一起做个简单的数据库(八):B树叶子节点的格式

本系列文章一共13篇,本文为第8篇,请关注公众号,后续文章会陆续发布。
系列文章列表:
《手把手教你从零开始实现一个数据库系统》
《世上最简单的SQL编译器和虚拟机》
《一个在内存中仅能做追加操作的单表数据库》
《第一次测试 (含bug处理)》
《持久化存储》
《The Cursor Abstraction》
《B树介绍》
我们将表格的格式从未排序的行组转变成了B树。这个变化非常大,需要很多篇文章才能完成。在本篇的末尾,我们将定义叶子节点的布局,并且实现在单节点树中插入键值对。但首先让我们回顾一下为什么将数据结构改为树。
表格格式的替代
以目前的格式,每页只存储行(不包括元数据)所以空间很充足。插入操作的执行会很快,因为我们只在行末追加。然而,要找到特定行需要扫描整个表。当我们删除某行的时候,我们需要把该行后面的所有行向前移动来填补该行的空缺。
如果我们用数组来存储表格,把行按ID来排序,我们可以用二进制查询来查找特定ID。然而,插入操作会很慢,因为要挪动很多行来给新插入的数据腾地儿。
如果我们用树结构,每个节点都包含可变的行数,我们需要在每个节点中存储一些信息来追踪每个节点存了多少行。另外所有不存储任何行的内部节点也存储开销。在大数据库文件操作的时候我们插入,删除,查找更快速。
节点的头部格式
叶子节点和内部节点的布局是不一样的,让我们用enum来跟踪节点类型:
+typedef enum { NODE_INTERNAL, NODE_LEAF } NodeType;
每个节点将对应一个页面。内部节点将通过存储子节点的页码来找到其子代。B树向pager询问特定的页码,然后指向该页缓存的指针。页面按页面编号排序,一个一个的存储在数据库文件中。
在页面起点,节点会在头信息里存储元数据。每个节点都会存储自己的节点类型,不论自己是不是根节点(为了能找到同级节点),也同时存储指向父节点的指针信息。下面为每个头字段的大小和偏移量定义常量:
+/*
+ * Common Node Header Layout
+ */
+const uint32_t NODE_TYPE_SIZE = sizeof(uint8_t);
+const uint32_t NODE_TYPE_OFFSET = 0;
+const uint32_t IS_ROOT_SIZE = sizeof(uint8_t);
+const uint32_t IS_ROOT_OFFSET = NODE_TYPE_SIZE;
+const uint32_t PARENT_POINTER_SIZE = sizeof(uint32_t);
+const uint32_t PARENT_POINTER_OFFSET = IS_ROOT_OFFSET + IS_ROOT_SIZE;
+const uint8_t COMMON_NODE_HEADER_SIZE =
+ NODE_TYPE_SIZE + IS_ROOT_SIZE + PARENT_POINTER_SIZE;
叶子节点的格式
除了这些公共头字段之外,叶节点还需要存储它们包含多少个“单元”。单元格等同于键/值对。
+/*
+ * Leaf Node Header Layout
+ */
+const uint32_t LEAF_NODE_NUM_CELLS_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_NUM_CELLS_OFFSET = COMMON_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_HEADER_SIZE =
+ COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE;
叶子节点的主体是单元格的阵列。每个单元格都是一个键,后跟一个值(序列化的行)。
+/*
+ * Leaf Node Body Layout
+ */
+const uint32_t LEAF_NODE_KEY_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_KEY_OFFSET = 0;
+const uint32_t LEAF_NODE_VALUE_SIZE = ROW_SIZE;
+const uint32_t LEAF_NODE_VALUE_OFFSET =
+ LEAF_NODE_KEY_OFFSET + LEAF_NODE_KEY_SIZE;
+const uint32_t LEAF_NODE_CELL_SIZE = LEAF_NODE_KEY_SIZE + LEAF_NODE_VALUE_SIZE;
+const uint32_t LEAF_NODE_SPACE_FOR_CELLS = PAGE_SIZE - LEAF_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_MAX_CELLS =
+ LEAF_NODE_SPACE_FOR_CELLS / LEAF_NODE_CELL_SIZE;
基于这些定义的常量,下面就是叶子节点的布局:

在头部信息中使用布尔值使用整个字节的空间有点低效,但如果用代码来访问这些值会更加容易。
另请注意,最后还有一些浪费的空间。我们在头部的后边存储了尽可能多的单元格,但是剩余的空间无法容纳整个单元格。我们将其保留为空以避免在节点之间拆分单元格。
访问叶子节点字段
