Python 实现 2019 新型冠状病毒疫情地图可视化 (basemap + matplotlib)
文章目录
- 本人耗时2个月面试必备已出炉:
- [Python 全栈工程师 面试宝典 300 问深入解析 (2020 版) ](https://blog.csdn.net/u011318077/article/details/103770762)
- 加个人微信: AXiaShuBai 进Python小伙伴交流群
- 1. 环境安装 (地图包及绘图包)
- 2. 获取疫情数据(全球、中国各省及各地区数据)
- 3. 疫情数据分析
- 4. 每日疫情变化可视化
- 5. 中国疫情地图可视化
- 6. 世界疫情及地级市疫情地图可视化(拓展)
本人耗时2个月面试必备已出炉:
Python 全栈工程师 面试宝典 300 问深入解析 (2020 版)
加个人微信: AXiaShuBai 进Python小伙伴交流群

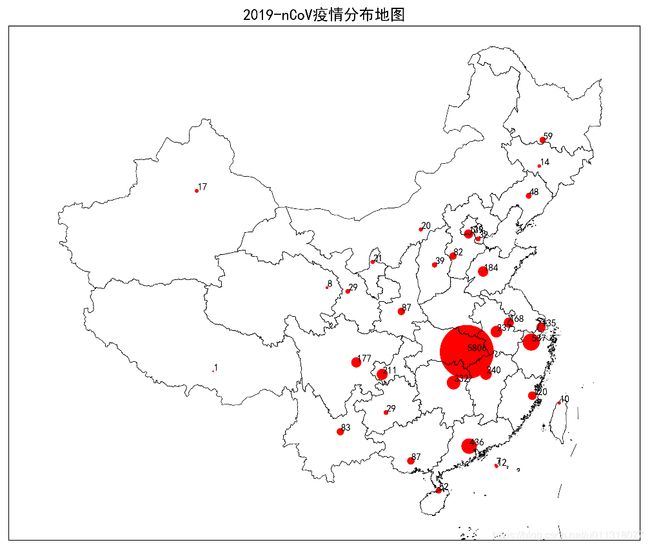
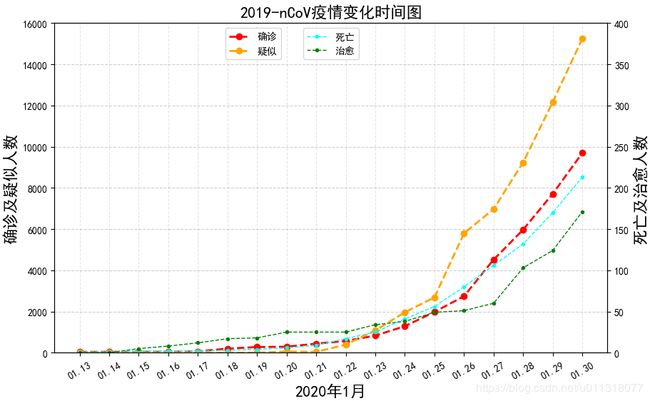
部分效果展示:
项目GitHub地址 记得star支持一下
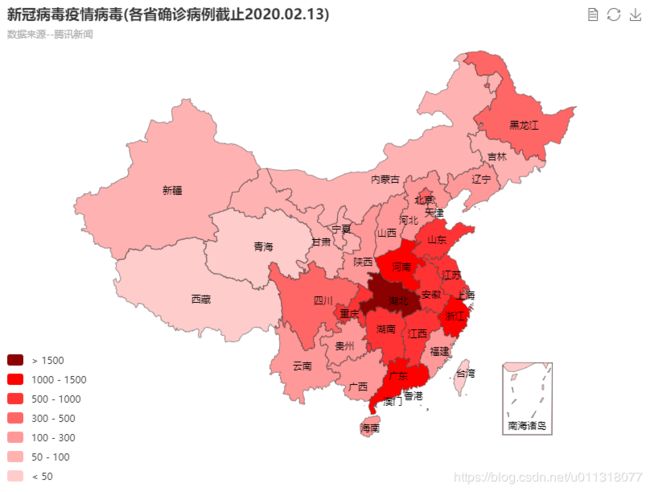
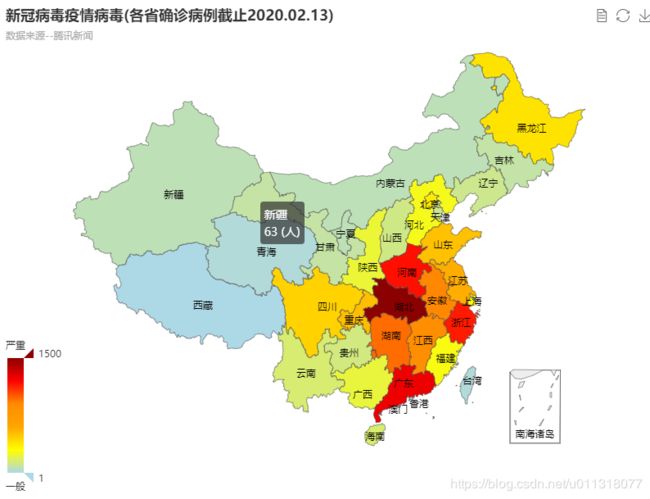
此外,我还使用ECharts作了地图可视化,ECharts的地图更加美观,可以直接交互,效果如下:
ECharts 实战:新冠病毒全国疫情地图可视化
1. 环境安装 (地图包及绘图包)
- 编程环境:Python3.7 + PyCharm2018
- 三方库 (按顺序依次安装)
- pyproj (basemap的依赖包,下载whl本地安装)
- geos (basemap的依赖包,直接pip安装)
- basemap (地图包,下载whl本地安装)
- matplotlib (画图包,直接pip安装)
- numpy、pandas、requests等常用包
- shapefile of china (地图数据,下载文件解压后放在项目文件夹)
下载地址:https://gadm.org/download_country_v3.html。
中国需下载 gadm36_CHN_shp、gadm36_HKG_shp、gadm36_MAC_shp、gadm36_TWN_shp
注意:三方库由于网络问题,直接使用pycharm安装失败或者进入项目虚拟环境下pip安装,速度非常慢,因此直接下载whl文件到本地,然后pip本地安装。
三方库下载地址:https://www.lfd.uci.edu/~gohlke/pythonlibs/#pyproj,将要下载的库直接替换网址#后面的内容即可,注意本地python的版本,需要下载对应的版本,cp37代表python3.7,amd64代表64位系统
2. 获取疫情数据(全球、中国各省及各地区数据)
- 数据来源:腾讯新闻 https://news.qq.com/zt2020/page/feiyan.htm
- 我们对该网址数据进行分析,采用Chrome浏览器,多次刷新先分析规律,然后使用Chrome的检查,然后右上角使用全局搜索(ctrl+shift+F),我们可以搜索全国确诊人数,地区名称,其它国家名称,发现数据都是在https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery34104671917134393502_1580374286688&_=1580374286689的请求网址中
- 在network查找该网址,分析响应数据,发现所有数据都是一个json格式响应中。callback后面应该是一个方法,后面的数字推测是时间戳,我们直接使用callback前面的网址去浏览器访问https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5,网页返回类容就是所有疫情的json数据。
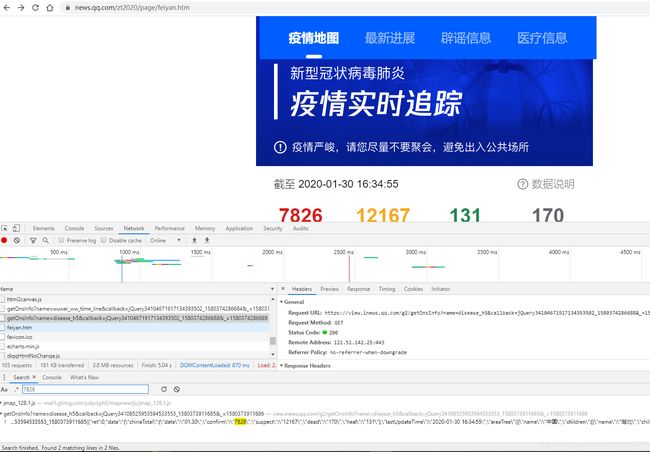
- 直接使用requests请求获取数据即可
- 代码
'''
Author: Felix
WeiXin: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2020/1/30 20:33
Desc:
'''
import requests
import json
class nCovData():
