应届生面试要点总结(4)JAVA多线程
线程池ThreadPoolExecutor
创建线程要花费昂贵的资源和时间,如果任务来了才创建线程那么响应时间会变长,而且一个进程能创建的线程数有限。为了避免这些问题,在程序启动的时候就创建若干线程来响应处理,它们被称为线程池,里面的线程叫工作线程。
corepoolsize:核心池的大小,默认情况下,在创建了线程池之后,线程池中个数为0,有任务来时,就会创建一个线程去执行任务,当池中个数到corepoolsize后,就把任务放在缓存队列中。
Maximumpoolsize:池中最多创建多少个线程。
Keeplivetime:线程未执行任务时,最多保存多长时间会终止,默认情况下,当线程池中个数>corepoolsize时,keeplivetime才起作用,直到线程数不大于corepoolsize。
workQueue:阻塞队列,用来存放等待被执行的任务。
threadFactory:线程工厂,用来创建线程。
线程池的状态:
当线程池创建后,running状态。
调用shutdown后,shutdown状态,此时不再接受新任务,等待已有任务执行完。
调用shutdownnow后,进入stop状态,不在接受新任务,并尝试终止正在执行的任务。
处于shutdown或stop状态,且所有线程已经销毁,任务缓存列表清空,线程池被设为terminated状态。
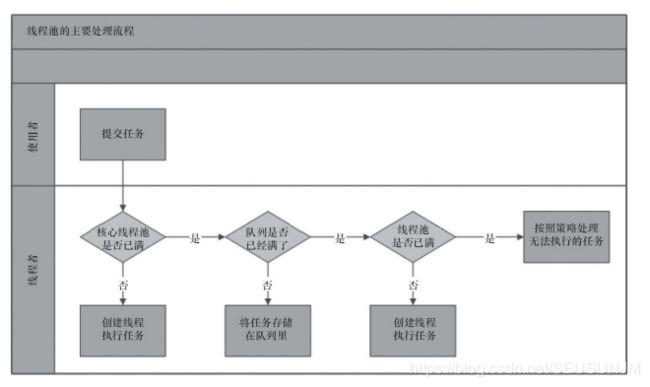
当有任务提交到线程池的操作:
若当前线程池中的线程数 若线程数>=corepoolsize,会尝试添加任务到任务缓存队列中去,若添加成功,则任务会等待空闲线程将其取出执行,若添加失败,则尝试创建线程去执行这个任务。 若线程数>=Maximumpoolsize,则采取拒绝策略: abortpolicy丢弃任务,抛出RejectExecutionException。 discardpolicy拒绝执行,不抛异常。 callerrunspolicy重新添加当前任务,重读调用excute方法。有反馈机制,使任务提交速度变慢。 使用线程池:我们只需要运行Executor类给我们提供的静态方法,就可以创建相应的线程池。 public static ExecutorService newSingleThreadExecutor() public static ExecutorService newFixedThreadPool() public static ExecutorService newCachedThreadPool() newSingleThreadPoolExecutor返回一个包含单线程的Executor,将多个任务交给这个Exector时,这个线程处理完成一个任务之后接着处理下一个任务,若该线程出现异常,将会有一个新的线程来代替。 newFixedThreadPool返回一个包含指定线程数目线程的线程池,若任务数多于线程数目,则没有执行的任务必须等待,直到有任务完成为止。 我们只需要将执行等待方法放入run方法中,将runnable接口是实现类交给线程的execute方法,作为他的一个参数,比如: Executor e = Executors.newSingleThreadExecutor(); e.execute(new Runnable() { public void run(){ } // 需要执行的任务 }) newCachedThreadpool:创建一个可缓存线程池,若线程池中线程数量超过处理需要,可灵活回收空闲线程(终止并从缓存中移除那些已有60秒未被使用的线程,因此长时间保存空闲的线程不会使用任何资源)。对于需要执行很多短期异步任务的程序来说,这个可以提高程序性能,因为长时间保持空闲的这种类型线程池,不会占用任何资源。调用缓存的线程池对象,将重用以前构造的线程(线程可用状态),若没有线程可用,则创建一个新线程添加到池中,缓存线程池将终止并移除60秒未被使用的线程。当线程池中缓存队列已满,并且线程数达到maximumpoolsize时,若还有任务到来,采取4种拒绝策略。 线程封闭threadlocal:仅在单线程内访问数据,比如threadlocal。threadlocal不继承thread,也不实现runnable接口,threadlocal类为每一个线程都维护了自己的变量拷贝。每个线程都拥有自己的独立变量,其作用在于数据独立。threadlocal采用hash表的方式来为每个线程提供一个独立的变量的副本,所以每个线程可以独立修改自己的变量副本,而不影响其他线程的副本。从线程角度看,目标变量就是线程本地变量。 ThreadlocalMap类是threadlocal类的静态内部类。它实现了键值对的设置和获取。每个线程对应一个threadlocalmap,从而实现了变量访问在不同线程中的隔离。因为每个线程的变量都是自己特有的,完全不会有并发错误。 