深度学习笔记(二)——VGG
深度学习笔记(二)——VGG
文章目录
- 深度学习笔记(二)——VGG
- 闲聊
- 前言
- 网络结构
- 结构参数
- 结构图
- 模型解释
- 为什么使用3x3的卷积核
- 1X1卷积核
- 全连接转卷积
- 代码实现
- 引用相关的库
- 使用GPU
- 读入自定义数据集
- 构建VGG16模型
- 开始训练
- 关于文件结构
闲聊
本来打算跟着自己的进度走,这周拿出yoloV3的代码出来,但是emmmm,有时候身不由己…害。
这里自己学习复习一下VGG模型,然后好完成任务。
前言
VGG模型是2014年ILSVRC竞赛的第二名,但是VGG模型在多个迁移学习任务中的表现要优于googLeNet。而且,从图像中提取CNN特征,VGG模型是首选算法。它的缺点在于,参数量有140M之多,需要更大的存储空间。但是这个模型很有研究价值。(摘自百度百科)
特点:
- 小卷积核 ,将全部卷积核替换为3x3(极少数1x1),采用连续的几个3x3的卷积核代替AlexNet中的较大卷积核(11x11,7x7,5x5)
- 小池化核 ,相比AlexNet的3X3池化核,VGG全部是2X2的池化核
- 层数更深,特征图更宽 ,基于前两点外,由于卷积核专注于扩大通道数,池化专注于缩小宽和高,使得模型架构上更深更宽的同时,计算量的增加放缓
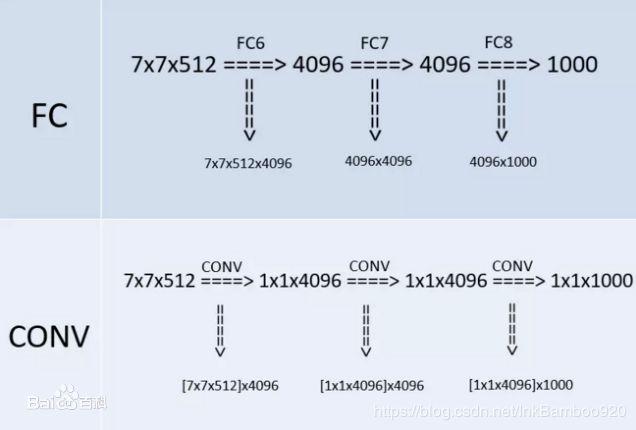
- 全连接转卷积 ,网络测试阶段将训练阶段的三个全连接替换为三个卷积,测试重用训练时的参数,使得测试得到的全卷积网络因为没有全连接的限制,因而可以接收任意宽或高为的输入。
网络结构
VGG的结构图:
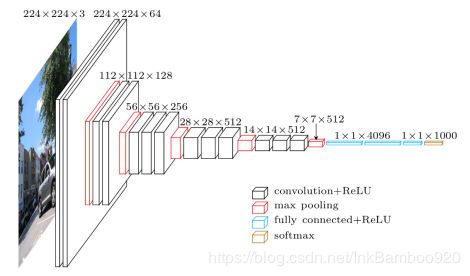
结构参数
| 名称 | 参数 |
|---|---|
| 输入图像 | 224x224 |
| 卷积核 | 3x3为主,少量1x1 |
| 池化层 | 2x2 |
| 激活函数 | ReLu |
结构图
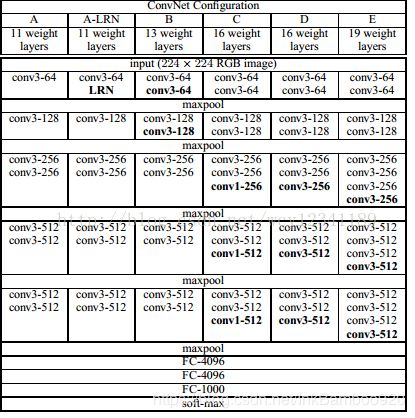
模型解释
为什么使用3x3的卷积核
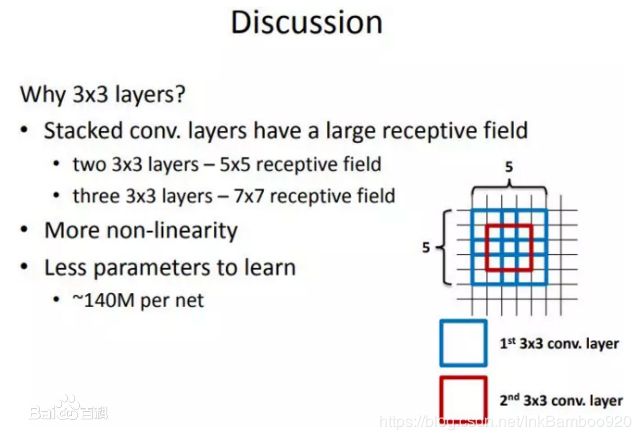
VGG的作者只用了两种卷积核:1x1和3x3。作者认为 两个3X3的卷积核堆叠获得的感受野大小,相当于一个5X5的卷积 ,而三个3X3的卷积核获取到的感受野相当于一个7X7的卷积
因为5X5卷积可以看做一个晓得全连接网络在5X5的区域滑动,而再用一个全连接层这个3X3的卷积输出,全连接层我们也可以看做一个3X3的卷积层,这样我们可以使用两个3X3的卷积核叠加替换一个5X5的卷积核 ,7X7的同理
效果如下图:
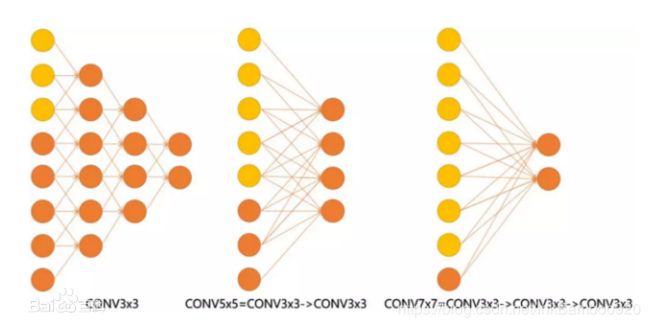
有些同学可能会问,用小卷积核叠加,计算量和参数量会发生怎样的一个变化,我们这里做一个计算测试,可以更直观的看到计算量的变化,这里以224x224x3的RGB图(设置pad=1,stride=4,output_channel=96)做卷积,卷积层的参数规模
| 卷积核 | 尺寸计算量 calc.sum | 参数量feature map |
|---|---|---|
| 3X3 | 1600万 | 309174 |
| 5X5 | 4500万 | 303750 |
| 7X7 | 8700万 | 298374 |
| 9X9 | 1.4亿 | 293046 |
| 11X11 | 2亿 | 287766 |
这里可以看到,在卷积核的尺寸变化时,对feature map的变化不是很大,不同尺寸的kernel大小下,参数量都是30万左右,变化不是很明显。而在计算量上,变化就很惊人了…
由此可以得到选择小卷积核的优势:
- 同样stride下,不同卷积核大小的feature map和卷积参数差别不大
- 小卷积核的计算量相对于大卷积核的计算量更小
- 多个小卷积核的堆叠比单一大卷积核带来了精度提升
1X1卷积核
VGG在最后的三个阶段都用到了1x1卷积核,选用1x1卷积核的最直接原因是在维度上继承全连接,然而作者首先认为1x1卷积可以增加决策函数(decision function,这里的决策函数就是softmax)的非线性能力,非线性是由激活函数ReLU决定的,本身1x1卷积则是线性映射,即将输入的feature map映射到同样维度的feature map。
全连接转卷积
作者在测试阶段把网络中原本的三个全连接层依次变为1个conv7x7,2个conv1x1,也就是三个卷积层。改变之后,整个网络由于没有了全连接层,网络中间的feature map不会固定,所以网络对任意大小的输入都可以处理
代码实现
引用相关的库
#######################
# 引入库 #
#######################
#coding=utf-8
from keras.applications import VGG16
from matplotlib import pyplot as plt
from PIL import Image
import os
from tqdm import tqdm_notebook
from random import shuffle
import shutil
import pandas as pd
import keras
from keras.preprocessing.image import ImageDataGenerator
from keras_tqdm import TQDMNotebookCallback
from keras.models import Sequential
from keras.layers import Dense,Activation,GlobalAveragePooling2D
from keras.layers import Dropout
from keras.layers import Flatten
from keras.constraints import maxnorm
from keras.optimizers import SGD
