关于新型冠状病毒肺炎疫情追踪的可视化数据的采集、处理
关于新型冠状病毒肺炎疫情追踪的可视化数据的采集、处理
最终效果图


数据来源:https://news.qq.com/zt2020/page/feiyan.htm
数据采集:使用谷歌浏览器自带的开发者工具进行数据包抓取
采集过程:进入网页后,使用开发者工具进行数据包捕获,

按钮为红色即说明进入捕获状态,接着我们刷新一下页面

可以发现里面有很多数据包,我们需要的数据是全国确诊人数、疑似病例、治愈人数等等数据,那么如何抓取我们需要的数据呢?
其实在开发者工具里有一个搜索按钮,如下图
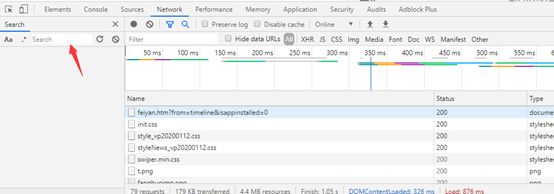
接着利用它来搜索我们需要的数据,比如全国确诊的数据

接着我们看搜索结果的第一条的Response的内容,可以发现这是条json数据,确认后发现,这些数据这正是网页数据的来源。
![]()
在其Hearders中可以看到,其传递数据的方式是Get,我们可以直接复制它的URL,分析其中传递的参数
URL:https://view.inews.qq.com/g2/getOnsInfo?name=wuwei_ww_global_vars&callback=jQuery3410890567228054113_1580091530788&_=1580091530789
可以发现其中有两个参数,name与callback,其中从其callback参数传递的内容发现,这是一个关于时间的参数,
1580091530788还有1580091530789这个13位数字其实是时间戳,可jQuery后面加上的19位数字,我还不清楚如何生成,传入错误的参数可能会影响返回的结果,但由于不清楚这个参数如何生成,我们可以尝试省略callback这个参数。这样我们的URL就变成了https://view.inews.qq.com/g2/getOnsInfo?name=wuwei_ww_global_vars
由于传递数据的方式是Get,我们可以直接将其URL粘贴到浏览器上访问,得到了这个结果
既然不影响返回的结果,我们就可以将callback参数省略了,当然这个json数据只是全球总数据,并没有各个地区的数据,于是我们参照上面的步骤,继续抓包,得到了地区的数据。
URL:https://view.inews.qq.com/g2/getOnsInfo?name=wuwei_ww_area_counts
至此,数据采集完毕,接下来就是利用python进行数据处理了。
数据处理:
阶段一——python数据采集:由于我们需要网页抓包,所以我们要调用一些python的模块,如下:
- requests模块 (用于网页访问)
- re模块 (用于正则表达式,处理数据时需要)
- json模块 (用于解析json数据)
- openpyxl (用于将数据生成excel表格)
- 首先我们先import上述模块,定义一些列表,再将之前抓取的URL储存到变量中,如图
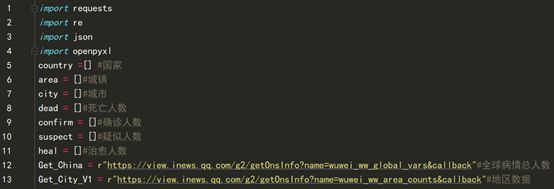
- 自行定义一个获取URL返回的Response的函数框架
我将其命名为GetHtmlText。

之所以用try/except语句是因为网页访问的过程中可能会遇到一些异常,如果不处理这些异常程序就会报错。这里的第18行语句的含义便是,如果访问出现异常,这条命令就会抛出一个异常,except就会处理这个异常,返回一个Error。整个GetHtmlText函数的意义就是获取URL中返回的Response。
接着我们定义一个China变量储存返回的Response,并print一下China,调试如图:

可见其成功返回了一个json数据,当然这个是总体情况,我们需要的是各个地区的数据。于是我们“故技重施”,只需要在GetHtmlText(url)函数中改变参数url即可,即将url改为https://view.inews.qq.com/g2/getOnsInfo?name=wuwei_ww_area_counts
从之前的图中可以看到,我已将这条url储存在Get_city_V1这个变量当中。利用一个变量将其Response储存,我们print调试一下

