(十二)BN和LN
文章目录
- 一、神经网络为什么要进行batch norm?
- 二、BN
- 三、LN
- 参考文献
机器学习领域有个重要假设:IID独立同分布假设
假设训练数据和测试数据是满足相同分布
独立同分布假设是通过训练集得到的模型在测试集能有好效果的基本保障。
Batch Normalization作用 :
在深度神经网络训练过程,使得每一层神经网络的输入保持相同分布。
神经网络随着深度加深,训练变得困难。
relu激活函数, 残差网络都是解决梯度消失等由于深度带来的问题。
BN同样也是为了解决深度带来的问题。
Batch Normalization基本思想 :
神经网络在训练过程中,随着深度加深,输入值分布会发生偏移,向取值区间上下两端靠近,如Sigmoid函数,就会导致反向传播时低层神经网络的梯度消失,这是深层网络收敛越来越慢的重要原因。
Batch Normalization通过一定的规范化手段,把每层神经网络输入值的分布强行拉回到均值为0方差为1的标准正态分布。(纠偏回正过程)
使得分布回到非线性函数对输入比较敏感的区域,使得损失函数能发生较大的变化(梯度变大),避免梯度消失问题。
同时梯度变大能加快模型收敛速度,提高训练速度。
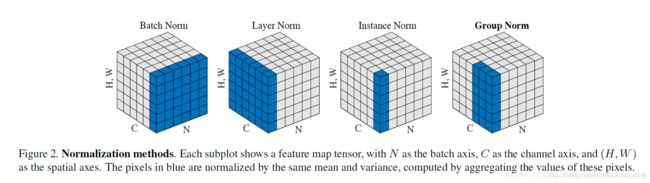
- 无非是减去均值,除以标准差,再施以线性映射。
- 这些归一化算法的主要区别在于操作的 feature map 维度不同。
- 为了activation能更有效地使用输入信息,所以一般BN放在激活函数之前。
- BatchNorm和LayerNorm
一、神经网络为什么要进行batch norm?
通常我们在使用数据之前,会对输入数据做了标准化处理:处理后的任意一个特征在数据集中所有样本上的均值为 0、标准差为 1。标准化处理输入数据使各个特征的分布相近:这往往更容易训练出有效的模型。
通常来说,数据标准化预处理对于浅层模型就足够有效了。随着模型训练的进行,当每层中参数更新时,靠近输出层的输出较难出现剧烈变化。但对于深层神经网络来说,即使输入数据已做标准化,训练中模型参数的更新依然很容易造成靠近输出层输出的剧烈变化。这种计算数值的不稳定性通常令我们难以训练出有效的深度模型。
为解决这一问题,提出了批量归一化,即batch norm,在模型训练时,批量归一化利用小批量上的均值和标准差,不断调整神经网络中间输出,从而使得整个神经网络在各层的中间输出的数值更稳定。
二、BN
类比为一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 W 个字符。BN 求均值时,相当于把这些书按页码一一对应地加起来(例如第1本书第36页,第2本书第36页…),再除以每个页码下的字符总数:N×H×W,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),求标准差时也是同理。
首先,在进行训练之前,一般要对数据做归一化,使其分布一致,但是在深度神经网络训练过程中,通常以送入网络的每一个batch训练,这样每个batch具有不同的分布;此外,为了解决internal covarivate shift问题,这个问题定义是随着batch normalizaiton这篇论文提出的,在训练过程中,数据分布会发生变化,对下一层网络的学习带来困难。
所以batch normalization就是强行将数据拉回到均值为0,方差为1的正太分布上,这样不仅数据分布一致,而且避免发生梯度消失。
算法过程:
- 沿着通道计算每个batch的均值u
- 沿着通道计算每个batch的方差σ^2
- 对x做归一化,x’=(x-u)/开根号(σ^2+ε)
- 加入缩放和平移变量γ和β ,归一化后的值,y=γx’+β
加入缩放平移变量的原因是:保证每一次数据经过归一化后还保留原有学习来的特征,同时又能完成归一化操作,加速训练。 这两个参数是用来学习的参数。
三、LN
BatchNormalization、LayerNormalization、InstanceNorm、GroupNorm简介
batch normalization存在以下缺点:
对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布;
BN实际使用时需要计算并且保存某一层神经网络batch的均值和方差等统计信息,对于对一个固定深度的前向神经网络(DNN,CNN)使用BN,很方便;但对于RNN来说,sequence的长度是不一致的,换句话说RNN的深度不是固定的,不同的time-step需要保存不同的statics特征,可能存在一个特殊sequence比其他sequence长很多,这样training时,计算很麻烦。
与BN不同,LN是针对深度网络的某一层的所有神经元的输入按以下公式进行normalize操作。
BN 的一个缺点是需要较大的 batchsize才能合理估训练数据的均值和方差,这导致内存很可能不够用,同时它也很难应用在训练数据长度不同的 RNN 模型上。Layer Normalization (LN) 的一个优势是不需要批训练,在单条数据内部就能归一化。
BN与LN的区别在于:
LN中同层神经元输入拥有相同的均值和方差,不同的输入样本有不同的均值和方差;
BN中则针对不同神经元输入计算均值和方差,同一个batch中的输入拥有相同的均值和方差。
所以,LN不依赖于batch的大小和输入sequence的深度,因此可以用于batchsize为1和RNN中对边长的输入sequence的normalize操作。
LN用于RNN效果比较明显,但是在CNN上,不如BN。
把一个 batch 的 feature 类比为一摞书。LN 求均值时,相当于把每一本书的所有字加起来,再除以这本书的字符总数:C×H×W,即求整本书的“平均字”,求标准差时也是同理。
参考文献
各种Normalization:BatchNorm、LayerNorm、InstanceNorm、GroupNorm、SwitchableNorm、AttentiveNorm
神经网络为什么要进行batch norm?
卷积神经网络 Batch Normalization作用与原理