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
from keras.callbacks import Callback
from keras.preprocessing.image import ImageDataGenerator
from keras.layers.normalization import BatchNormalization
from keras.callbacks import TensorBoard
import numpy as np
import tensorflow as tf
使用GPU
#######################
# 使用GPU #
#######################
from keras import backend as K
tf.config.experimental.list_physical_devices('GPU')
import os
os.environ["CUDA_DEVICE_ORDER"]="PCI_BUS_ID"
os.environ["CUDA_VISIBLE_DEVICES"]="0"
读入自定义数据集
#######################
# 读入数据 #
#######################
#--------读取自定义数据----------#
train_dir="D:/work/python/vgg-keras/data/train"
val_dir="D:/work/python/vgg-keras/data/train"
test_dir="D:/work/python/vgg-keras/data/test"
#--------进行数据增强---------#
train_pic_gen=ImageDataGenerator(rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
rescale=1./255,shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
cval=0,
channel_shift_range=0,
vertical_flip=False)
test_pic_gen=ImageDataGenerator(rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
rescale=1./255,shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
cval=0,
channel_shift_range=0,
vertical_flip=False)
val_pic_gen=ImageDataGenerator(rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
rescale=1./255,shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest',
cval=0,
channel_shift_range=0,
vertical_flip=False)
#---------整理准备放入训练------------#
train_flow=train_pic_gen.flow_from_directory(train_dir,(224,224),batch_size=8,class_mode='categorical')
val_flow=val_pic_gen.flow_from_directory(val_dir,(224,224),batch_size=8,class_mode='categorical')
test_flow=test_pic_gen.flow_from_directory(test_dir,(224,224),batch_size=8,class_mode='categorical')
print(train_flow.class_indices)
构建VGG16模型
##########################
# 定义VGG16模型 #
##########################
model = Sequential()
model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=(224,224,3),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(3,activation='softmax'))
开始训练
#######################
# 开始训练 #
#######################
model.summary()
model.compile(optimizer=SGD(lr=0.0001, momentum=0.9,decay=0.0005),loss='categorical_crossentropy',metrics=['acc'])
#import catvsdogs.morph as mp
history=model.fit_generator(
train_flow,
steps_per_epoch=30,
epochs=1000,
validation_data=val_flow,
validation_steps=12,
callbacks=[TensorBoard(log_dir='D:/work/python/vgg-keras/log')])
model.save('D:/work/python/vgg-keras/model/vgg16_use.h5')
test_loss, test_acc = model.evaluate_generator(test_flow, 96)
print('test acc:', test_acc)
关于文件结构
在train和test文件里,每个文件夹直接对应的是一个分类,这里我是一个昆虫分类的数据集,每一个子文件夹对应一个分类,可以根据自己需要进行更改