访问键值和元数据的代码都使用我们刚刚定义的常量的指针算法。
+uint32_t* leaf_node_num_cells(void* node) {
+ return node + LEAF_NODE_NUM_CELLS_OFFSET;
+}
+
+void* leaf_node_cell(void* node, uint32_t cell_num) {
+ return node + LEAF_NODE_HEADER_SIZE + cell_num * LEAF_NODE_CELL_SIZE;
+}
+
+uint32_t* leaf_node_key(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num);
+}
+
+void* leaf_node_value(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num) + LEAF_NODE_KEY_SIZE;
+}
+
+void initialize_leaf_node(void* node) { *leaf_node_num_cells(node) = 0; }
+
这些方法返回指向相关值的指针,因此它们既可以用作获取器,也可以用作设置器。
对Pager和表对象的更改
节点会占用整个页,不论其是否占满。这意味着我们的Pager不需要支持页面的部分读/写。
-void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+void pager_flush(Pager* pager, uint32_t page_num) {
if (pager->pages[page_num] == NULL) {
printf("Tried to flush null page\n");
exit(EXIT_FAILURE);
@@ -242,7 +337,7 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
}
ssize_t bytes_written =
- write(pager->file_descriptor, pager->pages[page_num], size);
+ write(pager->file_descriptor, pager->pages[page_num], PAGE_SIZE);
if (bytes_written == -1) {
printf("Error writing: %d\n", errno);
const uint32_t PAGE_SIZE = 4096;
const uint32_t TABLE_MAX_PAGES = 100;
-const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
-const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
typedef struct {
int file_descriptor;
uint32_t file_length;
+ uint32_t num_pages;
void* pages[TABLE_MAX_PAGES];
} Pager;
typedef struct {
Pager* pager;
- uint32_t num_rows;
+ uint32_t root_page_num;
} Table;
现在在数据库存储页数比行数更有意义了。页数应与Pager对象关联而不是与表相关联,因为它是被数据库所使用的页数,而不是表。B树由其根节点页号标识,因此表对象需要对其进行跟踪。
const uint32_t PAGE_SIZE = 4096;
const uint32_t TABLE_MAX_PAGES = 100;
-const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
-const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
typedef struct {
int file_descriptor;
uint32_t file_length;
+ uint32_t num_pages;
void* pages[TABLE_MAX_PAGES];
} Pager;
typedef struct {
Pager* pager;
- uint32_t num_rows;
+ uint32_t root_page_num;
} Table;
@@ -127,6 +200,10 @@ void* get_page(Pager* pager, uint32_t page_num) {
}
pager->pages[page_num] = page;
+
+ if (page_num >= pager->num_pages) {
+ pager->num_pages = page_num + 1;
+ }
}
return pager->pages[page_num];
@@ -184,6 +269,12 @@ Pager* pager_open(const char* filename) {
Pager* pager = malloc(sizeof(Pager));
pager->file_descriptor = fd;
pager->file_length = file_length;
