10 道超级高频 Java 面试题,助力金三银四
简介
大家好,我是毛毛虫,也是公众号 Java dev 的作者,多年一线研发老兵,面试超过 200 人次,也算是在面试方面稍有经验,2019 年下半年的时候开始琢磨着如何把自己的一些知识点分享给初级的研发同学。
任何一个技术人都逃离不了技术面试一关,俗话说不打没有准备的仗,那么如何有效的准备呢,不陷入细节,又不能浅尝辄止,所以我决定在公众号上利用业余时间多多更新一些自己实际面试过程中会用到的面试题,陆陆续续已经分享了十几篇原创文章。
令人欣慰的是有读者留言告诉毛毛虫,说自己拿到了心仪的 offer,面试题目中有好几道题目都在毛毛虫的公众号里出现过,非常感谢。 介于公众号的扩散能力有限,毛毛虫将十几篇精华面试题目综合在一起,奉送给更多的同学,希望你们在 2020 年的金三银四大战中大放异彩。
问题 1
Java 在语法层面已经有了 synchronized 来实现管程,为什么还要在 JDK 中提供了 Lock 和 Condition 工具类来做这样的事情,这属于重复造轮子吗?
答案
首先你可能会想到的是 synchronized 性能问题,但是我想告诉你的是 synchronized 在高版本的 JDK 中性能已经得到了大幅的提升,很多开发者开始提倡使用 synchronized,性能问题可以不断优化提升,它并不是重载轮子的原因。
大家都知道管程帮助我们解决了多线程资源共享问题,但同时也带来了死锁的风险。Coffman 等人在 1971 年总结出来产生死锁的四个必要条件:
1.互斥条件
一个资源在同一时刻只能被一个线程操作。
2.占有且等待
线程因为请求资源而阻塞时不会释放已经获取到的资源。
3.不可强行占有
线程已经获取到的资源,在未释放前不允许被其他线程强行剥夺。
4.循环等待
线程存在循环等待资源的关系(线程 T1 依次占有资源 A,B;线程 T2 依次占有资源 B,A;这就构成了循环等待资源关系)。
当发生死锁的时候必然上面四个条件都会满足,那么只要我们破坏其中的任何一个条件,我们即可解决死锁问题。首先条件 1 无法破解,因为共享资源必须是互斥的,如果可以多个线程同时操作也没必要加锁了。那我们试图使用 synchronized 来破解剩余的三个条件:
1.占有且等待
synchronized 获取资源时候,只要资源获取不到,线程立即进入阻塞状态,并且不会释放已经获取的资源。那么我们可以调整一下获取共享资源的方式,我们通过一个锁中介,通过中介一次性获取线程需要的所有资源,如果存在单个资源不满足情况,直接阻塞,而不是获取部分资源,这样我们即可解决这个问题,破解该条件。
2.不可强行占有
synchronized 获取不到资源时候,线程直接阻塞,无法被中断释放资源,因此这个条件 synchronized 无法破解。
3.循环等待
循环等待是因为线程在竞争 2 个互斥资源时候会以不同的顺序去获取资源,如果我们将线程获取资源的顺序固定下来即可破解这个条件。
综上我们可以知道 synchronized 不能破解“不可强行占有”条件,这就是 JDK 同时提供 Lock 这种管程的实现方式的原因。当然啦,Lock 使用起来也更加的灵活。例如我们有多个共享资源,锁是嵌套方式获取的,如线程需要先获取 A 锁,然后获取 B 锁,然后释放 A 锁,获取 C 锁,接着释放 B 锁,获取 D 锁 等等。这种嵌套获取锁的方式 synchronized 是无法实现的,但是 Lock 却可以帮助我们来解决这个问题。既然我们知道了 JDK 重造管程的原因,那我们来一起看一下 Lock 为我们提供的四种进入获取锁的方式:
1.void lock();
这种方式获取不到锁时候线程会进入阻塞状态,和 synchronized 类似。
2.void lockInterruptibly() throws InterruptedException;
这种方式获取不到锁线程同样会进入阻塞,但是它可以接收中断信号,退出阻塞。
3.boolean tryLock();
这种方式不管是否能获取到锁都不会阻塞而是立刻返回获取结果,成功返回 true,失败返回 false。
4.boolean tryLock(long time, TimeUnit unit) throws InterruptedException;
这种方式获取不到锁的线程会进入阻塞状态,但是在指定的时间内如果仍未获得锁,则返回 false,否则返回 true。
问题 2
你已经知道管程 synchronized 是通过锁对象所关联的 Monitor 对象的计数来标识线程对锁的占有状态,那么你知道 ReentrantLock 是如何来控制锁的占有状态吗?
答案
Lock 锁采用了与 Monitor 对象计数完全不同的一种方式,它依赖了并发包中的 AbstractQueuedSynchronizer (队列同步器简称 AQS ) 来实现在多线程情况下对锁状态的控制。那么 AQS 是如何保证在多线程场景中锁状态可以正常控制呢,它主要使用了如下 3 个技术点:
1.volatile 关键字
首先 AQS 中定义了一个 volatile 修饰的 int 变量 state,大家都知道 volatile 是实现无锁编程的关键技术。它有内存可见性和禁止指令重排序的功效,当多个线程去争夺锁的占有权的时候,如果有其中任何一个线程已经持有锁,它会设置 state 加 1。这样由于 volatile 的可见性功效,其他线程会争取锁权限的时候发现锁已经被其他线程持有,就会进入等待队列。当持有锁的线程使用结束后,释放锁,会将 state 减 1,然后去唤醒队列中等待的线程。
2.CAS(compare and swap) 算法
你是否存在疑问,当线程将 state 加 1 的时候是如何保证只有一个线程在做这个操作呢,毕竟在加 1 操作的时候线程尚未获得锁,所以加 1 操作存在竞争关系。虽然 volatile 可以解决线程间的内存可见性问题,但是仍然存在多个线程竞争 state 更新的问题,这就要使用我们的 CAS 算法来解决这个问题了,compare and swap 中文意思是比较并且替换。它提供的功能是让我们提供一个预期值和一个即将要设置为的值,如果此时内存中的值正好是我们预期的值,则直接将值设置为我们即将要设置为的值。
拿竞争 state 举例,所有线程都希望 state 的值为 0 (0 代表没有线程占用),然后自己将 state 设置为 1(占有锁)。在 AQS 中 由如下方法来帮我完成这件事情:
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
你注意到了,该方法并不会直接帮我们完成这件事情而是一个 Unsafe 的对象完成了实际的操作,Unsafe 类提供了大量的原子方法,但是这些方法都是 native 标识的,代表它们是 JVM 提供的本地 C++ 方法,底层本质是对 CPU CAS 指令的一个封装。这样 volatile 的内存可见性特效结合 CAS 算法就完美的解决了多线程并发获取锁的安全操作。当然啦,Unsafe 正如其名,寓意为不安全,不推荐开发者直接使用,只是在 Java SDK 中使用到了。
3.双向队列
到此你是否还存在疑问,多个线程竞争锁,一个线程获取到了锁,那其他线程怎么办呢?其他线程其实同样进入了阻塞等待状态(此处也使用了 Unsafe 的 park 本地方法),与 synchronized 不同是,AQS 内部提供了一个双向队列(不然怎么叫队列同步器呢,哈哈),队列的节点定义如下:
static final class Node {
/**省略部分属性**/
volatile Node prev;
volatile Node next;
volatile Thread thread;
Node nextWaiter;
/**省略部分方法**/
}
每一个进入等待队列的线程都会被关联到一个 Node,所有等待的线程按照先后顺序会组成一个双向队列(组成队列的过程中同样使用到了 CAS 算法 和 volatile 特性,不然多线程并发的给队列结尾添加节点也会存在竞争问题),等待持有锁的线程释放锁后唤醒队列头部的节点中关联的线程(此处唤醒同样使用了 Unsafe 的 unpark 本地方法),这样就有序的控制了线程对共享数据的并发访问。
如上我们介绍了 Lock 锁中用到的三个重要技术点和基本实现原理,相信问题回答到这一步面试官已经默默心里想:小伙子有点东西啊。哈哈!