当前线程的threadlocalmap是在第一次调用set方法时创建,并设置上对应的值。每个线程的数据还是在自己线程内部,只是用threadlocal引用。threadlocalmap(key, value)。key为当前threadlocal对象,value为变量值。一个线程的threadlocalmap中有很多变量,通过threadlocal对象判断选哪个对象。 volatile是轻量级的同步机制 volatile变量对于所有线程的可见性,指当一个线程修改了这个变量的值,新值对于其他线程是可见的,立即可知的。volatile在多线程下不一定安全,因为它只有可见性,有序性,无原子性。java中的运算并非原子操作,导致volatile变量的运算在并发情况下不一定安全。 每次使用volatile变量前,都必须从主内存刷新最新的值,用于保证能看见其他线程对该变量所做的修改之后的值。在工作内存中,每次修改volatile变量后,都必须立刻同步回主内存中,用于保证其他线程可以看到自己对该变量所做的修改。 volatile修饰的变量不会被指令重排序优化,保证代码执行顺序和程序顺序相同:当程序执行到volatile变量的读操作或写操作时,在其前面的操作肯定全部已经进行,且结果已经对后面的操作可见;在其后面的操作肯定还没执行。在指令优化时,不能将对volatile变量访问的语句放在其后面执行,也不能把volatile变量后的语句放到其前面执行。 happen-before有序性:对于一个volatile变量的写操作,先行发生于后面对这个变量的读操作。 当且仅当满足以下所有条件,才使用volatile变量:写操作不依赖当前值;该变量不会与其他变量一起纳入不变性条件;访问变量时不需要加锁。标记状态、双重检查。 volatile原理:观察加入volatile关键字和没加入volatile时所产生的汇编代码,发现加入volatile时,会多出一个lock前缀指令,lock前缀指令相当于内存屏障,也不会把前面的放在内存屏障之后,即在执行到内存屏障这句时,前面的操作都完成。他会强制将对缓存的修改立即写入主存。若是写操作,会导致其他cpu中对应的缓存行无效。 线程的状态:在任意一个时间点,一个线程有且只有一种状态。 新建:创建后尚未启动。 运行:包括了OS中的running和ready状态,也就是处于此状态的线程可能正在运行,也可能正在等待cpu为它分配执行时间。 无限期等待:处于这种状态的线程不会被分配cpu执行时间,要等待其他线程显式唤醒。以下方法会让线程进入无限期等待:没有设置timeout的object.wait()方法;没有设置timeout参数的thread.join()方法;locksupport.park()。 有限期等待:处于这种状态的线程不会被分配cpu执行时间,不过无需等待其他线程显式唤醒,而是在一定的时间后他们会由os自动唤醒。设置了timeout的object.wait();设置了timeout的thread.join();locksupport.parknanos();locksupport.parkunit()。 阻塞:线程被阻塞与等待状态的区别是:阻塞状态在等待获取一个排他锁,这个事件将在另一个线程放弃这个锁的时候发生。等待状态在等待一段时间或者唤醒动作。 结束:已终止线程的状态。 java中的线程由一个处理虚拟机、cpu执行的代码及代码操作的数据三部分组成。 锁有一个专门的名字:对象监视器。当多个线程同时请求某个锁时,则锁会设置几种状态来区分请求的线程:connection list所有请求锁的线程将首先被放置到该竞争队列中;entry list那些有资格成为候选人的线程被移到entry list;wait list那些调用wait方法被阻塞的线程放置到wait set中。 Synchronized作用:Synchronized是Java中解决并发问题的一种最常用的方法,也是最简单的一种方法。Synchronized的作用主要有三个:确保线程互斥的访问同步代码。保证共享变量的修改能够及时可见。有效解决重排序问题。Synchronized总共有三种用法:修饰普通方法。修饰静态方法。修饰代码块。 synchronized和lock区别 lock是接口,synchronized是关键字,是重量级同步机制。 synchronized在发生异常时,会自动释放所有线程的锁,不会发生死锁。lock在发生异常时,若没有主动通过unlock()释放锁,则很有可能死锁,所以用lock时要在finally中释放锁。 lock可以让等待锁的线程响应中断,而synchronized不行,使用synchronized时,等待的线程会一直等待下去,不能响应中断。 通过lock可以知道是否成功获得锁,而synchronized不可以。 lock可以提高多个线程进行读写操作的效率。 