+ pager->num_pages = (file_length / PAGE_SIZE);
+
+ if (file_length % PAGE_SIZE != 0) {
+ printf("Db file is not a whole number of pages. Corrupt file.\n");
+ exit(EXIT_FAILURE);
+ }
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
pager->pages[i] = NULL;
对Cursor对象的更改
Cursor表示表中的位置。当我们的表是一个简单的由行组成的数组时,我们通过行号访问行。现在已经是树结构了,我们通过节点的页码以及该节点内的单元格编号来确定位置。
typedef struct {
Table* table;
- uint32_t row_num;
+ uint32_t page_num;
+ uint32_t cell_num;
bool end_of_table; // Indicates a position one past the last element
} Cursor;
Cursor* table_start(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = 0;
- cursor->end_of_table = (table->num_rows == 0);
+ cursor->page_num = table->root_page_num;
+ cursor->cell_num = 0;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->end_of_table = (num_cells == 0);
return cursor;
}
Cursor* table_end(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = table->num_rows;
+ cursor->page_num = table->root_page_num;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->cell_num = num_cells;
cursor->end_of_table = true;
return cursor;
}
void* cursor_value(Cursor* cursor) {
- uint32_t row_num = cursor->row_num;
- uint32_t page_num = row_num / ROWS_PER_PAGE;
+ uint32_t page_num = cursor->page_num;
void* page = get_page(cursor->table->pager, page_num);
- uint32_t row_offset = row_num % ROWS_PER_PAGE;
- uint32_t byte_offset = row_offset * ROW_SIZE;
- return page + byte_offset;
+ return leaf_node_value(page, cursor->cell_num);
}
void cursor_advance(Cursor* cursor) {
- cursor->row_num += 1;
- if (cursor->row_num >= cursor->table->num_rows) {
+ uint32_t page_num = cursor->page_num;
+ void* node = get_page(cursor->table->pager, page_num);
+
+ cursor->cell_num += 1;
+ if (cursor->cell_num >= (*leaf_node_num_cells(node))) {
cursor->end_of_table = true;
}
}
在叶子节点中做插入
在本篇中,我们仅实现足以获得单节点树的方法。回想一下上一篇文章,树开始时是一个空的叶子节点:
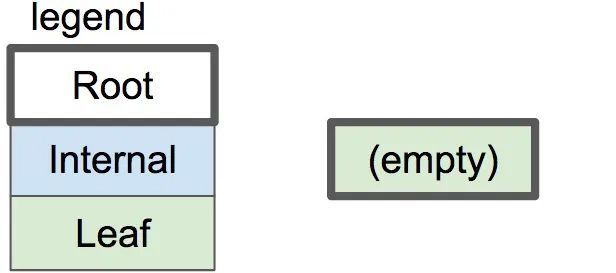
空树
可以一直添加键值对直到叶子节点填满:
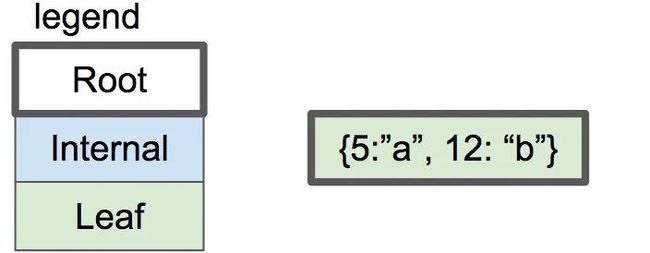
单节点B树
当我们第一次打开数据库文件,文件是空的,所以我们把页面0作为空的叶子节点(也是根节点):
Table* db_open(const char* filename) {
Pager* pager = pager_open(filename);
- uint32_t num_rows = pager->file_length / ROW_SIZE;
Table* table = malloc(sizeof(Table));
table->pager = pager;
- table->num_rows = num_rows;
+ table->root_page_num = 0;
+
+ if (pager->num_pages == 0) {
+ // New database file. Initialize page 0 as leaf node.