问题 3
HashMap 想必是平时工作中使用非常的频繁的数据结构了吧,它简单易用,同时也是面试扫盲第一轮技术面中出现频率极高的题目之一。假设我问你:HashMap 一次 put 操作的详细过程是怎样的,你可以对答如流吗?
我的答案
HashMap 的存储结构就不用多介绍了,底层是一个 列表/二叉树 的数组结构。当我们调用一次 put 操作的时候主要会经过如下 4 个大步骤,让我们来详细看一下这四个步骤都做了些什么事情。
1.求 Key 的 hash 值
想要存入 HashMap 的元素的 key 都必须要经过一个 hash 运算,首先调用 key 对象的 hashCode 方法获取到对象的 hash 值。然后将获得 hash 值向右位移 16 位,接着将位移后的值与原来的值做异或运算,即可获得到一个比较理想的 hash 值,之所以这样运算时为了尽可能降低 hash 碰撞(即使得元素均匀分布到各个槽中)。
2.确定 hash 槽
获取到 hash 值后就是计算该元素所对应的 hash 槽,这一步操作比较简单。直接将上一步操作中获取到的 hash 值与底层数组长度取模(为了提高性能,源码采用了运算,这样等价于取模运算,但是性能更好)获取 index 位置。
3.将元素放入槽中
在上一步中我们获得了 hash 槽的索引,接下来就是将元素放入到槽中,如果槽里当前没有任何元素则直接生成 Node 放入槽中,如果槽中已经有元素存在,则会有下面 2 种情况:
3.1 槽里是一颗平衡二叉树
当列表的元素长度超过 8 时,为了加快槽上元素的索引速度,HashMap 会将列表转换为平衡二叉树。所以在这种情况下,插入元素是在一颗平衡二叉树上做操作,查找和更新的时间复杂度都是 log(n),HashMap 会将元素包装为一个 TreeNode 添加到树上。具体平衡二叉树的操作就不在此展开了,有兴趣的小伙伴可自行探索。
3.2 槽里是一个列表
初始情况下,槽里面的元素是以列表形式存在的,HashMap 遍历列表将元素 更新 / 追加 到列表尾部。元素添加后,HashMap 会判断当前列表元素个数,如达到 8 个元素则将列表转化为平衡二叉树,具体转换详情可参考 HashMap 中的方法 final void treeifyBin(Node 。
4.扩容
到这里时候,我们元素已经完美的放到了 HashMap 的存储中。但是还有一个 HashMap 的自动扩容操作需要完成,默认情况下自动扩容因子是 0.75,即当容量为 16 时候,如果存储元素达到 16 * 0.75 = 12 个的时候,HashMap 会进行 resize 操作(俗称 rehash)。HashMap 会新建一个 2 倍容量与旧数组的数组,然后依次遍历旧的数组中的每个元素,将它们转移到新的数组当中。其中有 2 个需要注意的点:列表中元素依然会保持原来的顺序和加入二叉树上的元素少达 6 个时候会将二叉树再次转化为列表来存储。
如上我们介绍了 HashMap 的依次 put 操作的全过程,小伙伴们快去看源码巩固一下吧,欢迎留言与我交流哦。
问题 4
ConcurrentHashMap 在我们平时编码的过程中不是很常用,但是它在 Java 基础面试中是也是一道必考题,通常会拿出来和 HashMap 做比较,所以我们必须要掌握它。那么,你知道 ConcurrentHashMap 是如何来实现一个支持并发读写的高效哈希表呢?
我的答案
ConcurrentHashMap 同 HashMap 一样,都是 Map 接口的子类。不同之处在于 HashMap 是非线程安全的,如果想要在多线程环境下使用必须对它的操作添加互斥锁。而 ConcurrentHashMap 为并发而生,可以在多线程环境下随便使用而不用开发人员去添加互斥锁。那么 ConcurrentHashMap 是如何实现线程安全的特性呢,接下来我们就从它的 put 方法说开来,对比 HashMap 的 put 操作来一步步揭开它的神秘面纱。
1.获取哈希值
同 HashMap 一样,ConcurrentHashMap 底层也是使用一个 Node 的数组来存储数据。因此第一步也是获取要存储元素的哈希值。与 HashMap 不同的是,ConcurrentHashMap 不支持 null 键和 null 值。
2.确定 hash 槽
这一步就不多说了,同 HashMap 基本一致。
3.初始化底层数组存储
拿到 hash 槽以后就是存储元素,但是首次 put 元素时候会触发初始化底层数组操作,在 HashMap 中这一步操作是很简单的,因为是单线程操作直接初始化就可以了。但是在 ConcurrentHashMap 中就需要考虑并发问题了,因为有可能有多个线程同时 put 元素。这里就用到了我们之前文章中介绍的无锁编程利器 volatile 和 CAS 原子操作。每个线程初始化数组之前都会先获取到 volatile 修饰的 sizeCtl 变量,只有设置了这个变量的值才可以初始化数组,同时数组也是由 volatile 修饰的,以便修改后能被其他线程及时察觉。不知道 volatile 和 CAS 算法的同学可以参考往期的文章 ReentranLock 实现原理居然是这样?。具体初始化代码可参考 ConcurrentHashMap 的 initTable 方法。
3.插入元素
数组初始化结束后就可以开心的插入元素了,插入数组元素又分了如下 3 个情况:
3.1 当前槽中没有元素
这种情况最为简单,直接调用 Unsafe 封装好的 CAS 方法插入设置元素即可,成功则罢,不成功的话会转变为下个情况。
3.2 槽中已有元素
操作已有元素也有 2 个情况:
3.2.1 槽中元素正在被迁移(ConcurrentHashMap 扩容操作)
如果当前槽的元素正在被扩容到新的数组当中,那么当前线程要帮忙迁移扩容。
3.2.3 槽中元素处于普通状态
这个时候就是和 HashMap 类似的 put 操作,特殊之处在于 ConcurrentHashMap 需要在此处加锁,因为可能当前有多个线程都想往这个槽上添加元素。这里使用的 synchronized 锁,锁对象为当前槽的第一个元素。锁住以后的操作就和 HashMap 类似了,如果槽中依然是列表形态,那么将当前元素包装为 Node 添加到队列尾部,插入元素结束后如果发现列表元素达到了 8, 则会将列表转换为二叉树(注意:插入元素后会释放锁,若发现要转换为二叉树,则会重新进行加锁操作)。如果槽中元素已经转换为了平衡二叉树,那么将元素封装为 TreeNode 插入到树中。
4.扩容
在插入元素的末尾,ConcurrentHashMap 会计算当前容器内的元素,然后决定是否需要扩容。扩容这一部分涉及到了比较复杂的运算,后面我们会单独出一遍文章来探讨分析,敬请关注。
至此相信你已经对 ConcurrentHashMap 可以支持并发的原理有了大致的了解,它主要依靠了 volatile 和 CAS 操作,再加上 synchronized 即实现了一个支持并发的哈希表。了解了以上的内容和我们后面将要讨论的扩容话题基本可以对付面试了,当然啦 ConcurrentHashMap 的源码复杂程度远远高于 HashMap,对源码有兴趣的同学可以继续努力啃一啃,相信肯定会有更大的收获。
问题 5
相信你一定记得学习并发编程的一个入门级例子,多个线程操作一个变量,累加 10000 次,最后结果居然不是 10000。后来你把这个变量换成了并发包中的原子类型变量 AtomicLong,完美的解决了并发问题。假如面试官问:还有更好的选择吗?LongAdder 了解过吗?你能对答如流吗?