同步代码块是使用monitorenter和monitorexit指令实现的,同步方法(在这看不出来需要看JVM底层实现)依靠的是方法修饰符上的ACC_SYNCHRONIZED实现。同步代码块:monitorenter指令插入到同步代码块的开始位置,monitorexit指令插入到同步代码块的结束位置,JVM需要保证每一个monitorenter都有一个monitorexit与之相对应。任何对象都有一个monitor与之相关联,当且一个monitor被持有之后,他将处于锁定状态。线程执行到monitorenter指令时,将会尝试获取对象所对应的monitor所有权,即尝试获取对象的锁; synchronized同步方法:依靠的是方法修饰符上的ACC_SYNCHRONIZED实现。synchronized方法会被翻译为普通的方法调用和返回指令,比如invokevirtual指令,在jvm字节码层面并没有任何特别的指令来实现synchronized修饰的方法,而是在class文件的方法中将该方法的access_flags字段中的synchronized标志位置为1,表示该方法为synchronized方法,且调用该方法的对象或者该方法所属的class在jvm内部对象表示最为锁对象。 虚拟机可以从方法表acc_synchronized访问标志得知一个方法是否为同步方法。当方法调用时,调用指令会将检查方法的acc_synchronized访问标志是否被设置了。若被设置了,执行线程就要求先成功持有moniter,然后才能执行方法,最后当方法完成(无论是正常还是非正常完成)时释放moniter。在方法执行期间,执行线程持有了moniter,其他任何线程都无法再获得同一个moniter,若一个同步方法执行期间出了异常,并且在方法内部无法处理此异常,那么这个moniter将在异常执行到同步方法之外时自动释放。 在java设计中,每个对象自打出现就带了一把看不见的锁,即monitor锁。monitor是线程私有的数据结构,每个线程都会有一个可用的monitor record列表,同时还有一个全局可用的列表。每个被锁住的对象都会和一个monitor关联。monitor中有一个owner字段存放拥有该对象线程的唯一标识,表示该锁由这个线程占用。owner:初始时为null,表示当前没有任何线程拥有该monitor record,当线程成功拥有该锁后保存线程的唯一标识,当锁被释放时,又被设为null。entry Q:关联一个系统互斥锁,阻塞所有试图锁住monitor entry失败的线程。next:用来实现重入锁的计数。 锁主要有4种状态:无锁状态、偏向状态、轻量级状态、重量级状态。他们会随着竞争的激烈而逐渐升级,锁可以升级但不可以降级。 synchronized用的锁是存在java对象头里。对象头包含标记字段和类型指针。类型指针是对象指向他类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。标记字段用于存储对象自身运行时的数据,他是轻量级锁和偏向锁的关键。 lock底层实现,可重入锁:同一线程,外层函数获得锁之后,内层递归函数仍有获得锁的机会但不受影响。synchronized和reentrantlock都是可重入锁。 可重入锁:若某个线程试图获取一个已经由他自己持有的锁,那么这个请求会成功。实现方式:为每个锁关联一个获取计数器和一个所有者线程。当计数器为0时,这个锁就被认为是没有被任何线程持有,当线程请求一个未被持有的锁时,将计数器设为1。若同一个线程在此获取这个锁,计数器递增,而当前线程退出同步代码块时,计数器会相应递减,为0时,会释放锁。 所有可重入代码都是线程安全的,但并非所有线程安全的代码都可重入。 synchronized与Reentrantlock的区别: Synchronized是JVM层面实现的,通过moniterenter和moniterexit自动的获取锁,然后在线程执行结束或者发生异常的时候释放锁,而ReentrantLock是对象,Java层面,需要显式的获取锁和显示的释放锁,但因为ReentrantLock是Java层面的锁,所以在程序员的角度来说,ReentrantLock更加灵活。 Synchronized和ReentrantLock都是可重入锁,Synchronized不公平的,下次获取锁的线程是操作系统在阻塞队列中随意选取的,而ReentrantLock可以通过参数来设置为公平锁或者非公平锁。 ReentrantLock可以获取锁的状态,并且是可以中断的,而Synchronized不可以获取,并且是不可中断锁。 在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时ReentrantLock的性能要远远优于synchronized。所以说,在具体使用时要根据适当情况选择。 Reentrantlock可以提高多个线程的读效率。 