WSDM Cup 2020检索排序评测任务第一名经验总结
1.背景
第13届“国际网络搜索与数据挖掘会议”(WSDM 2020)于2月3日在美国休斯敦召开,该会议由SIGIR、SIGKDD、SIGMOD和SIGWEB四个专委会共同协调筹办,在互联网搜索、数据挖掘领域享有很高学术声誉。本届会议论文录用率仅约15%,并且WSDM历来注重前沿技术的落地应用,每届大会设有的WSDM Cup环节提供工业界真实场景中的数据和任务用以研究和评测。
今年的WSDM Cup设有3个评测任务,吸引了微软、华为、腾讯、京东、中国科学院、清华大学、台湾大学等众多国内外知名机构的参与。美团搜索与NLP部继去年获得了WSDM Cup 2019第二名后,今年继续发力,拿下了WSDM Cup 2020 Task 1:Citation Intent Recognition榜单的第一名。
本次参与的是由微软研究院提出的Citation Intent Recognition评测任务,该任务共吸引了全球近600名研究者的参与。本次评测中我们引入高校合作,参评团队Ferryman由搜索与NLP部-NLP中心的刘帅朋、江会星及电子科技大学、东南大学的两位科研人员共同组建。团队提出了一种基于BERT和LightGBM的多模融合检索排序解决方案,该方案同时被WSDM Cup 2020录用为专栏论文。

2.任务简介
本次参与的任务一(WSDM Cup 2020 Task 1: Citation Intent Recognition)由微软研究院发起,任务要求参赛者根据论文中对某项科研工作的描述,从论文库中找出与该描述最匹配的Top3论文。举例说明如下:
某论文中对科研工作[1]和[2]的描述如下:
An efficient implementation based on BERT [1] and graph neural network (GNN) [2] is introduced.
参赛者需要根据这段科研描述从论文库中检索与[1][2]相关工作最匹配论文。
在本例中:
与工作[1]最匹配的论文题目应该是:
[1] BERT: Pre-training of deep bidirectional transformers for language understanding.
与工作[2]最匹配的论文题目应该是:
[2] Relational inductive biases, deep learning, and graph networks.
由上述分析可知,该任务是经典的检索排序任务,即根据文本Query从候选Documents中找出Top N个最相关的Documents,核心技术包括文本语义理解和搜索排序。
2.1 评测数据
本次评测数据分为论文候选集、训练集、验证集和测试集四个部分,各部分数据的表述如表1所示:

对本次评测任务及数据分析可以发现本次评测存在以下特点:
- 与工业界的实际场景类似,本次任务数据量规模比较大,要求制定方案时需要同时考虑算法性能和效果,因此相关评测方案可以直接落地应用或有间接参考的价值;
- 为了保证方案具有一定落地实用价值,本任务要求测试集的结果需要在48小时内提交,这也对解决方案的整体效率提出了更高的要求,像常见的使用非常多模型的融合提升方案,在本评测中就不太适用;
- 跟自然语言处理领域的一般任跟自然语言处理领域的一般任务不同,本次评测任务中数据多来源于生命科学领域,存在较多的专有词汇和固定表述模式,因此一些常见的方法模型(例如在通用语料上预训练的BERT、ELMo等预训练模型)在该任务上的直接应用是不合适的,这也是本次任务的难点之一。
2.2 评测指标
评测使用的评价指标为Mean Average Precision @3 (MAP@3), 形式如下:

其中,|U|是需要预测的description总个数,P(k)是在k处的精度,n是paper个数。举例来说,如果在第一个位置预测正确,得分为1;第二个位置预测正确,得分为1/2;第三个位置预测正确,得分为1/3。
3.模型方法
通过对评测数据、任务和评价指标等分析,综合考量方案的效率和精准性后,本次评测中使用的算法架构包括“检索召回”和“精准排序”两个阶段。其中,检索召回阶段负责从候选集中高效快速地召回候选Documents,从而缩减问题规模,降低排序阶段的复杂度,此阶段注重召回算法的效率和召回率;精准排序阶段负责对召回数据进行重排序,采用Learning to Rank相关策略进行排序最优解求解。