我的答案
AtomicLong 是 Java 1.5 并发包中提供的一个原子类,他提供给了我们在多线程环境下安全的并发操作一个整数的特性。并且性能还可以,它主要依赖了 2 个技术,volatile 关键字和 CAS 原子指令,不知道这俩个技术的小伙伴参考往期的文章:ReentranLock 实现原理居然是这样?;AtomicLong 性能已经不错了,但是当在线程高度竞争的状况下性能会急剧下降,因为高度竞争下 CAS 操作会耗费大量的失败计算,因为当一个线程去更新变量时候发现值早已经被其他线程更新了。那么有没有更好的解决方案呢,于是 LongAdder 诞生了。
LongAdder 是 Java 1.8 并发包中提供的一个工具类,它采用了一个分散热点数据的思路。简单来说,Atomic 中所有线程都去更新内存中的一个变量,而 LongAdder 中会有一个 Cell 类型的数组,这个数组的长度是 CPU 的核心数,因为一台电脑中最多同时会有 CPU 核心数个线程并行运行,每个线程更新数据时候会被映射到一个 Cell 元素去更新,这样就将原本一个热点的数据,分散成了多个数据,降低了热点,这样也就减少了线程的竞争程度,同时也就提高了更新的效率。当然这样也带了一个问题,就是更新函数不会返回更新后的值,而 AtomicLong 的更新方法会返回更新后的结果,LongAdder 只有在调用 sum 方法的时候才会去累加每个 Cell 中的数据,然后返回结果。当然 LongAdder 中也用到了 volatile 和 CAS 原子操作,所以小伙伴们一定要掌握这俩个技术点,这是面试必问的点。
既然说 LongAdder 的效率更好,那我们就来一段测试代码,小小展示一下 LongAdder 的腻害之处,请看如下:
public class AtomicLongTester {
private static AtomicLong numA = new AtomicLong(0);
private static LongAdder numB = new LongAdder();
public static void main(String[] args) throws InterruptedException {
for (int i = 1; i < 10001; i*=10) {
test(false, i);
test(true, i);
}
}
public static void test(boolean isLongAdder, int threadCount) throws InterruptedException {
long starTime = System.currentTimeMillis();
final CountDownLatch latch = new CountDownLatch(threadCount);
for (int i = 0; i < threadCount; i++) {
new Thread(new Runnable() {
public void run() {
for (int i = 0; i < 100000; i++) {
if (isLongAdder) {
numB.add(1);
} else {
numA.addAndGet(1);
}
}
latch.countDown();
}
}).start();
}
// 等待所有运算结束
latch.await();
if (isLongAdder) {
System.out.println("Thread Count=" + threadCount + ", LongAdder cost ms=" + (System.currentTimeMillis() - starTime) + ", Result=" + numB.sum());
} else {
System.out.println("Thread Count=" + threadCount + ", AtomicLong cost ms=" + (System.currentTimeMillis() - starTime) + ", Result=" + numA.get());
}
numA = new AtomicLong(0);
numB = new LongAdder();
}
}
实验结果大致如下:
Thread Count=1, AtomicLong cost ms=9, Result=100000
Thread Count=1, LongAdder cost ms=13, Result=100000
Thread Count=10, AtomicLong cost ms=14, Result=1000000
Thread Count=10, LongAdder cost ms=41, Result=1000000
Thread Count=100, AtomicLong cost ms=111, Result=10000000
Thread Count=100, LongAdder cost ms=45, Result=10000000
Thread Count=1000, AtomicLong cost ms=1456, Result=100000000
Thread Count=1000, LongAdder cost ms=379, Result=100000000
Thread Count=10000, AtomicLong cost ms=17452, Result=1000000000
Thread Count=10000, LongAdder cost ms=3545, Result=1000000000
从上面的结果可以看出来,当线程竞争率比较低的时候 AtomicLong 效率还是优于 LongAdder 的,但是当线程竞争率增大的时候,我们可以看出来 LongAdder 的性能远远高于 AtomicLong。
因此在使用原子类的时候,我们要结合实际情况,如果竞争率很高,那么建议使用 LongAdder 来替代 AtomicLong。说到 LongAdder 也不得的说一说 volatile 带来的伪共享问题,对伪共享感兴趣的同学欢迎关注后续的文章,我们会在后续的文章中探讨这个问题。
以上即为 公众号:Java dev 昨天的问题的答案,小伙伴们对这个答案是否满意呢?欢迎留言和我讨论。
问题 6
往期问题中,我们介绍了 LongAdder 工具类。我们知道了 LongAdder 中为了分散热点数据,存在一个 volatile 修饰的 Cell 数组。由于数组的连续存储特性,会存在伪共享问题,你知道 LongAdder 是如何解决的吗?
我的答案
在探讨 LongAdder 是如何解决伪共享问题之前,我们要先梳理清一个概念,什么是 伪共享 和 共享 ?
共享在 Java 编程里面我们可以这样理解,有一个 Share 类,它有一个 value 的属性。如下:
public class Share { int value;}
我们初始化 Share 的一个实例,然后启动多个线程去操作它的 value 属性,此时的 Share 变量被多个线程操作的这种情况我们称之为 共享。
大家都知道在不添加任何互斥措施的情况,多线程操作这个 Share 变量的 value 属性肯定存在线程安全性的问题。那有什么办法可以解决这个问题呢?我们可以使用 volatile 和 CAS 技术来保证共享变量可以安全的被多个线程共享操作使用,不知道 volatile 和 CAS 技术点的同学可以参考往期文章 ReentranLock 实现原理居然是这样?。
但是由于 volatile 的引入,会带来一些问题。大家都知道 JMM(Java 内存模型)规范了 volatile 具有内存可见性和禁止指令重排序的语义。这俩条语义使得某个线程更新本地缓存中的 value 值后会将其他线程的本地缓存中的 value 值失效,然后其他线程再次读取 value 值的时候需要去主存里面获取 value 值,这样即保证了 value 的内存可见性。
当然啦,这没有任何问题,但是由于线程本地缓存的操作是以缓存行为单位的,一个缓存行大小通常为 64B(不同型号的电脑缓存行大小会有不同)。因此一个缓存行中不会只单单存储 value 一个变量,可能还会存储其他变量。这样当一个线程更新了 value 之后,如果其他线程本地缓存中同样缓存了 value, value 所在的缓存行就会失效,这意味着该缓存行上的其他变量也会失效,那么线程对这个该缓存行上所有变量的访问都需要从主存中获取。我们都知道 CPU 访问主存的速度相对于访问缓存的速度有着数量级的差距,这就带了很大的性能问题,我们将这个问题称之为 伪共享。
理解了伪共享到底是什么鬼以后,我们来看看 Java 大师们是怎么解决这个问题的。在早期版本的 JDK 里面你应该见到过类似如下的代码:
public class Share {
volatile int value;
long p1, p2, p3, p4, p5, p6;
}
你可能猜到了,定义了几个无用的变量作为填充物,他们会保证一个缓存行里面只保存了 Share 变量,这样更新 Share 变量的时候就不会存在伪共享问题了。但是这种方法存在什么问题呢?
