided Proposals Generator来增强训练样本,从而更好地帮助训练SPPE和SSTN网络。RMPE的显着特征是该技术可以扩展到人检测算法和SPPE的任何组合。
4、Mask RCNN
Mask RCNN是一种用于执行语义和实例分割的流行架构。该模型并行地预测图像中各种物体的边界框位置以及在语义上对对象进行分割的掩模。Mask RCNN的基本架构可以很容易地扩展,用于人体姿势估计。下图为Mask RCNN架构的流程图。
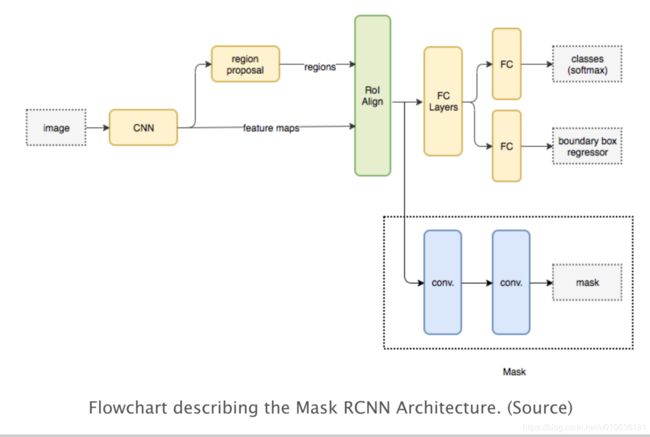
基本架构首先使用CNN从图像中提取特征图(feature maps )。区域生成网络(Region Proposal NetworkR,RPN)使用这些特征图来获取存在物体的候选边界框。候选边界框从CNN提取的特征图中选择区域。由于候选边界框可以具有各种尺寸,因此使用被称为RoIAlign的网络层来减小所提取特征的尺寸,使得它们都是均匀尺寸。接下来,将提取的特征传递到CNN的并行分支,以最终预测边界框和分割掩模。
让我们专注于执行分割的分支。假设我们图像中的对象属于K类中的一个。分割分支输出二进制掩码K 的大小为m x m,其中每个二进制掩码代表仅属于该类的所有对象。我们可以通过将每种类型的关键点建模为不同的类来提取属于图像中每个人的关键点,并将其视为分割问题。
同时,可以训练目标检测算法以识别人体的位置。通过组合人的位置信息以及他们的关键点集,我们获得图像中每个人的人体姿势骨架。
该方法几乎类似于自上而下的方法,但人检测阶段与部分检测阶段并行执行。换句话说,关键点检测阶段和人检测阶段彼此独立。
5、其他方法
多人人体姿势评估是一个多解决方法的广阔领域。为简洁起见,此处仅解释了几种方法。有关更详尽的方法列表,您可以查看以下链接:
- Awesome Human Pose Estimation
- Papers with Code
应用
Pose Estimation在很多领域都有应用,其中一些在下面列出。
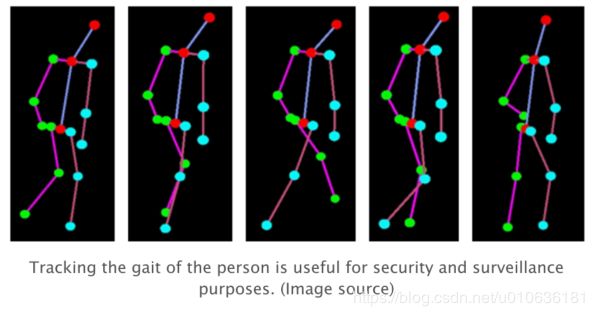
1、活动识别
在一段时间内跟踪人的姿势的变化也可以用于活动,姿势和步态识别。有几个用例,包括:
- 用于检测类似人是否跌倒或生病等应用
- 自主教授正确制定运动技巧和舞蹈活动等应用
- 理解全身手语等应用(例如:机场跑道信号,交通警察信号等)
- 增强安全性和监控等应用(识别异常过激行为)
2、运动捕捉和增强现实
人体姿态估计的一个有趣的应用是用于CGI应用。如果可以估计人的姿势,可以将图形,样式,花式增强,设备和艺术品叠加在人身上。通过跟踪这种人体姿势的变化,渲染的图形可以在人移动时“自然地适应”人。CGI渲染示例图如下图所示。

通过Animoji可以看到一个很好的可视化例子。尽管上面只跟踪了一张脸的结构,但这个想法可以推断出一个人的关键点。可以利用相同的概念来渲染可以模仿人的运动的增强现实(AR)元素。
3、 训练机器人
过去的机器人常常是需要手动编程,让机器人寻迹运动。而我们这里的应用是,让机器人遵循正在执行动作的人体姿态骨架进行运动。也就是说,人类教练只需要展示特定的动作就能够有效地教导机器人完成相同的动作,然后机器人可以计算如何移动其咬合架以执行相同的动作。相信大家在很多好莱坞电影都看到过。
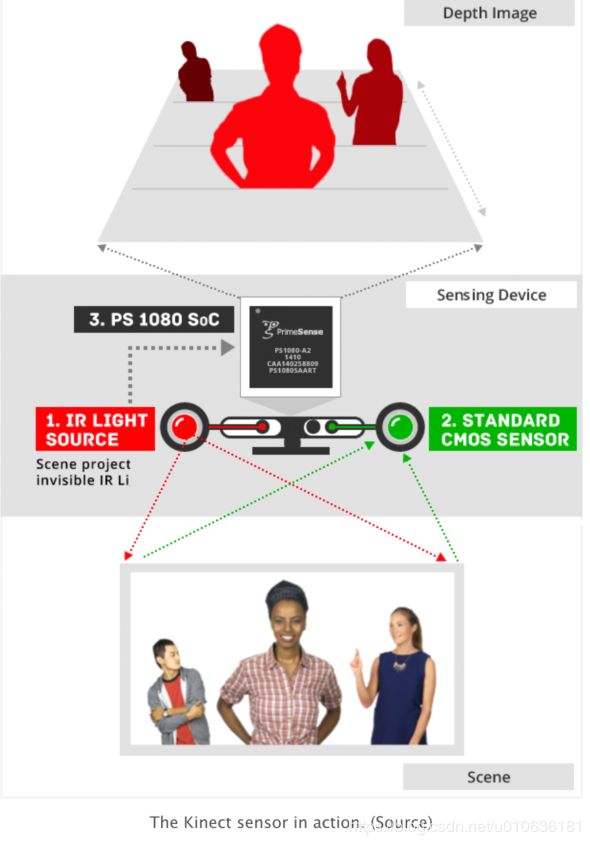
4、控制台的运动跟踪
姿势估计的有趣应用是用于跟踪人类对象的运动以进行交互式游戏。通常,Kinect使用3D姿势估计(使用IR传感器数据)来跟踪人类运动员的运动并使用它来渲染虚拟角色的动作。
结论
人体姿态估计领域的长足进步,使得我们能够更好地服务于其可能应用的无数场景。此外,对姿势跟踪等相关领域的研究可以大大提高其在多个领域的生产利用率。本博客中列出的概念并非详尽无遗,而是努力介绍这些算法的一些流行变体及其实际应用。
感谢 Yoni Osin。