3.1 检索召回
目标任务:使用高效的匹配算法对候选集进行粗筛,为后续精排阶段缩减候选排序的数据规模。
性能要求:召回阶段的方案需要权衡召回覆盖率和算法效率两个指标,一方面召回覆盖率决定了后续精排算法的效果上限,另一方面单纯追求覆盖率而忽视算法效率则不能满足评测时效性的要求。
检索召回方案:比赛过程中对比实验了两种召回方案,基于“文本语义向量表征“和“基于空间向量模型 + Bag-of-Ngram”。由于本任务文本普遍较长且专有名词较多等数据特点,实验表明“基于空间向量模型 + Bag-of-Ngram”的召回方案效果更好,下表中列出了使用的相关模型及其实验结果(recall@200)。可以看到相比于传统的BM25和TFIDF等算法,F1EXP、F2EXP等公理检索模型(Axiomatic Retrieval Models)可以取得更高的召回覆盖率,该类模型增加了一些公理约束条件,例如基本术语频率约束,术语区分约束和文档长度归一化约束等等。
F2EXP定义如下:

其中,Q表示查询query ,D表示候选文档,C(t, Q)是词t在Q中的频次,|D|表示文档长度,avdl为文档的平均长度,N为文档总数,df(t)为词t的文档频率。
为了提升召回算法的效果,我们使用倒排索引技术对数据进行建模,然后在此基础上实现了F1EXP、DFR、F2EXP、BM25、TFIDF等多种检索算法,极大了提升了召回部分的运行效率。为了平衡召回率和计算成本,最后使用F1EXP、BM25、TFIDF 3种算法各召回50条结果融合作为后续精排候选数据,在验证集上测试,召回覆盖率可以到70%。

3.2 精准排序
精排阶段基于Learning to Rank的思想进行方案设计,提出了两种解决方案,一种是基于Pairwise-BERT的方案,另一种是基于LightGBM的方案,下面分别进行介绍:
1)基于BERT的排序模型
BERT是近年来NLP领域最重大的研究进展之一,本次评测中,我们也尝试引入BERT并对原始模型使用Pointwise Approach的模式进行改进,引入Pairwise Approach模式,在排序任务上取得了一定的效果提升。原始BERT 使用Pointwise模式把排序问题看做单文档分类问题,Pointwise优化的目标是单条Query与Document之间的相关性,即回归的目标是label。而Pairwise方法的优化目标是两个候选文档之间的排序位次(匹配程度),更适合排序任务的场景。具体来说,对原始BERT主要有两点改进,如下图中所示:
改进训练样本构造形式:Pointwise模式下样本是按照
改进模型优化目标:Pointwise模式下模型使用的Cross Entropy Loss作为损失函数,优化目标是提升分类效果,而Pairwise模式下模型使用Hing Loss作为损失函数,优化目标是加大正例和负例在语义空间的区分度。

在基于BERT进行排序的过程中,由于评测数据多为生命科学领域的论文,我们还使用了SciBERT和BioBERT等基于特定领域语料的预训练BERT模型,相比Google的通用BERT较大的效果提升。
2)基于LightGBM的排序模型
不过,上面介绍的基于BERT的方案构建的端到端的排序学习框架,仍然存在一些不足。首先,BERT模型的输入最大为512个字符,对于数据中的部分长语料需要进行截断处理,这就损失了文本中的部分语义信息;其次,本任务中语料多来自科学论文,跟已有的预训练模型还是存在偏差,这也在一定程度上限制了模型对数据的表征能力。此外,BERT模型网络结构较为复杂,在运行效率上不占优势。综合上述三方面的原因,我们提出了基于LightGBM的排序解决方案。
LightGBM是微软2017年提出,比Xgboost更强大、速度更快的模型。LightGBM在传统的GBDT基础上有如下创新和改进:
采用Gradient-based One-Side Sampling(GOSS)技术去掉很大部分梯度很小的数据,只使用剩下的去估计信息增益,避免低梯度长尾部分的影响;
采用Exclusive Feature Bundling(EFB)技术以减少特征的数量;
传统GBDT算法最耗时的步骤是使用Pre-Sorted方式找到最优划分点,其会在排好序的特征值上枚举所有可能的特征点,而LightGBM中会使用histogram算法替换了GBDT传统的Pre-Sorted,牺牲一定精度换取了速度。
LightGBM采用Leaf-Wise生长策略,每次从当前所有叶子中找到分裂增益最大的一个叶子,然后分裂,如此循环。因此同Level-Wise相比,在分裂次数相同的情况下,Leaf-Wise可以降低更多的误差,得到更好的精度。
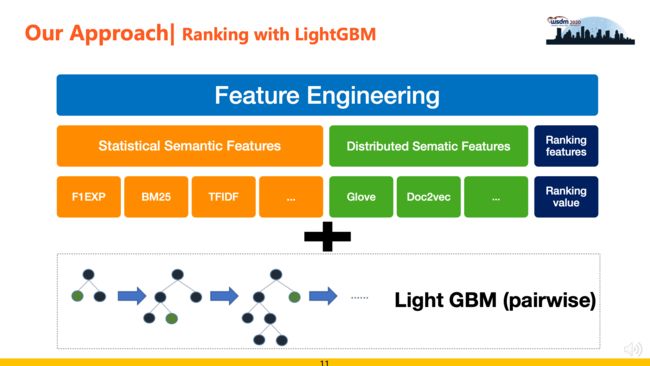
基于Light GBM的方案需要特征工程的配合。在我们实践中,特征主要包括Statistic Semantic Features(包括F1EXP、F2EXP、TFIDF、BM25等)、Distributed Semantic Features(包括Glove、Doc2vec等)和Ranking Features(召回阶段的排序序列特征),并且这些特征分别从标题、摘要、关键词等多个维度进行抽取,最终构建成特征集合,配合LightGBM的pairwise模式进行训练。该方法的优点是运行效率高,可解释性强,缺点是特征工程阶段比较依赖人工对数据的理解和分析。
4.实验结果
我们分别对比实验了不同方案的效果,可以发现无论是基于BERT的排序方案还是基于LightGBM的排序方案,Pairwise的模式都会优于Pointwise的模式,具体实验数据如表2所示:

5.总结与展望
本文主要介绍了美团搜索与NLP部在WSDM Cup 2020 Task 1评测中的实践方案,我们构建了召回+排序的整体技术框架。在召回阶段引入多种召回策略和倒排索引保证召回的速度和覆盖率;在排序阶段提出了基于Pairwise模式的BERT排序模型和基于LightGBM的排序模型。最终,美团也非常荣幸地取得了榜单第一名的成绩。
当然,在对本次评测进行复盘分析后,我们认为该任务还有较大提升的空间。首先在召回阶段,当前方案召回率为70%左右,可以尝试新的召回方案来提高召回率;其次,在排序阶段,还可以尝试基于Listwise的模式进行排序模型的训练,相比Pairwise的模式,Listwise模式下模型输入空间变为Query跟全部Candidate Doc,理论上可以使模型学习到更好的排序能力。后续,我们还会再不断进行优化,追求卓越。
6.落地应用
本次评测任务与搜索与NLP部智能客服、搜索排序等业务中多个关键应用场景高度契合。目前,我们正在积极试验将获奖方案在智能问答、FAQ推荐和搜索核心排序等场景进行落地探索,用最优秀的技术解决方案来提升产品质量和服务水平,努力践行“帮大家吃得更好,生活更好”的使命。
参考文献
[1]Fang H, Zhai C X. An exploration of axiomatic approaches to information retrieval[C]//Proceedings of the 28th annual international ACM SIGIR conference on Research and development in information retrieval. 2005: 480-487.
[2]Wang Y, Yang P, Fang H. Evaluating Axiomatic Retrieval Models in the Core Track[C]//TREC. 2017.
[3]Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[4]Lee J, Yoon W, Kim S, et al. BioBERT: a pre-trained biomedical language representation model for biomedical text mining[J]. Bioinformatics, 2020, 36(4): 1234-1240.
[5]Beltagy I, Lo K, Cohan A. SciBERT: A pretrained language model for scientific text[C]//Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019: 3606-3611.
[6]Chen W, Liu S, Bao W, et al. An Effective Approach for Citation Intent Recognition Based on Bert and LightGBM. WSDM Cup 2020, Houston, Texas, USA, February 2020.
[7]Ke G, Meng Q, Finley T, et al. Lightgbm: A highly efficient gradient boosting decision tree[C]//Advances in neural information processing systems. 2017: 3146-3154.
作者简介
帅朋,美团AI平台搜索与NLP部。
会星,美团AI平台搜索与NLP部NLP中心对话平台负责人,研究员。
仲远,美团AI平台搜索与NLP部负责人,高级研究员、高级总监。
招聘信息
美团-AI平台-搜索与NLP部-NLP中心在北京/上海长期招聘NLP算法专家/研究员、对话平台研发工程师/技术专家、知识图谱算法专家,欢迎感兴趣的同学发送简历至:[email protected](邮件标题注明:NLP中心-北京/上海)。
阅读更多技术文章,请关注微信公众号-美团技术团队!