首先基于每台运行 Java 程序的机器的缓存行大小可能不同,其次由于这些类似填充物的变量并没有被实际使用,可以被 JVM 优化掉,这样就失效了。
基于此,在 Java 8 的时候,官方给出了解决策略,这就是 Contended 注解。依赖于这个注解,我们在 Java 8 环境下可以这样改善代码:
public class Share {
@Contended
volatile int value;
}
使用如上注解,并且在 JVM 启动参数中加入 -XX:-RestrictContended,这样 JVM 在运行时就会自动的为我们的 Share 类添加合适大小的填充物(padding)来解决伪共享问题,而不需要我们手写变量来作为填充物了,这样就更加便捷优雅的解决了伪共享问题。悄悄的告诉你,LongAdder 就是使用 Contended 来解决伪共享问题哒。
好了,相信你已经了解了什么是伪共享问题,以及早期并发编程大师是如何解决伪共享问题的,最后我们也介绍了在 Java 8 中使用 Contended 来更优雅的解决伪共享问题。Contended 还提供了一个缓存行分组的功能,在上文中我们没有介绍,欢迎有兴趣的小伙伴们自行探索吧(嘿嘿)。
问题 7
少年,老衲看你骨骼清奇,眉宇之间透露着一股王者的气息。来吧,跟我讲讲 ConcurrentHashMap 是如何进行管理它的容量的,也就是当我们调用它的 size 方法的时候发生了什么故事?(前面我们介绍了 ConcurrentHashMap 的实现原理,但是扩容和容量大小留了个小尾巴,今天来割一下这个小尾巴,嘿嘿)
我的答案
毕竟是要支持并发,ConcurrentHashMap 的扩容操作比较复杂,我们将从以下几点来带讨论一下它的扩容。
触发扩容
1.添加新元素后,元素个数达到扩容阈值触发扩容。
2.调用 putAll 方法,发现容量不足以容纳所有元素时候触发扩容。
3.某个槽内的链表长度达到 8,但是数组长度小于 64 时候触发扩容。
统计元素个数
触发后面 2 点没啥问题,但是第 1 点中有个小问题,它是如何统计元素的个数呢?它采用和 LongAdder 类似的分散热点数据的解决思路,不知道 LongAdder 的小伙伴可以参考往期文章 还在用 AtomicLong?是时候了解一下 LongAdder 了。ConcurrentHashMap 内部定义了一个 CounterCell 的类,它同样被 Contended 修饰防止 volatile 带来的伪共享问题,伪共享不了解可以参考往期文章 面试官问我 volatile 是否存在伪共享问题?我懵逼了。内部实例化了一个 CounterCell 的数组来记录元素的个数,每当线程 put 一个元素到容器中,线程会被映射到一个 CounterCell 的一个元素上面采用 CAS 算法进行加 1 操作,当然如果当前 CounterCell 上已经有线程在操作,或者并发量比较小的话会直接将加 1 累加到 BASECOUNT 上面。
就是依据这样的策略,容器的元素的个数就会游刃有余的计算出来,当需要获取当前容器元素个数的时候,直接将 CounterCell 数据的每个元素值加起来再加上 BASECOUNT 的值就是当前容器中的元素个数。
扩容
上面我们知道了触发扩容的条件为元素个数达到阈值开始扩容,然后也知道了它是如何统计元素的个数的,接下来就看看扩容的运行机制。
首先每个线程承担不小于 16 个槽中的元素的扩容,然后从右向左划分 16 个槽给当前线程去迁移,每当开始迁移一个槽中的元素的时候,线程会锁住当前槽中列表的头元素,假设这时候正好有 get 请求过来会仍旧在旧的列表中访问,如果是插入、修改、删除、合并、compute 等操作时遇到 ForwardingNode,当前线程会加入扩容大军帮忙一起扩容,扩容结束后再做元素的更新操作。
总结
总结一下,对于 ConcurrentHashMap 的扩容我们需要明确如上三点就可以了,扩容触发的时机、元素个数的计算以及具体扩容过程中是如何坚持对外提供服务的就可以了。
如上即为 ConcurrentHashMap 扩容操作的简单介绍,实际 JDK 里面的扩容源码非常复杂,如果有小伙伴对源码感兴趣的话,本毛毛虫找到一篇不错的源码分析文章大家可以参考一下 https://blog.csdn.net/ZOKEKAI/article/details/90051567 。这篇相当于 ConcurrentHashMap 的续集,对前序感兴趣的可以参考往期文章 ConcurrentHashMap 并发读写,用了什么黑科技。
以上即为昨天的问题的答案,小伙伴们对这个答案是否满意呢?欢迎留言和我讨论。
问题 8
你用过 Java 中的 final 关键字吗?它有哪些作用?这也是出镜率极高的题目哦。
我的答案
1.final 修饰类的时候代表这个类是不可以被扩展继承的,例如 JDK 里面的 String 类。
2.final 修饰方法的时候代表这个方法不能被子类重写。
3.final 修饰变量的时候代表这个变量一旦被赋值就不能再次被赋值。
想必上面这三点是大家所熟知的,但是下面这 2 点你想到了吗?
缓存
final 变量会被缓存在寄存器中而不需要去主从获取,而非 final 变量的则需要去主存重新加载。
线程可见性
类的 final 域在编译器层面会保证在类的构造器结束之前一定要初始化完成,同时 Java 内存模型会保证对象实例化后它的 final 域对其他线程是可见的,然而非 final 域并没有这种待遇。例如如下代码:
public class FinalFiled {
final int x; int y;
static FinalFiled f;
public FinalFiled() {
x = 100;
y = 100;
}
static void writer() {
f = new FinalFiled();
}
static void reader() {
if (f != null) {
int i = f.x;
// 保证此时一定是 100
int j = f.y;
// 有可能此时还是 0
}
}
}
当线程 A 执行了 writer 方法后,有线程 B 会进入 f != null 成立条件的代码块,此时由于变量 x 是 final 修饰的,JMM 会保证 x 此时的值一定是 100,而 y 是非 final 的,则有可能此时 y 的值还是 0,并未被初始化。
安全性
String 类的安全性也得益于恰到好处的使用了大量的 final 域,大家可以去翻翻 String 类的源码。我们来举个例子,假设有线程 A 执行如下代码段:
Global.flag = "/001/002".substring(4);
又有线程 B 执行如下代码段:
String myS = Global.flag;
if (myS.equals("/001"))
System.out.println(myS);
如果没有 final 域的可见性保证,那么线程 B 在执行的时候有可能看到的字符串的长度可能仍然是 0。当有了 final 域的可见性保证,就可以让并发程序正确的执行。也使得 String 类成为名副其实不可变安全类。
问题 9
利用 Java 中的动态绑定我们可以实现很多有意思的玩法。例如
Object obj = new String();
集合类想必是小伙伴们低头不见抬头见的类了,那么你有没有想过集合类是否可以这样玩?
List不瞒你说,这是毛毛虫在一次面试中遇到的真实的面试题,当时被问的一脸懵。 如果是你,你知道怎么回答吗?