调试结果:
![]()
很顺利,依然成功返回了json数据。
接下来,我们的目的就是解析这条json数据了。
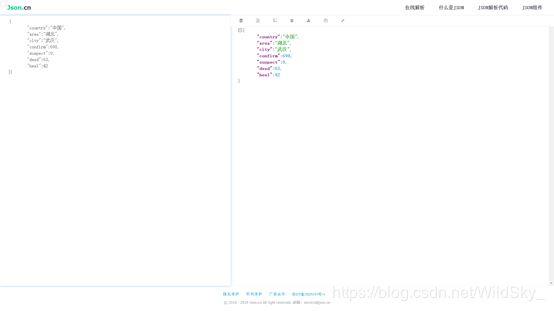
我们先用利用在线解析json数据的网站解析一下这条json数据
这里我推荐一个这样的网站:https://www.json.cn/
复制json数据后粘贴到其网站上,可看到结果:
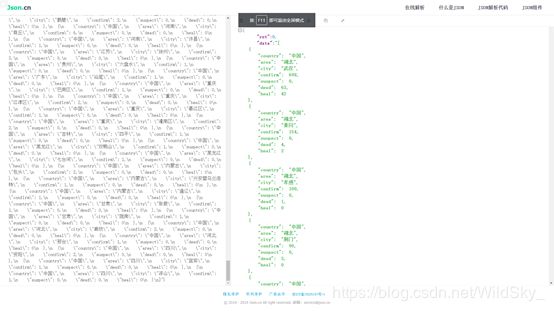
得知我们需要的数据在data中,于是我们利用json模块来解析,先将其json数据(字符串数据)转换为字典
![]()
取出其json数据中data字段的数据
![]()
到这些步骤之前,一切都很顺利,但是接下来遇到的一个问题,使我一宿没睡好,一直在想这个问题。
麻烦来了,处理之后的数据是这样的:
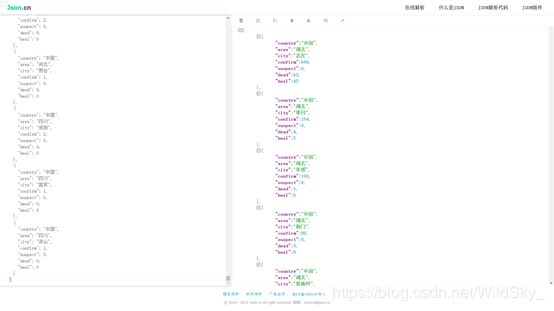
这些内容用中括号括了起来,这意味着此时此刻这条json数据是个数组,City_Data[]的[]里不能继续接受字符串了,只能接受整数,这样的话数据是没有办法提取出来的。
好在第二天想到了办法,我的做法是先将其中括号去掉,再试试单一的结构是否能接受字符串,结果如图:
太好了!这说明是能够解析的,于是接下来的工作就是想办法把这些单一的结构一一提取出来,并利用一个列表来储存它。那么用什么方式能够达到这个目的呢?正则啊!(拍脑袋)只需要匹配花括号中的内容,然后将花括号加回来就好了。
![]()
这样,一大难题就解决了。之后我们再定义一个函数,将其中的json数据全部储存之前代码开头声明的变量当中。但是不要忘记之前声明的变量是全局变量,在Python中,如果要在函数结构中使用这些变量需要要用到关键字global,否则Python之后将这些变量当作局部变量处理,那一切都白搭了。最后return一个i是为了获取地区数

至此,数据处理的阶段一,告一段落。
阶段二——python数据导入Excel:
首先,利用阶段一中的GetCityData储存数据,并且获取地区数(Length),
接下来进入数据Excel化过程

openpyxl.Workbook()的意思是创建一个工作簿,这里我声明一个wb来接受这个传递对象
ws = wb.active的意义是获取其创建的工作表
有了ws(worksheet)后 ,我们可以将python获取到的数据直接写入Excel表格当中,如图:
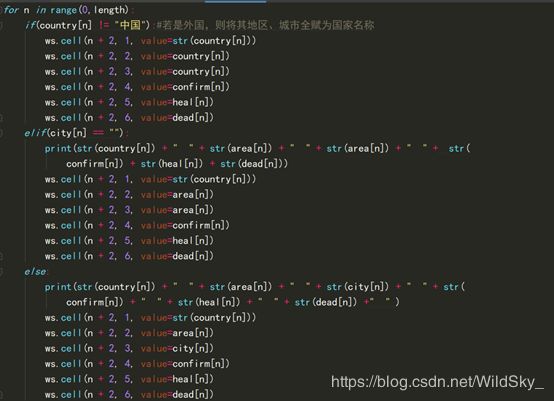
至此,表格数据已经全部处理完毕,最后,我们只需一条
wb.save('data.xlsx')
即可将目前还是储存在内存中的Excel表写到与python代码文件目录相同的位置当中了。
执行一遍代码后,打开刚刚生成的Excel表格。
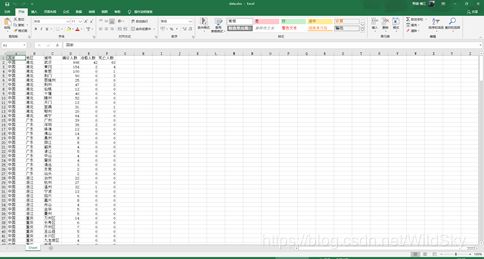
至此,数据处理阶段结束。接下来,就是利用可视化数据平台将收集到的Excel数据可视化处理。
数据可视化处理(以地图组件建立为例):这里我利用的是FineBI平台。
下载与学习地址:FineBI
阶段一:可视化数据准备
- 打开软件,进入搭建好的部署的本地服务器地址