+ void* root_node = get_page(pager, 0);
+ initialize_leaf_node(root_node);
+ }
return table;
}
接下来我们写个函数来向叶子节点插入键值对,它以光标为输入,作为插入的位置。
+void leaf_node_insert(Cursor* cursor, uint32_t key, Row* value) {
+ void* node = get_page(cursor->table->pager, cursor->page_num);
+
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ if (num_cells >= LEAF_NODE_MAX_CELLS) {
+ // Node full
+ printf("Need to implement splitting a leaf node.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ if (cursor->cell_num < num_cells) {
+ // Make room for new cell
+ for (uint32_t i = num_cells; i > cursor->cell_num; i--) {
+ memcpy(leaf_node_cell(node, i), leaf_node_cell(node, i - 1),
+ LEAF_NODE_CELL_SIZE);
+ }
+ }
+
+ *(leaf_node_num_cells(node)) += 1;
+ *(leaf_node_key(node, cursor->cell_num)) = key;
+ serialize_row(value, leaf_node_value(node, cursor->cell_num));
+}
+
我们还没实现拆分,因此如果节点满了就会出错。接下来,我们将单元格向右移动一个空间,为新单元格腾出空间。然后,我们将新的键/值写入空白处。
由于我们假设树只有一个节点,因此execute_insert()函数只需要调用此辅助方法:
ExecuteResult execute_insert(Statement* statement, Table* table) {
- if (table->num_rows >= TABLE_MAX_ROWS) {
+ void* node = get_page(table->pager, table->root_page_num);
+ if ((*leaf_node_num_cells(node) >= LEAF_NODE_MAX_CELLS)) {
return EXECUTE_TABLE_FULL;
}
Row* row_to_insert = &(statement->row_to_insert);
Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, cursor_value(cursor));
- table->num_rows += 1;
+ leaf_node_insert(cursor, row_to_insert->id, row_to_insert);
free(cursor);
有了这些更改,我们的数据库就能像之前一样工作了。但是现在返回了“table full”的报错,因为目前我们不能拆分节点。
那么一个叶子节点可以承载多少行?
打印常量的命令
我现在添加一个新的元命令,用它可以打印出一些你感兴趣的常数。
+void print_constants() {
+ printf("ROW_SIZE: %d\n", ROW_SIZE);
+ printf("COMMON_NODE_HEADER_SIZE: %d\n", COMMON_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_HEADER_SIZE: %d\n", LEAF_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_CELL_SIZE: %d\n", LEAF_NODE_CELL_SIZE);
+ printf("LEAF_NODE_SPACE_FOR_CELLS: %d\n", LEAF_NODE_SPACE_FOR_CELLS);
+ printf("LEAF_NODE_MAX_CELLS: %d\n", LEAF_NODE_MAX_CELLS);
+}
+
@@ -294,6 +376,14 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
db_close(table);
exit(EXIT_SUCCESS);
+ } else if (strcmp(input_buffer->buffer, ".constants") == 0) {
+ printf("Constants:\n");
+ print_constants();
+ return META_COMMAND_SUCCESS;
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
我再添加一段测试代码,这样常量有变化时我们可以被通知到。
+ it 'prints constants' do
+ script = [
+ ".constants",
+ ".exit",
+ ]
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Constants:",
+ "ROW_SIZE: 293",
+ "COMMON_NODE_HEADER_SIZE: 6",
+ "LEAF_NODE_HEADER_SIZE: 10",
+ "LEAF_NODE_CELL_SIZE: 297",
+ "LEAF_NODE_SPACE_FOR_CELLS: 4086",
+ "LEAF_NODE_MAX_CELLS: 13",
+ "db > ",
+ ])
+ end
现在我们的表可以承载最多13行了。
树的可视化
为了帮助代码调试和可视化,我再添加元命令来打印出B树。
+void print_leaf_node(void* node) {
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ printf("leaf (size %d)\n", num_cells);
+ for (uint32_t i = 0; i < num_cells; i++) {
+ uint32_t key = *leaf_node_key(node, i);
+ printf(" - %d : %d\n", i, key);
+ }
+}
+