我的答案
首先我要告诉你的是,Java 集合类不允许这么玩,这样编译器会直接报错编译不通过。
我们都知道赋值一定需要是 is a 的关系,虽然 Object 和 Integer 是父子关系,但是很可惜 List 和 new ArrayList 不是父子关系。当你这么回答时候,面试官脸上露出了狡黠的笑容,假设可以这么玩,那会有什么样的问题呢?
好吧,假设 Java 允许我们这样写
List那么接下来编译器需要来确定一下容器的具体类型,因为容器里面必须存放一种确定的对象类型,不然泛型也就没有诞生的意义了。那究竟是 Object 还是 Integer 呢?
假设一
假设它最终确定下来存放的是 Object,那就和如下代码是一样的效果了
List这种写法是 Java 7 引入的写法,官方称之为 diamond ,就是那一对空着的尖括号,使用这种写法时候编译器会自动推算出类型为 Object。这样就相当于赋值语句 ArrayList 中的泛型 Integer 毫无意义,那么无意义的操作 Java 显然是不允许的。
假设二
我们再假设最终确定下来的是存放的是 Integer,这样问题就更大了。因为我们都知道 Object 是所有类的基类,这就代表着 objList 可以添加任何类型的对象。即我们可以做如下操作
objList.add(new String());
objList.add(new Integer());
然后我们使用容器里面的对象的时候取出来需要将它强制转换为 Integer 对象,如果容器中本来就存放的是 Integer 的对象还好,如若不是就会出现 ClassCastException。有没有发现,这样不是恰如回退到没有泛型的 Java 版本了,即 Java 1.5 之前。我们使用容器不能在编译期间保证它的类型安全了,历史回退这种傻傻的操作 Java 也绝对是不允许的。
经过如上的一通分析我们发现泛型它就是不能这么玩,而且这么玩也是毫无意义。
这个时候面试官微微的点点头,表示略有赞同,你以为终于可以结束这样各种假设的骚操作了。面试官嘴角再次漏出狡黠的笑容,前面你说 List 和 ArrayList 不是父子关系,那泛型里面有父子关系吗或者说 List 和 ArrayList 是否存在着某种关系?
好吧。它们是兄弟,都是 List 的子类。也就是说,你可以这么玩:
List list1 = new ArrayList如上是 2 段代码是合法的,容器造出来了。那让我们来给容器里面塞一些对象进去吧。
list1.add(new Object());
不好意思你不能这么写,因为这 2 个容器里面可以存储任何东西,导致编译器都无法判断到底给里面会存储什么,它俩是 Read Only 哦。What? 那这有啥用呢?
好吧,假如有这样一个需求:写一个方法可以累加数字容器里面的元素值,那我们可以这样去写
public static long sumNumbers(List list) {
Long sum = 0l;
for (Object num : list) {
sum += ((Number) num).longValue();
}
return sum;
}
你可能注意到了,没错这里经历了一次强制类型转换,万一方法的调用方传入的是 new ArrayList() 那么此处你可能会接到一个 ClassCastException 了。那有没有好的解决办法呢?有!
public static long sumNumbers(List list) {/****/}
我们将方法的参数改为了 List list ,这样当调用方试图传入非 Number 类型的容器实例时候在编译期就会直接报错咯,嘿嘿。
当然啦,你也可以通过 super 关键字来设置泛型参数的下限,例如 List list ,那这个时候调用方法的时候就只能传入泛型参数是 Number 或者 Number 的父亲级别的容器了。
好了,这就是本题的答案啦。想必回答到此处以后,面试官心里一定心里在想:“小伙子有点东西啊”。
以上即为昨天的问题的答案,小伙伴们对这个答案是否满意呢?欢迎留言和我讨论。
问题 10
你好同学,我是今天的面试官。咱们来聊聊平时开发中为什么要使用线程池技术,Java 线程池它具体是怎么实现的?
好处多多
假设我们不使用线程池技术,那么就在任务来临时刻启动一个新的线程,任务处理结束,释放线程资源。但是启动和销毁线程对服务器来说是比较耗费性能的一件事情,首先当任务来临时候,由于需要创建新的线程,会造成任务的延迟,其次频繁的创建和销毁线程也造成了大量不必要的资源浪费。在使用线程池以后,线程处理完当前任务以后不会被销毁,当新任务来临时候会重新利用已经创建好的线程,避免了创建销毁线程的开销,同时由于任务来临时线程已经就绪,也提高了服务的吞吐量。在平时的工作中,有很多地方都使用到了这种池化技术,例如数据库连接池,网络请求连接池,在比如说 JDK 中字符串常量池也可以认为是一种池化技术。
Java 线程池怎么玩
想玩明白 Java 的线程池,只需要的知道构建线程池的几个参数具体的含义基本上就明了了。那么接下来,就让我们一一瓦解这些参数。
corePoolSize
我们假设有 N 个任务需要提交到线程池去处理,当任务数量 N 小于核心线程数 corePoolSize(后文用 C 来代替) 的时候,线程池会不断新建线程来处理用户提交进来的任务即使有线程空闲。C 其实代表的是线程池通常情况下会保留的线程数量(如果将线程池比作一个工厂,C 可以类比为工厂的正式编制人员数量),当任务数量 N 超过核心线程数量 C 的时候,线程池就要用到下一个参数 workQueue 了。
workQueue
当用户提交的任务数量变多了,这时候线程池中的线程数量已经达到核心线程数 C,那么只能将提交过来的任务暂存在 workQueue 队列中。每当有线程处理完手头上活的时候就会来工作队列领取任务,如果队列中没有任务,那么当前线程就阻塞在队列上,等待任务。工作队列可以简单分为 2 种:无界队列和有界队列。
无界队列
如果我创建线程池的传入的是无界队列,那么意味着用户可以源源不断的提交任务到线程池,而不需要担心线程池拒绝接收,例如 LinkedBlockingQueue 就是一种选择。
有界队列
如果我们传入的是有界队列,例如 ArrayBlockingQueue,那就需要考虑队列存满了怎么办?不用担心这个时候线程池会帮忙找一些临时工来干活,这就需要用到下一个参数 maximumPoolSize 了。
maximumPoolSize
此时所有的核心线程都在干活,而且工作队列也存满了任务。如果还是有任务提交进来,那么线程池会再创建新的线程来帮助工作(可以类比为一个工厂,管理员发现任务太多,仓库也堆满了任务需要雇佣一些临时工来帮助干活)。当然临时工也不能雇佣太多,毕竟工厂资源有限,需要设定工厂里面工人最大上限,这个就是 maximumPoolSize 了。然而疯狂的用户哪管你能不能处理完任务,还是不断的提交任务进来,这个时候线程池忍无可忍了,关门拒绝用户提交新的任务,这时候 RejectedExexcutionHandler 就要开始发挥作用了。
RejectedExexcutionHandler
线程池共提供了如下 4 种拒绝策略
AbortPolicy 策略会抛出一个 RejectedExecutionException 异常给用户,告诉它任务被拒绝了。
DiscardPolicy 策略当任务来临时候不会给用户任何反馈,悄无声息拒绝任务。
DiscardOldestPolicy 策略比较霸道,它会直接将最早存储在工作队列的任务丢弃掉,然后再试图去执行当前提交进来的任务。
CallerRunsPolicy 策略呢虽然线程池中的工人不帮忙处理任务了,它会占用用户线程去处理当前任务,这也就意味着用户线程要处理完当前任务才可以做其他事情。
使用上面的几个核心参数完美的解决了任务的提交流程和工作分配问题,接下来就要来考虑一下后面的工作了。用户提交了一大波任务以后,就不在提交了。这时候线程池的中工人都还在呢,如果一直保留这些资源但是又没有活干,会造成资源的浪费。这时候就需要用到 keepAliveTime 和 TimeUnit 参数了。
keepAliveTime 和 TimeUnit
这 2 个参数组合起来决定了一个工人最多可以在工厂里愉快的摸鱼时间,如果摸鱼时间超过这个限度,这个工人资源就会被释放,也就是这个空闲线程资源就被回收掉咯。当然啦,线程池会保留核心线程在工厂里面等待新任务,以备有新任务的到来,我们也可以通过 public void allowCoreThreadTimeOut(boolean value) 方法设置参数,来允许线程池也可以释放核心线程。