def __init__(self):
# 获取原始全国疫情数据的网址
self.start_url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5'
def get_html_text(self):
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:66.0) Gecko/20100101 Firefox/66.0'}
res = requests.get(self.start_url, headers=headers, timeout=30)
res.encoding = 'utf-8'
# 将获取到的json格式的字符串类型数据转换为python支持的字典类型数据
data = json.loads(res.text)
# 所有的疫情数据,包括:中国累积数据、各国数据(中国里面包含各省及地级市详细数据)、中国每日累积数据(1月13日开始)
all_data = json.loads(data['data'])
return all_data
if __name__ == '__main__':
ncovdata = nCovData()
ncovdata.get_html_text()
3. 疫情数据分析
- 全球各国数据提取
- 中国每日疫情数据提取
- 中国各省份数据提取
- 各地级市数据提取
- 中国每日数据代码,其它代码参考GitHub项目
import a_get_html
class ChinaData():
def __init__(self):
self.ncovdata = a_get_html.nCovData()
self.all_data = self.ncovdata.get_html_text()
def china_total_data(self):
# 累积数据汇总(实际该累积数据包含其它国家的数据),chinaTotal键对应的值就是累积数据
chinaTotal = self.all_data['chinaTotal']
# print(chinaTotal)
return chinaTotal
def china_everyday_data(self):
'''获取中国每日累积数据'''
chinaDayList = self.all_data['chinaDayList']
date_list = list()
everyday_confirm = list()
everyday_suspect = list()
everyday_dead = list()
everyday_heal = list()
for everyday in chinaDayList:
date_list.append(everyday['date'])
everyday_confirm.append(int(everyday['confirm']))
everyday_suspect.append(int(everyday['suspect']))
everyday_dead.append(int(everyday['dead']))
everyday_heal.append(int(everyday['heal']))
# print(date_list)
# print(everyday_confirm) # 中国累积确诊数据少于上面chinaTotal累积数据
return date_list, everyday_confirm, everyday_suspect, everyday_dead, everyday_heal
def main(self):
self.china_total_data()
self.china_everyday_data()
if __name__ == '__main__':
world_data= ChinaData()
world_data.main()
4. 每日疫情变化可视化
- 直接上代码
'''
Author: Felix
WeiXin: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2020/1/31 17:18
Desc:
'''
from china_data_analysis import ChinaData
import matplotlib.pyplot as plt
def daily_change():