在Synchronized优化以前,synchronized的性能是比ReenTrantLock差很多的,但是自从Synchronized引入了偏向锁,轻量级锁(自旋锁)后,两者的性能就差不多了,在两种方法都可用的情况下,官方甚至建议使用synchronized,其实synchronized的优化我感觉就借鉴了ReenTrantLock中的CAS技术。都是试图在用户态就把加锁问题解决,避免进入内核态的线程阻塞。 ReenTrantLock独有的能力: ReenTrantLock可以指定是公平锁还是非公平锁。而synchronized只能是非公平锁。所谓的公平锁就是先等待的线程先获得锁。 ReenTrantLock提供了一个Condition(条件)类,用来实现分组唤醒需要唤醒的线程们,而不是像synchronized要么随机唤醒一个线程要么唤醒全部线程。 ReenTrantLock提供了一种能够中断等待锁的线程的机制,通过lock.lockInterruptibly()来实现这个机制。 如果多个线程访问同一个可变状态的变量时,没有使用合适的同步,那么程序就会出问题。由三种方法可以修复这个问题:不在线程中间共享变量;变量改为不可变;使用同步。 竟态条件:由于不恰当的执行顺序而不正确的结果。本质:基于一种可能失效的观察结果来做出判断。先检查后执行:首先观察某个条件为真(例如每个文件x不存在),然后根据这个观察结果采取相应的动作(创建文件x),但事实上,你观察到这个结果以及开始创建文件之前,观察结果可能变得无效(另一个线程在此期间创建了x),从而导致各种问题。要保持状态的一致性,就需要在单个原子操作中更新所有相关的状态变量。 同步阻塞,用户空间的应用程序执行一个系统调用,这意味着应用程序会一直阻塞,直到系统调用用完为止(数据传输完成或者发生错误)。一个连接一个线程,适用于链接数量小且固定的架构。同步非阻塞,设备以非阻塞形式打开,这意味着io操作不会立即完成,需要应用程序调用多次来等待完成。一个请求一个线程,客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到链接有io请求时才启动一个线程进行处理,实用链接比较多,比较短。异步非阻塞,一个有效请求一个线程,适用于链接数目多且长。 同步:发出一个调用时,没有得到结果前,调用就不返回,一旦返回就有结果。异步:调用在发生之后就直接返回,所以没有返回结果,换句话说,当一个异步调用发生后,调用者不会立即得到结果,而是在调用发生之后,被调用者通过状态通知来通知调用者,或者通过回调函数来处理这个调用。 condition的await()和single()与object的wait()和notify()类似。wait()抛出interceptedException。 semaphore:用来控制同时访问某个特定资源的操作数量。用acquire获取一个许可,若没有则等待。用release释放一个许可。但信号量semaphore可实现互斥。对于锁来说,是互斥的排他的,而对于somaphore来说,它允许多个线程同时进入临界区,可认为他是一个共享锁,但是共享的额度有限,额度用完了,其他没有拿到额度的线程还是要阻塞在临界区外,当额度为1时,相当于lock。 private final Semaphore semaphore; semaphore = new Semaphore(3); semaphore.acquire(); semaphore.release(); 共享锁和排他锁:共享锁又称读锁,若事务T对事务对象A加了S锁,则事务T可以读A但不能修改A,其他事务只能对他加S锁,不能加X锁,直达T释放A上的S锁。这保证了其他事务可以读A,但在事T释放S锁之前,不能对A做任何操作。排他锁又称写锁,若事务T对数据对象加X锁,事务T既可以读A也可以修改A,其他事务不能对A加任何锁,直到T释放A上的锁。这保证了,其他事务在T释放A上的锁之前不能再读取和修改A。 readwritelock:读读不互斥,读写互斥,写写互斥,并发性能提高。 countdownlatch:倒数计数器,一种典型的场景就是火箭发射,在火箭发射前,往往还要进行各项设备仪器的检查,只有等所有检查完成后,引擎才能点火,这种场景就非常适合使用countdownlatch,它可以使点火线程使得所有检查线程全部完工后,再执行。 countdownlatch是一种灵活的闭锁实现,可以使一个或多个线程等待一组时间发生,事件全部发生后阻塞的才能继续执行。闭锁状态包括一个计数器,该计数器被初始化为一个正数,表示要等待是事情发生。countdown方法递减计数器,表示有一个事件已经发生,而await方法等待计数器变为0,表示所有需要等待的事件都发生。当计数器为0时,await上等待的线程可以继续执行。countdownlatch构造函数传入的值就是计数器的初始值,且只可被设置一次。 countdownlatch计数只能用1次。