threadFactory
还剩下最后一个参数,它比较简单,主要用来创建线程,例如我们想让线程池中的线程做一些定制化的工作就可以自己来定义线程工厂,这样线程池创建线程的时候就使用我们指定的工厂了。
你可能会觉得构建一个线程还要设置这么参数,太麻烦了,贴心的 JDK 帮我们在 Executors 中准备了几个静态工厂方法,我们一起看一下它们的特性:
newFixedThreadPool(int nThreads) 可以创建一个固定线程数量的线程池,同时它的工作队列是一个无界队列。
newSingleThreadExecutor() 可以创建只有一个线程工作的线程池,同时它的工作队列也是无界队列。
newCachedThreadPool() 可以创建一个没上限工作线程的线程池,它使用了 SynchronousQueue 只要有任务过来,如果有空闲的线程,会优先利用空闲的线程池,没有空闲线程就会新创建线程。
newSingleThreadScheduledExecutor() 创建的是一个具有延迟和循环执行任务线程池,同时它内部也只有一个线程,它的工作队列是一个具有延迟功能的队列 DelayedWorkQueue。
newWorkStealingPool() 这种方法是 Java 8 提供的,它实际创建的是一个 ForkJoinTool 而不是 ThreadPoolExecutor 的实例。
如上即为 5 中创建线程池的工厂方法,大家根据需要选择适合自己工作的,当然也可以直接使用 ThreadPoolExecutor 来创建一个。
以上即为昨天的问题的答案,小伙伴们对这个答案是否满意呢?欢迎留言和我讨论。
问题 11
不管你平时是否接触大量的 IO 网络编程,IO 模型都是高级 Java 工程师面试非常高频的一道题。你了解 Java 的 IO 模型吗?多路复用技术是什么?
我的答案
在了解 Java IO 模型之前,我们先来明确几个概念,初学者通常会被如下几个概念给误导:
同步和异步
同步指的是当程序在做一个任务的时候,必须做完当前任务才能继续做下一个任务,这是一种可靠有序的运行机制,假设当前任务执行失败了,可能就不会进行下一个任务了,往往在一些有依赖性的任务之间,我们使用同步机制。而异步恰恰相反,它不能保证有序性。程序在提交当前任务后,并不会等待任务结果,而是直接进行下一个任务,通常在一些任务之间没有依赖性关系的时候可以使用异步机制。
这么说可能还是有点抽象,我们举个例子来说吧。假设有 4 个数字 a, b, c, d,我们需要计算它们连续相除的结果。那么可以写这样一个函数:
public static int divide(int paraA, int paraB) {
return paraA / paraB;
}
如上即为我们的方法,假设我们使用同步机制去做,程序会写成类似如下这样:
int tmp1 = divide(a, b);
int tmp2 = divide(tmp1, c);
int result = divide(tmp2, d);
此处假如我们定义了 4 个数字的值为如下:
int a = 1;
int b = 0;
int c = 1;
int d = 1;
这时候我们编写的同步机制的程序,tmp2 的计算需要依赖于 tmp1,result 又依赖于 tmp2,事实上计算 tmp1 的值时候即会发生除数为的 0 的异常 ArithmeticException。
我们也可以通过多线程来将这个程序转换为异步机制的方式去做,如下(我们不考虑整数进位造成的结果不同问题):
Callable cA = () -> divide(a, b);
FutureTask taskA = new FutureTask<>(cA);
new Thread(taskA).start();
Callable cB = () -> divide(c, d);
FutureTask taskB = new FutureTask<>(cB);
new Thread(taskB).start();
int tResult = taskA.get() / taskB.get();
如上我们使用多线程将同步的运作的程序修改为了异步,先去同时计算 a / b 和 b / c 的结果,它俩之间没有相互依赖,taskB 不会等待 taskA 的结果,taskA 出现 ArithmeticException 也不会影响 taskB 的运行。
这就是同步与异步,你 get 到了吗?
阻塞和非阻塞
阻塞指的是当前线程在执行运算的时候会阻塞直到预期的结果出现后,线程才可以继续进行后续的操作。而非阻塞则是在执行某项操作后直接返回,无论结果是什么。是不是还有点抽象,我们来举个例子。改造一下上面的 divide 方法,将 divide 方法改造为会阻塞的方法:
public synchronized int blockingDivide(int paraA, int paraB) throws InterruptedException {
synchronized (SyncOrAsyncDemo.class) {
wait(5000);
return paraA / paraB;
}
}
如上,我们将 divide 方法修改为了一个会阻塞的方法,当我们的主线程去调用 blockingDivide 方法的时候,该方法会将当前线程阻塞直到方法运行结束。我们也可以使用多线程和回调将该方法修改为一个非阻塞方法:
public synchronized void nonBlockingDivide(int paraA, int paraB, Callback callback) throws InterruptedException {
new Thread(new Runnable() {
@Override
public void run() {
synchronized (SyncOrAsyncDemo.class) {
try {
wait(5000);
} catch (InterruptedException e) {
e.printStackTrace();
}
callback.handleResult(paraA / paraB);
}
}
}).start();
}
如上,我们将业务逻辑包装到了一个单独的线程中,执行结束后调用主线程设置好的回调函数即可。而主线程在调用该方法时不会阻塞,会直接返回结果,然后进行接下来的操作,这就是非阻塞机制。
弄清楚这几个概念以后,让我们一起来看看 Java IO 的几种模型吧。
Blocking IO(同步阻塞 IO)
在 Java 1.0 时代 JDK 提供了面向 Stream 流的同步阻塞式 IO 模型的实现,让我们用一段伪代码实际感受一下:
try (ServerSocket serverSocket = new ServerSocket(8888)) {
while (true) {
Socket socket = serverSocket.accept();
// 提交到线程池处理后续的任务
executorService.submit(new ProcessRequest(socket));
}
} catch (Exception e) {
e.printStackTrace();
}
我们在一个死循环里面调用了 ServerSocket 的阻塞方法 accept 方法,该方法调用后会阻塞直到有客户端连接过来。如果此时有客户端连接了,任务继续进行,我们此处将连接后的处理放在了线程池中去处理。接着我们模拟一个读取客户端内容的逻辑,也就是 ProcessRequest 的内在逻辑:
try (BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()))) {
int ch;
while ((ch = reader.read()) != -1) {
System.out.print((char)ch);
}
} catch (Exception e) {
e.printStackTrace();
}
我们采用 BufferedReader 读取来自客户端的内容,调用 read 方法后,服务器端线程会一直阻塞直至收到客户端发送的内容过来,这就是 Java 1.0 提供的同步阻塞式 IO 模型。