# 获取每日疫情数据,日期,确诊,疑似,死亡,治愈
date_list, everyday_confirm, everyday_suspect, everyday_dead, everyday_heal = ChinaData().china_everyday_data()
# 显示中文和显示负号
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 绘制画布和子图对象
fig, ax1 = plt.subplots(figsize=(10, 6))
# 左Y轴绘制确诊和疑似病例曲线
ax1.plot(date_list, everyday_confirm, lw=2, ls='--', marker='o', color='red', label='确诊')
ax1.plot(date_list, everyday_suspect, lw=2, ls='--', marker='o', color='orange', label='疑似')
# 设置标题,XY轴标题,刻度
ax1.set_title("2019-nCoV疫情变化时间图", fontsize=16)
ax1.set_xlabel("2020年1月", fontsize=16)
ax1.set_xticklabels(date_list, rotation=30)
ax1.set_ylabel(r"确诊及疑似人数", fontsize=16)
ax1.set_ylim(0, 16000)
# 显示网格线和显示图例
plt.grid(which='major', axis='both', color='grey', linestyle='--', alpha=0.2)
plt.legend(loc='upper left', bbox_to_anchor=(0.3,1))
# 右Y轴绘制死亡和治愈病例曲线,共用ax1的X轴
ax2 = ax1.twinx()
ax2.plot(date_list, everyday_dead, lw=1, ls='--', marker='.', color='cyan', label='死亡')
ax2.plot(date_list, everyday_heal, lw=1, ls='--', marker='.', color='green', label='治愈')
# 设置标题刻度
ax2.set_ylabel(r"死亡及治愈人数", fontsize=16)
ax2.set_ylim(0, 400)
# 显示网格线和显示图例
plt.grid(which='major', axis='both', color='grey', linestyle='--', alpha=0.2)
plt.legend(loc='upper center')
# 展示图形
# plt.show()
# 保存图形为图片,第一个参数保存路径,第二个参数裁掉多余的空白部分
plt.savefig('2019-nCoV疫情变化时间图.png', bbox_inches='tight')
if __name__ == '__main__':
daily_change()
- 输出结果
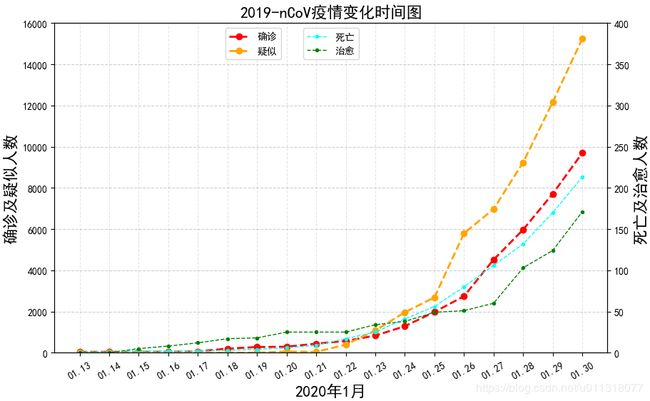
- 省份和地级市每日疫情变化的数据,项目中已经分析提取,可以修改上面直接作图, # 获取每日疫情数据,日期,确诊,疑似,死亡,治愈该行代码即可
5. 中国疫情地图可视化
'''
Author: Felix
WeiXin: AXiaShuBai
Email: [email protected]
Blog: https://blog.csdn.net/u011318077
Date: 2020/1/31 17:18
Desc:
'''
from province_data_analysis import ProvinceData
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.basemap import Basemap
def distribution_map():
# 显示中文和显示负号
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 获取省份名称列表及确认病例列表原始数据,按照人数多到少排列
province_name, province_total_confirm = ProvinceData().province_total_data()
province_confirm_dict = dict(zip(province_name, province_total_confirm))