@@ -294,6 +376,14 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table* table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
db_close(table);
exit(EXIT_SUCCESS);
+ } else if (strcmp(input_buffer->buffer, ".btree") == 0) {
+ printf("Tree:\n");
+ print_leaf_node(get_page(table->pager, 0));
+ return META_COMMAND_SUCCESS;
} else if (strcmp(input_buffer->buffer, ".constants") == 0) {
printf("Constants:\n");
print_constants();
return META_COMMAND_SUCCESS;
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
测试:
+ it 'allows printing out the structure of a one-node btree' do
+ script = [3, 1, 2].map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".btree"
+ script << ".exit"
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > Executed.",
+ "db > Executed.",
+ "db > Tree:",
+ "leaf (size 3)",
+ " - 0 : 3",
+ " - 1 : 1",
+ " - 2 : 2",
+ "db > "
+ ])
+ end
目前我们还是没法实现按顺序存储行。你会注意到,execute_insert()以table_end()的返回值为位置插入数据到叶节点中。因此像以前一样,行按插入顺序存储。
下一篇
这一切似乎都倒退了。现在,我们的数据库存储的行比以前少了,而且我们仍按未排序的顺序存储行。但就像我刚开始所说的那样,这是一个很大的变化,将其分解为可管理的步骤非常重要。
下次,我们将实现通过主键查找数据,并开始按排序顺序存储行。
代码如下:
@@ -62,29 +62,101 @@ const uint32_t ROW_SIZE = ID_SIZE + USERNAME_SIZE + EMAIL_SIZE;
const uint32_t PAGE_SIZE = 4096;
#define TABLE_MAX_PAGES 100
-const uint32_t ROWS_PER_PAGE = PAGE_SIZE / ROW_SIZE;
-const uint32_t TABLE_MAX_ROWS = ROWS_PER_PAGE * TABLE_MAX_PAGES;
typedef struct {
int file_descriptor;
uint32_t file_length;
+ uint32_t num_pages;
void* pages[TABLE_MAX_PAGES];
} Pager;
typedef struct {
Pager* pager;
- uint32_t num_rows;
+ uint32_t root_page_num;
} Table;
typedef struct {
Table* table;
- uint32_t row_num;
+ uint32_t page_num;
+ uint32_t cell_num;
bool end_of_table; // Indicates a position one past the last element
} Cursor;
+typedef enum { NODE_INTERNAL, NODE_LEAF } NodeType;
+
+/*
+ * Common Node Header Layout
+ */
+const uint32_t NODE_TYPE_SIZE = sizeof(uint8_t);
+const uint32_t NODE_TYPE_OFFSET = 0;
+const uint32_t IS_ROOT_SIZE = sizeof(uint8_t);
+const uint32_t IS_ROOT_OFFSET = NODE_TYPE_SIZE;
+const uint32_t PARENT_POINTER_SIZE = sizeof(uint32_t);
+const uint32_t PARENT_POINTER_OFFSET = IS_ROOT_OFFSET + IS_ROOT_SIZE;
+const uint8_t COMMON_NODE_HEADER_SIZE =
+ NODE_TYPE_SIZE + IS_ROOT_SIZE + PARENT_POINTER_SIZE;
+
+/*
+ * Leaf Node Header Layout
+ */
+const uint32_t LEAF_NODE_NUM_CELLS_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_NUM_CELLS_OFFSET = COMMON_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_HEADER_SIZE =
+ COMMON_NODE_HEADER_SIZE + LEAF_NODE_NUM_CELLS_SIZE;
+
+/*
+ * Leaf Node Body Layout
+ */
+const uint32_t LEAF_NODE_KEY_SIZE = sizeof(uint32_t);
+const uint32_t LEAF_NODE_KEY_OFFSET = 0;
+const uint32_t LEAF_NODE_VALUE_SIZE = ROW_SIZE;
+const uint32_t LEAF_NODE_VALUE_OFFSET =
+ LEAF_NODE_KEY_OFFSET + LEAF_NODE_KEY_SIZE;
+const uint32_t LEAF_NODE_CELL_SIZE = LEAF_NODE_KEY_SIZE + LEAF_NODE_VALUE_SIZE;
+const uint32_t LEAF_NODE_SPACE_FOR_CELLS = PAGE_SIZE - LEAF_NODE_HEADER_SIZE;
+const uint32_t LEAF_NODE_MAX_CELLS =