Non-Blocking IO(同步非阻塞 IO)
在 Java 1.4 时代 JDK 为我们提供了面 Channel 的同步非阻塞的 IO 模型实现,同样以一段伪代码来展示:
try {
ServerSocketChannel serverSocketChannel = ServerSocketChannel.open();
serverSocketChannel.bind(new InetSocketAddress("127.0.0.1", 8888));
while (true) {
SocketChannel socketChannel = serverSocketChannel.accept();
executorService.execute(new ProcessChannel(socketChannel));
}
} catch (Exception e) {
e.printStackTrace();
}
默认情况下 ServerSocketChannel 采用的阻塞方式,调用 accept 方法会阻塞直到有客户端连接过来,通过 Channel 的 read 方法获取管道里面的内容时候同样会阻塞直到客户端有内容输入到服务器端:
ByteBuffer buffer = ByteBuffer.allocate(1024);
while (true) {
try {
if (socketChannel.read(buffer) != -1) {
// do something
}
} catch (IOException e) {
e.printStackTrace();
}
}
这时候我们可以调用 configureBlocking 方法,将管道设置为非阻塞模式:
serverSocketChannel.configureBlocking(false);
这个时候调用 accept 方法就是非阻塞方式了,它会立即返回结果,但是返回结果有可能是 null,所以我们做额外的判断处理,如:
if (socketChannel == null) continue;
你需要注意的是此时调用 Channel 的 read 方法仍然会阻塞当前线程知道有客户端有结果返回,不是说非阻塞吗,怎么还是阻塞呢?是时候亮出大杀器 Selector 了。
Selector 多路复用器可以让阻塞 IO 变得更加灵活,注意注册 Selector 必须将 Channel 设置为非阻塞模式:
/**省略部分相同的代码**/
Selector selector = Selector.open();
serverSocketChannel.register(selector, SelectionKey.OP_ACCEPT);
while (true) {
selector.select();
Set keys = selector.selectedKeys();
Iterator iter = keys.iterator();
while (iter.hasNext()) {
SelectionKey key = iter.next();
iter.remove();
if (key.isAcceptable()) {
SocketChannel socketChannel = ((ServerSocketChannel)key.channel()).accept();
socketChannel.configureBlocking(false);
socketChannel.register(selector, SelectionKey.OP_READ);
}
if (key.isReadable()) {
SocketChannel channel = (SocketChannel) key.channel();
ByteBuffer buffer = ByteBuffer.allocate(1024);
if (channel.read(buffer) != -1) {
buffer.flip();
System.out.println(Charset.forName("utf-8").decode(buffer));
}
key.cancel();
}
}
}
使用了 Selector 以后,我们会使用它的 select 方法来阻塞当前线程直到监听到操作系统的 IO 就绪事件,这里首先设置了 SelectionKey.OP_ACCEPT,当 select 方法返回时候代表 accept 已经就绪,服务器端与客户端可以正式连接,这时候的连接操作会立即返回属于非阻塞操作。
当与客户端建立连接后,我们关注的是 SelectionKey.OP_READ 事件,伪代码中使用
socketChannel.register(selector, SelectionKey.OP_READ)
注册了这个事件,当 select 方法再次返回时候代表 IO 目前已经到达可读状态,可以直接调用 channel.read(buffer) 来读取客户端发送过来的内容,这时候的 read 方法同样是一个非阻塞的操作。
如上就是 Java 1.4 为我们提供的非阻塞 IO 模式加上 Selector 多路复用技术,从而摆脱一个客户端连接占用一个线程资源的窘境,此处只有 select 方法阻塞,其余方法都是非阻塞运作。
虽然多路复用技术在性能上带来了提升,但是你也看到了。非阻塞编程相对于阻塞模式的代码段变得更加复杂了,而且还需要处理 NPE 问题。
Async Non-Blocking IO(异步非阻塞 IO)
Java 1.7 时代推出了异步非阻塞的 IO 模型,同样以一段伪代码来展示一下:
AsynchronousServerSocketChannel serverChannel = AsynchronousServerSocketChannel
.open()
.bind(new InetSocketAddress(8888));
serverChannel.accept(serverChannel, new CompletionHandler() {
@Override
public void completed(AsynchronousSocketChannel result, AsynchronousServerSocketChannel attachment) {
serverChannel.accept(serverChannel, this);
ByteBuffer buffer = ByteBuffer.allocate(1024);
/**连接客户端成功后注册 read 事件**/
result.read(buffer, buffer, new CompletionHandler() {
@Override
public void completed(Integer result, ByteBuffer attachment) {
/**IO 可读事件出现的时候,读取客户端发送过来的内容**/
attachment.flip();
System.out.println(Charset.forName("utf-8").decode(attachment));
}
/**省略无关紧要的方法**/
});
}
/**省略无关紧要的方法**/
});
你会发现异步非阻塞的代码量很少,而且 AsynchronousServerSocketChannel 的 accept 方法使用后完全不会阻塞我们的主线程。主线程继续做后续的事情,在回调方法里面处理 IO 就绪事件后面的流程,这与前面介绍的 2 种同步 IO 模型编程思想上有比较大的区别。
想必通过开头介绍的几个概念你已经可以想到这款异步非阻塞的 IO 模型背后的实现原理了,无非就是 JDK 帮助我们启动了单独的线程,将同步的 IO 操作转换为了异步的 IO 操作,同时利用操作的 IO 事件模型,将阻塞的方法转换为了非阻塞的方法。
当然啦,NIO 为我们提供的也不仅仅是 Selector 多路复用技术,还有一些其他黑科技我们没有提到,感兴趣的话欢迎关注我等待后续的内容。
如上就是 Java 给我们提供的三种 IO 模型,通过我们一起探讨,你现在是不是已经掌握了它们之间的区别呢?欢迎留言与我讨论。
以上即为昨天的问题的答案,小伙伴们对这个答案是否满意呢?欢迎留言和我讨论。
问题 12
上一期中我们一起讨论了 Java 的三大 IO 模型,说到其中的 Non-Blocking IO 就不得不提零拷贝技术,你知道零拷贝技术吗?