# 设置图形大小
plt.figure(figsize=(10, 8), dpi=300)
# 设置中国的经纬度范围
lon_min, lon_max = 77, 142
lat_min, lat_max = 14, 51
# 绘制中国地图,设置经度纬度范围,使用兰伯特投影
map = Basemap(llcrnrlon=lon_min, llcrnrlat=lat_min, urcrnrlon=lon_max, urcrnrlat=lat_max, projection='lcc',
lat_1=33, lat_2=45, lon_0=100)
map.readshapefile('../china_shapfiles/china-shapefiles-simple-version/china', 'china', drawbounds=True)
map.readshapefile('../china_shapfiles/china-shapefiles-simple-version/china_nine_dotted_line', 'china_nine',
drawbounds=True)
# 读取各省份省委城市的经纬度数据
posi = pd.read_excel('中国省会城市经度纬度表.xlsx')
province_list = list(posi['province'])
lat_list = np.array(posi["lat"][0:34])
lon_list = np.array(posi["lon"][0:34])
confirm_origin = list(posi["confirm"][0:34])
province_dict = dict(zip(province_list,confirm_origin))
# 进行重新排序后的省份疫情表,省份排序与本地的经纬度表一致
new_province_confirm= data_merge(province_dict, province_confirm_dict)
confirm_list = np.array(list(new_province_confirm.values()))
size = (confirm_list/np.max(confirm_list))*3000
print(confirm_list)
# parallels = np.arange(0., 90, 10.)
# map.drawparallels(parallels, labels=[1, 0, 0, 0], fontsize=10) # 绘制纬线
# meridians = np.arange(80., 140., 10.)
# map.drawmeridians(meridians, labels=[0, 0, 0, 1], fontsize=10) # 绘制经线
x, y = map(lon_list, lat_list)
map.scatter(x, y, s=size, c='red')
# 设置数字标记
for i in range(0, 34):
plt.text(x[i] + 5000, y[i] + 5000, str(confirm_list[i]))
plt.title('2019-nCoV疫情分布地图', fontsize=16)
plt.savefig('2019-nCoV疫情分布地图.png')
plt.show()
# 由于原始疫情数据是按确诊人数排列的,与本地经纬度表排序不一致
# 我们将省份相同的名称对应的confirm(初始confirm都是0)值相加,得到重新排序后的确诊人数列表
def data_merge(A, B):
C = dict()
for key in A:
if B.get(key):
C[key] = A[key] + B[key]
else:
C[key] = A[key]
for key in B:
if not A.get(key):
C[key] = B[key]
return C
if __name__ == '__main__':
distribution_map()
- 输出效果:
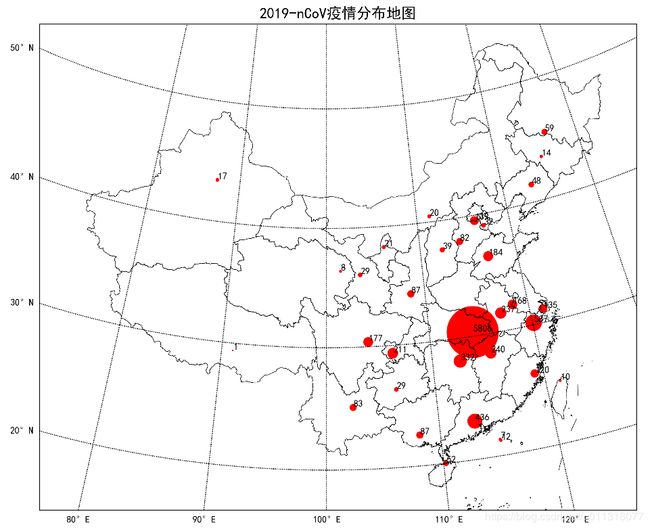
- 世界各国疫情数据已经分析提取,大家可以尝试做一个世界疫情地图
- 深入可以对每个地区进行按人数多少填充不同的颜色,网上已有类似案例
6. 世界疫情及地级市疫情地图可视化(拓展)
- 项目GitHub地址 记得star支持一下