一个或多个线程等待其他线程完成后再执行。cylicbarrier计数可用多次。所有线程互相等待完成。 cyclicbarrier:模拟高并发,初始化时规定一个数目,然后计算调用了cyclicbarrier.await()进入等待的线程数,当线程数达到这个数目时,所有进入等待的线程将被唤醒并继续。cyclic就像名字一样,可看成是一个屏障,所有线程必须达到后才可以一起通过这个屏障。 并发包:Executor, ExecutorService, AbstractExecutorService, ThreadPoolExecutor。copyOnWriteArrayList, copyOnWriteSet。BlockingQueue。CycleBarrier, countDownLatch, Semaphore。Future, callable。lock。 cpu为了提高程序运行效率,可能对输入代码进行优化,它不保证程序中各语句的执行顺序同代码中顺序一致,但保证程序最终执行结果和代码执行顺序一致。cpu在进行重排序时,会考虑指令之间的依赖性,若一个指令instruction2必须用到instruction1的结果,则cpu保证1在2之前执行。指令重排序不影响单个线程,但是影响线程并发执行的正确性。 x = 10; x = y; x++; x = x + 1; 只有第一个是原子的。 blockingqueue:ArrayBlockingQueue一个由数组实现的有界阻塞队列,其构造函数必须带一个int函数,来指明其大小。其所含的对象是由fifo顺序排列的。linkedblockingqueue:大小不一定,若构造函数传入int,则blockingqueue有大小限制,否则大小为integer.max_value,其所包含的对象是FIFO顺序。 priorityblockingqueue:类似于linkedblockingqueue,但不是fifo,而是自然顺序或比较器的顺序。 synchronizedqueue:对其的操作必须是放取交替完成。 乐观锁和悲观锁 悲观锁:就是很悲观,每次去拿数据的时候都认为别人会修改,所以每次拿数据的时候都会上锁。这样别人想拿这个数据就会阻塞直到它拿到锁。传统的关系型数据库就用到了很多这种机制,比如行锁,写锁等,都是在操作之前上锁。 乐观锁:就是很乐观,每次去拿数据时都认为别人不会修改,所以不会上锁,但在更新的时候会判断一下在此期间别人有没有去更新这个数据。适用于多读,比如write_condition。各有优缺点:不能认为一种比另一种好。 悲观锁在大多数情况下,依靠数据库的锁机制。乐观锁大多基于数据版本,记录机制实现。数据版本:为数据增加一个版本标识,比如增加一个version字段。读数据时,将版本号一块读出,之后更新时,版本号加1,将提交数据的版本号与数据库表对应记录的版本号进行对比。若提交的大于数据库里的,则可以更新,否则认为是过期数据。将乐观锁策略在存储工程中实现,对外值开放基于此存储过程的数据更新途径,而不是将数据表直接对外公开。 runnable的run方法没有返回值,并且可以不抛出异常。 callable的call方法有返回值,并且可以抛出异常,且返回值可以被future接收。 future是一个接口。futuretask是他的一个实现类,可通过futuretask的get方法得到返回值。 future对象表示异步计算的结果,他提供了检查计算是否完成的方法,以等待计算的完成,并获取计算的结果。计算完成后只能使用get方法来获取结果,若没有执行完,get方法可能会被阻塞,直到线程执行完。取消由cancel方法执行。isDone确定任务是正常执行还是被取消。一旦计算完成了,就不能再取消了。 start()和run():start()方法启动线程,真正实现多线程运行,通过调用thread类的start方法来启动一个线程,这时线程处于就绪状态,并没运行,若cpu调度该线程,则该线程就执行run方法;run方法当作普通方法的方式调用,程序要顺序执行,要等run方法执行完毕,才能执行下面的代码,程序中只有主线程这一个线程(除了gc线程)。 Handler一般用来接收Message和发送Message 接收Message: 或者: 发送消息: handler.sendEmptyMessage(1); 或(需要携带内容的): Message message = new Message(); message.what = 1; message.obj = "haha"; handler.sendMessage(message); 或(所得到的Message是从消息队列中获取,避免了new Message的内存开销,其源码中也是执行了target.sendMessage()方法,target就是handler): Message m = handler.obtainMessage(1,2,3,"quan"); m.sendToTarget(); 在子线程中接收消息,我们要用到Looper,主线程不用,因为主线程已经默认使用Looper了,我们会使用looper的两个主要方法,一个是prepare和loop,前一个是创建Looper对象,后一个是执行Looper循环功能。 