我的答案
想要弄清楚什么是零拷贝,首先得明确一个问题,这里的拷贝指的是什么?我们这里所描述的 拷贝 指的是在应用程序中将文件从 A 拷贝到 B,其中的 A 和 B 可以是电脑上的磁盘文件,也可以是网络中的文件。像这样的拷贝操作在操作系统中经历了复杂的操作,首先应用程序发起读取文件操作,读取到文件后又发起写入文件操作或者写到网络中去。
传统的数据传输
了解传统数据传输之前,我们要明确用户态和内核态 2 个概念:
用户态 是非特权执行状态,该状态下运行的程序被操作系统禁止进行一些危险操作,例如写入系统配置文件,杀死其他用户进程,重启系统,不可直接访问硬件设备。
内核态 是高级别特权执行状态,运行在该状态下的程序通常为操作系统程序,具有高的特权级别,拥有访问设备的所有权限。
读、写操作,在我们看来是一个完整的操作,其实在操作系统内部将读操作又进行了细化拆分。
首先操作系统需要从用户态切换到内核态,在内核态将文件内容从磁盘读取到内核空间缓冲区中。
然后切换到用户态,将文件内容从内核空间缓冲区读取到用户空间。
而写操作正好是一个逆向的过程,程序需要先将文件内容写到内核空间缓冲区,然后从用户态切换到内核态,再将内容写到磁盘里,最后切换回用户态。图示为如下:
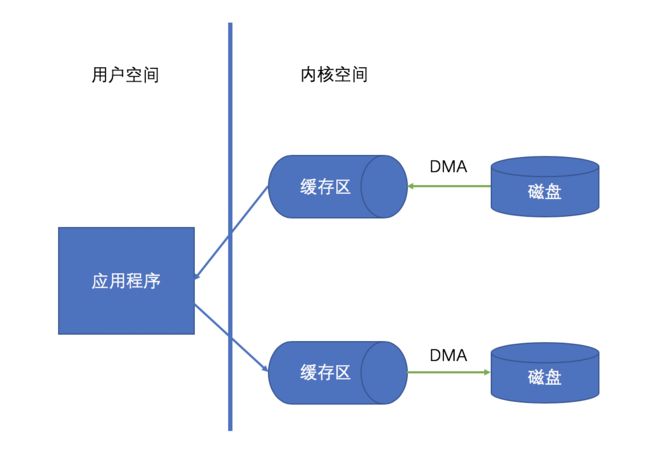
聪明的宝宝肯定注意到了,这其中涉及到了 4 次的上下文切换和 4 次的数据拷贝操作,其中磁盘与内核态进行的拷贝操作应用了 DMA 技术(全称 Direct Memory Access,它是一项由硬件设备支持的 IO 技术,应用这项技术可以更好的利用 CPU 资源,在此期间 CPU 可以去做其他事情),而内核态缓冲区到应用程序传输数据需要 CPU 的参与,在此期间 CPU 不能做其他工作。
mmap 提升拷贝性能
mmap 是一种内存映射的方法,它可以将磁盘上的文件映射进内存。用户程序可以直接访问内存即可达到访问磁盘文件的效果,这种数据传输方法的性能高于将数据在内核空间和用户之间来回拷贝操作,通常用于高性能要求的应用程序中。
因为用户态和内核态的上下文切换以及 CPU 数据拷贝是耗时的操作,所以可以考虑减少数据传输过程中的上下文切换和繁多的 CPU 拷贝数据操作,从而来提升数据传输性能。采用 mmap 来代替 read 系统调用可以有效减少内核空间到用户空间之间的 CPU 拷贝数据操作,于是就诞生了如下的工作情形:
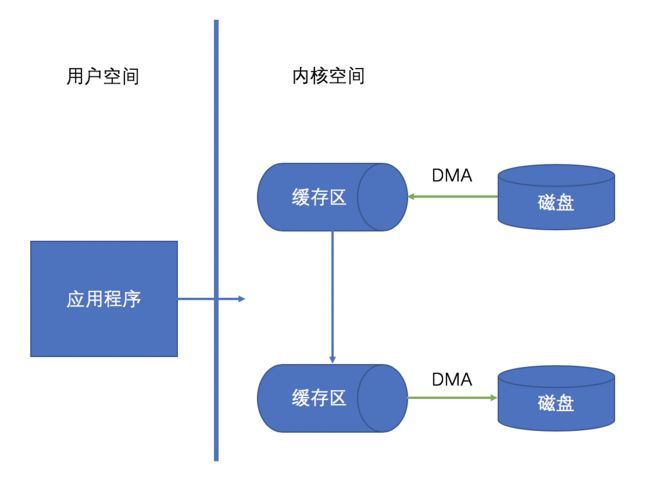
观察如上拷贝示意图,我们可以发现此时上下文切换操作缩减到了 2 次,应用程序发起拷贝操作后切换到内核态,数据直接在内核态完成传输而不需要拷贝到用户态,但是此处仍然进行了 3 次拷贝操作,其中还包含一次耗时的 CPU 拷贝操作。别着急,接下来我们看看终极版零拷贝。
零拷贝技术
我们知道 DMA 技术是高效的,因此只要去除掉 CPU 拷贝操作即可大大的提升性能。在 Linux 内核 2.1 版本中引入了 sendfile 系统调用,采用这种方式后内核态的缓冲区之间不再进行 CPU 拷贝操作,只需要将源数据的地址和长度告诉目标缓冲区,然后直接采用 DMA 技术将数据传输到目的地,如下图示:
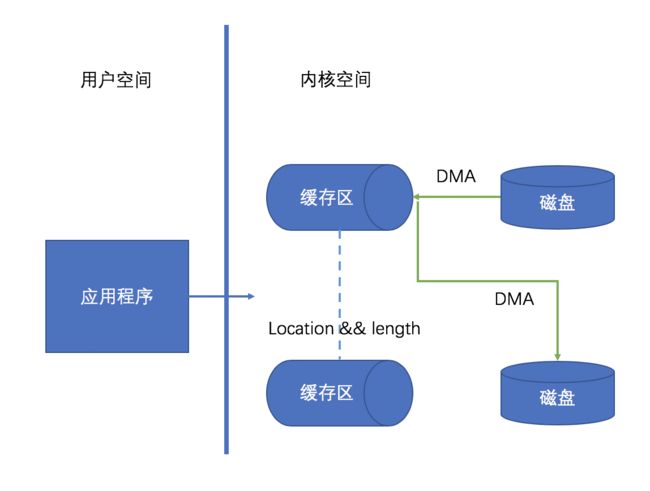
如上采用 sendfile 已经剔除了所有耗时的 CPU 拷贝操作,相比于传统的数据拷贝操作性能更高,这就是所谓的零拷贝技术。
Java 中的零拷贝
使用传统的文件拷贝方式在 Java 你会看到如下样板代码:
try (FileInputStream fis = new FileInputStream("sourceFile.txt");
FileOutputStream fos = new FileOutputStream("targetFile.txt")) {
byte datas[] = new byte[1024*8];
int len = 0;
while((len = fis.read(datas)) != -1){
fos.write(datas, 0, len);
}
}
使用如上方式进行文件拷贝的内在执行原理就如我们开头的介绍的那样,经过了多次用户态和内核态的切换,并且伴随着耗时的 CPU 拷贝操作,可想而知在遇到大文件拷贝时候效率会比较低下,此时可以考虑使用零拷贝技术。
在 Java 1.4 中, FileChannel 的 transferTo 方法即引入了零拷贝技术,让我们来一起看一下,如何使用它来提升性能吧。
RandomAccessFile sourceFile = new RandomAccessFile("sourceFile.txt", "rw");
FileChannel fromChannel = sourceFile.getChannel();
RandomAccessFile targetFile = new RandomAccessFile("targetFile.txt", "rw");
FileChannel toChannel = targetFile.getChannel();
fromChannel.transferTo(0, fromChannel.size(), toChannel);
如上我们首先获取 FilleChannel,然后调用 FileChannel 的 transferTo 方法即可实现零拷贝操作。内在执行原理就是使用 sendfile 系统调用,剔除了耗时的 CPU 拷贝操作,同时用户态和内核态的上下文切换也是最少的,当你遇到文件拷贝的性能问题时,你可以考虑一下 FilleChannel。
FileChannel 中还提供了其他的方法,例如 transferFrom 方法,感兴趣的小伙伴可以自己尝试一下。
总结
以上即为比较高频的 12 道毛毛虫认为的高频 Java 面试题,由于个人能力有限,文中难免有所疏漏,希望大家多多指正。
欢迎有疑问的小伙伴留言与我交流,也欢迎有志于深入技术钻研的同学加入公众号 Java dev 一起探讨学习,一起交流,offer 来得更简单点。