+ LEAF_NODE_SPACE_FOR_CELLS / LEAF_NODE_CELL_SIZE;
+
+uint32_t* leaf_node_num_cells(void* node) {
+ return node + LEAF_NODE_NUM_CELLS_OFFSET;
+}
+
+void* leaf_node_cell(void* node, uint32_t cell_num) {
+ return node + LEAF_NODE_HEADER_SIZE + cell_num * LEAF_NODE_CELL_SIZE;
+}
+
+uint32_t* leaf_node_key(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num);
+}
+
+void* leaf_node_value(void* node, uint32_t cell_num) {
+ return leaf_node_cell(node, cell_num) + LEAF_NODE_KEY_SIZE;
+}
+
+void print_constants() {
+ printf("ROW_SIZE: %d\n", ROW_SIZE);
+ printf("COMMON_NODE_HEADER_SIZE: %d\n", COMMON_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_HEADER_SIZE: %d\n", LEAF_NODE_HEADER_SIZE);
+ printf("LEAF_NODE_CELL_SIZE: %d\n", LEAF_NODE_CELL_SIZE);
+ printf("LEAF_NODE_SPACE_FOR_CELLS: %d\n", LEAF_NODE_SPACE_FOR_CELLS);
+ printf("LEAF_NODE_MAX_CELLS: %d\n", LEAF_NODE_MAX_CELLS);
+}
+
+void print_leaf_node(void* node) {
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ printf("leaf (size %d)\n", num_cells);
+ for (uint32_t i = 0; i < num_cells; i++) {
+ uint32_t key = *leaf_node_key(node, i);
+ printf(" - %d : %d\n", i, key);
+ }
+}
+
void print_row(Row* row) {
printf("(%d, %s, %s)\n", row->id, row->username, row->email);
}
@@ -101,6 +173,8 @@ void deserialize_row(void *source, Row* destination) {
memcpy(&(destination->email), source + EMAIL_OFFSET, EMAIL_SIZE);
}
+void initialize_leaf_node(void* node) { *leaf_node_num_cells(node) = 0; }
+
void* get_page(Pager* pager, uint32_t page_num) {
if (page_num > TABLE_MAX_PAGES) {
printf("Tried to fetch page number out of bounds. %d > %d\n", page_num,
@@ -128,6 +202,10 @@ void* get_page(Pager* pager, uint32_t page_num) {
}
pager->pages[page_num] = page;
+
+ if (page_num >= pager->num_pages) {
+ pager->num_pages = page_num + 1;
+ }
}
return pager->pages[page_num];
@@ -136,8 +214,12 @@ void* get_page(Pager* pager, uint32_t page_num) {
Cursor* table_start(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = 0;
- cursor->end_of_table = (table->num_rows == 0);
+ cursor->page_num = table->root_page_num;
+ cursor->cell_num = 0;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->end_of_table = (num_cells == 0);
return cursor;
}
@@ -145,24 +227,28 @@ Cursor* table_start(Table* table) {
Cursor* table_end(Table* table) {
Cursor* cursor = malloc(sizeof(Cursor));
cursor->table = table;
- cursor->row_num = table->num_rows;
+ cursor->page_num = table->root_page_num;
+
+ void* root_node = get_page(table->pager, table->root_page_num);
+ uint32_t num_cells = *leaf_node_num_cells(root_node);
+ cursor->cell_num = num_cells;
cursor->end_of_table = true;
return cursor;
}
void* cursor_value(Cursor* cursor) {
- uint32_t row_num = cursor->row_num;
- uint32_t page_num = row_num / ROWS_PER_PAGE;
+ uint32_t page_num = cursor->page_num;
void* page = get_page(cursor->table->pager, page_num);
- uint32_t row_offset = row_num % ROWS_PER_PAGE;
- uint32_t byte_offset = row_offset * ROW_SIZE;
- return page + byte_offset;