- 点击创建
- 点击箭头所指

- 确定


- 选中之前生成的data.xlsx

- 待加载出数据后,点击确定即可

- 接着我们再次点击创建 点击确定


- 点击中间的


11. 选中刚刚创建的数据库 点击确定
至此,阶段一告一段落。
阶段二:可视化组件设置
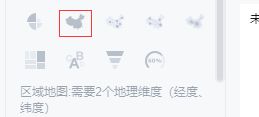
既然是全国疫情,而我们又抓取到了各个地区的数据,我们自然需要制作一个全国疫情的地图来实现数据的可视化的这样一个组件。
将鼠标移至图示区域,可看到提示,这需要2个地理纬度。
疫情的显示应该是越细越好的,所以我们转换维度需要以城市为目标。于是我们将数据处理一下,

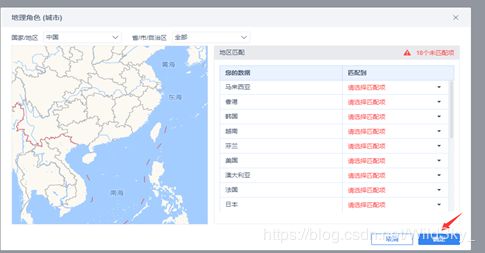
少部分地区没有匹配上,没关系,我们点击确定。
可以发现列表中生成了2个维度,我们将其拖动至横纵轴。


可以发现图标类型中地图类型亮了
选中它,变成了这样

可以发现虽然有效果,但是颜色的深浅不明显,我们需要让颜色有一个参考的数据,这里以确诊人数为例
将其拖动至图示位置

然后点击下面的红色区域:

改变渐变方案,这里选一个效果明显的即可

至此地图组件建立工作大部分完成

但从图中可以获取的信息显然还不足,它只显示了城市还有确诊人数,并没有显示治愈还有死亡人数,这里需要:
分别单击这三个元素 然后将其拖至提示:
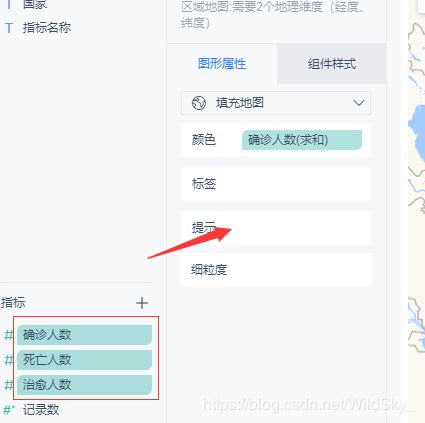
至此,地图组件实现可视化数据完成!
数据更新:
若要更新数据,只需要执行一遍Python代码后,将重新生成的data.xlsx文件在FineBI中如图:



重新上传一遍后,出现 然后点击右上角的确定即可。
然后点击右上角的确定即可。
Python代码
import requests
import re
import json
import openpyxl
country =[] #国家
area = []#城镇
city = []#城市
dead = []#死亡人数
confirm = []#确诊人数
suspect = []#疑似人数
heal = []#治愈人数
Get_China = r"https://view.inews.qq.com/g2/getOnsInfo?name=wuwei_ww_global_vars&callback"#全球病情总人数
Get_City = r"https://view.inews.qq.com/g2/getOnsInfo?name=wuwei_ww_area_datas&callback"#地区数据
Get_City_V1 = r"https://view.inews.qq.com/g2/getOnsInfo?name=wuwei_ww_area_counts&callback"#地区数据
def GetHtmlText(url):
try:
res = requests.get(url,timeout = 30)
res.raise_for_status()
res.encoding = res.apparent_encoding
return res.text
except:
return "Error"
China = GetHtmlText(Get_China)
def GetTextCenter(Text,TextLeft,TextRight):#取出中间文本
L = Text.find(TextLeft) + len(TextLeft)
Text = Text[L:]
R = Text.find(TextRight)
return Text[:R]
City_Count_json = json.loads(China) #获取总json数据
City_Count_json = City_Count_json["data"] #获取总json数据中的data数据
City_Count_json = re.findall(r"{[^}]+}",City_Count_json) #将数组对象内的对象提取出来
City_Count_json = json.loads(City_Count_json[0]) #将其转换为对象
recentTime = str(City_Count_json["recentTime"]) #GetTextCenter(China,r"\"recentTime\": \"",r"\",\n")#更新时间
confirmCount = str(City_Count_json["confirmCount"])
suspectCount = str(City_Count_json["suspectCount"])
deadCount = str(City_Count_json["deadCount"]) #GetTextCenter(China,r"\"deadCount\": ",r",\n") #疑似人数
cure = str(City_Count_json["cure"]) #GetTextCenter(China,r"\"cure\": ",r"\n") #治愈人数
hintWords = str(City_Count_json["hintWords"]) #GetTextCenter(China,r"\"hintWords\":
print("更新时间:" + recentTime + "\n" + "确诊人数为:" + confirmCount + "人\n" + "死亡人数为:" +
deadCount + "人\n" + "疑似人数为:" + suspectCount + "人\n" + "治愈人数为:" + cure +
"人\n" + "最新消息:" + hintWords + "\n")
City_json = GetHtmlText(Get_City_V1)
City_Data = json.loads(City_json)
City_Data = City_Data["data"]
City_Data = re.findall(r"{[^}]+}",City_Data)#CitysJson
def GetCityData(CitysJson):#获取精确信息,返回成员长度
global country # 国家
global area # 城镇
global city # 城市
global dead # 死亡人数
global confirm # 确诊人数
global suspect # 疑似人数
global heal # 治愈人数
i = len(CitysJson)#获取json数据有多少个成员
for j in range(0,i):
data = json.loads(CitysJson[j])
country.append (data["country"])
area.append (data["area"])
city.append (data["city"])
dead.append(data["dead"])
confirm.append(data["confirm"])
suspect.append(data["suspect"])
heal.append(data["heal"])
return i
length = GetCityData(City_Data)
print("国家 地区 城市 确诊人数 治愈人数 死亡人数 ")
wb = openpyxl.Workbook()
ws = wb.active
print(wb.get_sheet_names())
ws.cell(1,1,value="国家")
ws.cell(1,2,value="地区")
ws.cell(1,3,value="城市")
ws.cell(1,4,value="确诊人数")
ws.cell(1,5,value="治愈人数")
ws.cell(1,6,value="死亡人数")
for n in range(0,length):
if(country[n] != "中国"):#若是外国,则将其地区、城市全赋为国家名称
ws.cell(n + 2, 1, value=str(country[n]))
ws.cell(n + 2, 2, value=country[n])
ws.cell(n + 2, 3, value=country[n])
ws.cell(n + 2, 4, value=confirm[n])
ws.cell(n + 2, 5, value=heal[n])
ws.cell(n + 2, 6, value=dead[n])
elif(city[n] == ""):
print(str(country[n]) + " " + str(area[n]) + " " + str(area[n]) + " " + str(
confirm[n]) + str(heal[n]) + str(dead[n]))
ws.cell(n + 2, 1, value=str(country[n]))
ws.cell(n + 2, 2, value=area[n])
ws.cell(n + 2, 3, value=area[n])
ws.cell(n + 2, 4, value=confirm[n])
ws.cell(n + 2, 5, value=heal[n])
ws.cell(n + 2, 6, value=dead[n])
else:
print(str(country[n]) + " " + str(area[n]) + " " + str(city[n]) + " " + str(
confirm[n]) + " " + str(heal[n]) + " " + str(dead[n]) +" " )
ws.cell(n + 2, 1, value=str(country[n]))
ws.cell(n + 2, 2, value=area[n])
ws.cell(n + 2, 3, value=city[n])
ws.cell(n + 2, 4, value=confirm[n])
ws.cell(n + 2, 5, value=heal[n])
ws.cell(n + 2, 6, value=dead[n])