然后我们使用这个自定义的Looper线程 new LoopThread().start(); 创建线程3种方式:继承Thread类创建线程;实现Runnable接口创建线程;使用Callable和Future创建线程。 实现Runnable接口比继承Thread类所具有的优势:适合多个相同的程序代码的线程去处理同一个资源;可以避免java中的单继承的限制;增加程序的健壮性,代码可以被多个线程共享,代码和数据独立。 Java线程间通信 通过共享对象通信:线程间发送信号的一个简单方式是在共享对象的变量里设置信号值。线程A在一个同步块里设置boolean型成员变量hasDataToProcess为true,线程B也在同步块里读取hasDataToProcess这个成员变量。 忙等待(Busy Wait):准备处理数据的线程B正在等待数据变为可用。换句话说,它在等待线程A的一个信号,这个信号使hasDataToProcess()返回true。线程B运行在一个循环里,以等待这个信号。 wait(),notify()和notifyAll():一个线程一旦调用了任意对象的wait()方法,就会变为非运行状态,直到另一个线程调用了同一个对象的notify()方法。为了调用wait()或者notify(),线程必须先获得那个对象的锁。也就是说,线程必须在同步块里调用wait()或者notify()。这三个方法用于协调多个线程对共享数据的存取,所以必须在同步语句块内使用。wait方法要等待notify/notifyAll的线程释放锁后才能开始继续往下执行。 

FuturetaskHandler handler = new Handler(new Handler.Callback() {
int position;
@Override
public boolean handleMessage(Message msg) {
switch (msg.what) {
case 1:
// 执行接收Message后的逻辑
break;
}
return true;
}
});Handler handler = new Handler() {
@Override
public void handleMessage(Message msg) {
super.handleMessage(msg);
//执行逻辑
}
};public Handler handler1;
public class LoopThread extends Thread {
@Override
public void run() {
Looper.prepare();
handler1 = new Handler() {
@Override
public void handleMessage(Message msg) {
switch (msg.what) {
case 1:
Toast.makeText(getApplication(), msg.obj + "," + msg.arg1 + "," + msg.arg2 + " ",Toast.LENGTH_SHORT).show();
break;
}
}
};
Looper.loop();
}
}Thread t1 = new Thread() { // 第一种方式
@Override
public void run() {
System.out.println("new Thread 1"); // 输出:new Thread 1
}
}; // 创建线程
t1.start(); // 启动线程
System.out.println(t1.getName()); // 输出:Thread-0
Thread t2 = new Thread(new Runnable() { // 第二种方式
@Override
public void run() {
System.out.println("new Thread 2"); // 输出:new Thread 2
}
});
t2.start();
System.out.println(Thread.currentThread().getName()); // 输出:main
FutureTasksynchronized(lockObj) { // 等待方
while(condition is false) {
lockObj.wait();
}
// do business
}
synchronized(lockObj) { // 通知方
// change condition
lockObj.notifyAll();
}