+ return leaf_node_value(page, cursor->cell_num);
}
void cursor_advance(Cursor* cursor) {
- cursor->row_num += 1;
- if (cursor->row_num >= cursor->table->num_rows) {
+ uint32_t page_num = cursor->page_num;
+ void* node = get_page(cursor->table->pager, page_num);
+
+ cursor->cell_num += 1;
+ if (cursor->cell_num >= (*leaf_node_num_cells(node))) {
cursor->end_of_table = true;
}
}
@@ -185,6 +271,12 @@ Pager* pager_open(const char* filename) {
Pager* pager = malloc(sizeof(Pager));
pager->file_descriptor = fd;
pager->file_length = file_length;
+ pager->num_pages = (file_length / PAGE_SIZE);
+
+ if (file_length % PAGE_SIZE != 0) {
+ printf("Db file is not a whole number of pages. Corrupt file.\n");
+ exit(EXIT_FAILURE);
+ }
for (uint32_t i = 0; i < TABLE_MAX_PAGES; i++) {
pager->pages[i] = NULL;
@@ -194,11 +285,15 @@ Pager* pager_open(const char* filename) {
@@ -195,11 +287,16 @@ Pager* pager_open(const char* filename) {
Table* db_open(const char* filename) {
Pager* pager = pager_open(filename);
- uint32_t num_rows = pager->file_length / ROW_SIZE;
Table* table = malloc(sizeof(Table));
table->pager = pager;
- table->num_rows = num_rows;
+ table->root_page_num = 0;
+
+ if (pager->num_pages == 0) {
+ // New database file. Initialize page 0 as leaf node.
+ void* root_node = get_page(pager, 0);
+ initialize_leaf_node(root_node);
+ }
return table;
}
@@ -234,7 +331,7 @@ void close_input_buffer(InputBuffer* input_buffer) {
free(input_buffer);
}
-void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
+void pager_flush(Pager* pager, uint32_t page_num) {
if (pager->pages[page_num] == NULL) {
printf("Tried to flush null page\n");
exit(EXIT_FAILURE);
@@ -242,7 +337,7 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
@@ -249,7 +346,7 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
}
ssize_t bytes_written =
- write(pager->file_descriptor, pager->pages[page_num], size);
+ write(pager->file_descriptor, pager->pages[page_num], PAGE_SIZE);
if (bytes_written == -1) {
printf("Error writing: %d\n", errno);
@@ -252,29 +347,16 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
@@ -260,29 +357,16 @@ void pager_flush(Pager* pager, uint32_t page_num, uint32_t size) {
void db_close(Table* table) {
Pager* pager = table->pager;
- uint32_t num_full_pages = table->num_rows / ROWS_PER_PAGE;
- for (uint32_t i = 0; i < num_full_pages; i++) {
+ for (uint32_t i = 0; i < pager->num_pages; i++) {
if (pager->pages[i] == NULL) {
continue;
}
- pager_flush(pager, i, PAGE_SIZE);
+ pager_flush(pager, i);
free(pager->pages[i]);
pager->pages[i] = NULL;
}
- // There may be a partial page to write to the end of the file
- // This should not be needed after we switch to a B-tree
- uint32_t num_additional_rows = table->num_rows % ROWS_PER_PAGE;
- if (num_additional_rows > 0) {
- uint32_t page_num = num_full_pages;
- if (pager->pages[page_num] != NULL) {
- pager_flush(pager, page_num, num_additional_rows * ROW_SIZE);
- free(pager->pages[page_num]);
- pager->pages[page_num] = NULL;
- }
- }
-