wb.save('data.xlsx')
2020年1月31日 由于腾讯新闻的获取数据的数据源已经更换,所以在此重新抓取了一下数据,发现Json的格式也已经更换,重写了一份代码,如下:
import requests
import json
import openpyxl
Get_China=r"https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5"
class item:
def __init__(self):
self.country=list()#国家
self.province = list()#省份
self.area=list()#地区
self.confirm=list()#确诊
self.suspect=list()#疑似
self.heal=list()#治愈
self.dead=list()#死亡
Data_Box=item()#数据盒子
def GetHtmlText(url):
try:
res = requests.get(url,timeout = 30)
res.raise_for_status()
res.encoding = res.apparent_encoding
return res.text
except:
return "Error"
#获取Json
China = GetHtmlText(Get_China)
City_Count_json = json.loads(China)
City_Count_json = City_Count_json["data"]#将json数据中的data字段的数据提取处理
City_Count_json = json.loads(City_Count_json)#将提取出的字符串转换为json数据
#获取每日总信息
lastUpdateTime = City_Count_json["lastUpdateTime"]
chinaTotal_json = City_Count_json["chinaTotal"]#提取处其chinaTotal字段中的数据
confirmCount = str(chinaTotal_json["confirm"])
suspectCount = str(chinaTotal_json["suspect"])
deadCount = str(chinaTotal_json["dead"]) #GetTextCenter(China,r"\"deadCount\": ",r",\n") #疑似人数
cure = str(chinaTotal_json["heal"]) #GetTextCenter(China,r"\"cure\": ",r"\n") #治愈人数
print("更新时间:" + lastUpdateTime + "\n" + "确诊人数为:" + confirmCount + "人\n" + "死亡人数为:" +
deadCount + "人\n" + "疑似人数为:" + suspectCount + "人\n" + "治愈人数为:" + cure +
"人\n" )
######用于循环中备注信息,防止混淆变量名而出错,然而还是耗费了相当长的时间理清这些变量
#areaTree_json[i]["children"]省份
#areaTree_json[i]["children"][j]["name"]省份名
#areaTree_json[i]["children"][j]["children"][n]省份中的地区 list
#areaTree_json[i]["children"][j]["children"][n]省份中的地区 json
#areaTree_json[i]["children"][j]["children"][n]["name"]省份中的地区名
#areaTree_json[i]["children"][j]["children"][n]["total"]省份中的地区数据json {'confirm': 134, 'suspect': 0, 'dead': 0, 'heal': 4}
areaTree_json=City_Count_json["areaTree"]#包含国家、省份、地区的所有信息,且国家为首索引
def Get_Data_China():
country_len = len(areaTree_json)
for i in range(0,country_len):
if(areaTree_json[i]["name"]=="中国"): #如果为中国则说明具有省份信息
province_len = len(areaTree_json[i]["children"]) #获取省份长度
for j in range(0,province_len):
area_len=len(areaTree_json[i]["children"][j]["children"])#获取地区长度
for n in range(0,area_len):
total=areaTree_json[i]["children"][j]["children"][n]["total"] #获取地区的总体疫情情况+
Data_Box.country.append("中国")
Data_Box.province.append(areaTree_json[i]["children"][j]["name"])
Data_Box.area.append(areaTree_json[i]["children"][j]["children"][n]["name"])
Data_Box.confirm.append(total["confirm"])
Data_Box.dead.append(total["dead"])
Data_Box.heal.append(total["heal"]) #中国区域获取完毕
else:#外国区域
name=areaTree_json[i]["name"]
total=areaTree_json[i]["total"]
Data_Box.country.append(name)
Data_Box.province.append(name)
Data_Box.area.append(name)
Data_Box.confirm.append(total["confirm"])
Data_Box.suspect.append(total["suspect"])
Data_Box.dead.append(total["dead"])
Data_Box.heal.append(total["heal"]) #外国区域获取完毕
return len(Data_Box.area)
length=Get_Data_China()#获取信息并获取长度
print("国家 省份 地区 确诊人数 治愈人数 死亡人数 ")
for n in range(0,length):
print(Data_Box.country[n]+" "+Data_Box.province[n]+" "+Data_Box.area[n]+" "
+str(Data_Box.confirm[n])+" "+str(Data_Box.heal[n])+" "+ str(Data_Box.dead[n]))
def write(length):
wb = openpyxl.Workbook()
ws = wb.active
ws.cell(1, 1, value="国家")
ws.cell(1, 2, value="省份")
ws.cell(1, 3, value="地区")
ws.cell(1, 4, value="确诊人数")
ws.cell(1, 5, value="治愈人数")
ws.cell(1, 6, value="死亡人数")
for n in range(0,length):
ws.cell(n + 2, 1, Data_Box.country[n])
ws.cell(n + 2, 2, Data_Box.province[n])
ws.cell(n + 2, 3, Data_Box.area[n])
ws.cell(n + 2, 4, Data_Box.confirm[n])
ws.cell(n + 2, 5, Data_Box.heal[n])
ws.cell(n + 2, 6, Data_Box.dead[n])
wb.save("data_new.xlsx")
return
write(length)