int result = close(pager->file_descriptor);
if (result == -1) {
printf("Error closing db file.\n");
@@ -305,6 +389,14 @@ MetaCommandResult do_meta_command(InputBuffer* input_buffer, Table *table) {
if (strcmp(input_buffer->buffer, ".exit") == 0) {
db_close(table);
exit(EXIT_SUCCESS);
+ } else if (strcmp(input_buffer->buffer, ".btree") == 0) {
+ printf("Tree:\n");
+ print_leaf_node(get_page(table->pager, 0));
+ return META_COMMAND_SUCCESS;
+ } else if (strcmp(input_buffer->buffer, ".constants") == 0) {
+ printf("Constants:\n");
+ print_constants();
+ return META_COMMAND_SUCCESS;
} else {
return META_COMMAND_UNRECOGNIZED_COMMAND;
}
@@ -354,16 +446,39 @@ PrepareResult prepare_statement(InputBuffer* input_buffer,
return PREPARE_UNRECOGNIZED_STATEMENT;
}
+void leaf_node_insert(Cursor* cursor, uint32_t key, Row* value) {
+ void* node = get_page(cursor->table->pager, cursor->page_num);
+
+ uint32_t num_cells = *leaf_node_num_cells(node);
+ if (num_cells >= LEAF_NODE_MAX_CELLS) {
+ // Node full
+ printf("Need to implement splitting a leaf node.\n");
+ exit(EXIT_FAILURE);
+ }
+
+ if (cursor->cell_num < num_cells) {
+ // Make room for new cell
+ for (uint32_t i = num_cells; i > cursor->cell_num; i--) {
+ memcpy(leaf_node_cell(node, i), leaf_node_cell(node, i - 1),
+ LEAF_NODE_CELL_SIZE);
+ }
+ }
+
+ *(leaf_node_num_cells(node)) += 1;
+ *(leaf_node_key(node, cursor->cell_num)) = key;
+ serialize_row(value, leaf_node_value(node, cursor->cell_num));
+}
+
ExecuteResult execute_insert(Statement* statement, Table* table) {
- if (table->num_rows >= TABLE_MAX_ROWS) {
+ void* node = get_page(table->pager, table->root_page_num);
+ if ((*leaf_node_num_cells(node) >= LEAF_NODE_MAX_CELLS)) {
return EXECUTE_TABLE_FULL;
}
Row* row_to_insert = &(statement->row_to_insert);
Cursor* cursor = table_end(table);
- serialize_row(row_to_insert, cursor_value(cursor));
- table->num_rows += 1;
+ leaf_node_insert(cursor, row_to_insert->id, row_to_insert);
free(cursor);
规格:
+ it 'allows printing out the structure of a one-node btree' do
+ script = [3, 1, 2].map do |i|
+ "insert #{i} user#{i} person#{i}@example.com"
+ end
+ script << ".btree"
+ script << ".exit"
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Executed.",
+ "db > Executed.",
+ "db > Executed.",
+ "db > Tree:",
+ "leaf (size 3)",
+ " - 0 : 3",
+ " - 1 : 1",
+ " - 2 : 2",
+ "db > "
+ ])
+ end
+
+ it 'prints constants' do
+ script = [
+ ".constants",
+ ".exit",
+ ]
+ result = run_script(script)
+
+ expect(result).to match_array([
+ "db > Constants:",
+ "ROW_SIZE: 293",
+ "COMMON_NODE_HEADER_SIZE: 6",
+ "LEAF_NODE_HEADER_SIZE: 10",
+ "LEAF_NODE_CELL_SIZE: 297",
+ "LEAF_NODE_SPACE_FOR_CELLS: 4086",
+ "LEAF_NODE_MAX_CELLS: 13",
+ "db > ",
+ ])
+ end
end
原文链接:https://cstack.github.io/db_tutorial/parts/part8.html
Kubernetes实战培训

Kubernetes实战培训将于2020年7月24日在深圳开课,3天时间带你系统掌握Kubernetes,学习效果不好可以继续学习。本次培训包括:云原生介绍、微服务;Docker基础、Docker工作原理、镜像、网络、存储、数据卷、安全;Kubernetes架构、核心组件、常用对象、网络、存储、认证、服务发现、调度和服务质量保证、日志、监控、告警、Helm、实践案例等,点击下方图片或者阅读原文链接查看详情。
