Rocksdb 内存“不释放”问题 分析
文章目录
- 问题场景描述
- 问题复现
- 编写随机写 测试工具
- 使用工具抓取内存分配过程
- 源码分析
- memtable逻辑
- table_cache逻辑
- 总结

整体的IO场景到底层的源码分析过程如上导图,接下来将详细阐述具体的过程。
问题场景描述
我们的rocksdb作为单机存储引擎,跑在用分布式一致性协议raft 封装的一个分布式存储集群之上。基本的IO架构图如下:

针对该分布式存储集群,上层使用的是随机IO ,即每个raft交给rocksdb的请求所转化的key都是随机的。此时,rocksdb底层当然调用的是put的接口来持久化key-value数据。
问题现象是(同事给出的,我们只看到一个结果) 随着IO的持续写入,大概每个节点rocksdb数据的存储量都达到20G以上之后,top看到的IO 进程物理内存资源和实际的抓取的rocksdb tcmalloc分配的堆内存大小无法匹配,差距达到2-3倍。这个时候为了排除raft对内存消耗的影响,他将raft的写log逻辑去掉,IO仅仅经过协议栈到达底层rocksdb,但是他看到的日志以及内存占用仍然还是无法匹配,且内存持续增大无法释放,是不是rocksdb内部的存在内存泄露?
问题复现
业务场景 也就是随机put,且每次都必先,那么复现就很简单了,那单独的rocksdb来进行随机写测试,并抓取内存分布情况。
编写随机写 测试工具
这里说明一下为什么不实用rocksdb原生的db_bench进行测试,它功能更多,配置更强。
但是我们想要打印我们自己想看的东西,且排除它自己工具本身接口过多而产生的干扰,所以就直接自己写一个小工具,方便易用,抓取内存信息更为方便。
使用put接口进行随机写 测试工具的封装,以下代码提供如下功能
- 指定随机写 请求的个数
- 指定 key的范围,默认随机
- 指定value的大小
- 指定rocksdb compaction线程数
- 指定 put的客户端线程数
实现工具如下:
#ifndef __UTIL_H__
#define __UTIL_H__
#include 引用工具时只需要调用以上init和do_run两个函数,传入db名称即可
#include "util.h"
int main(int argc, char *argv[])
{
init(argc, argv);
do_test<rocksdb::DB, rocksdb::Options>("rocksdb");
}
以上代码在逻辑中已经增加了tcmalloc 的MallocExtension::instance()->GetStats(buff,2048);接口,可以打印tcmalloc的状态信息。
使用该接口时头文件需要指定#include ,编译选项之中需要加入-ltcmalloc,系统找不到tcmalloc的动态库,则需要制定动态库的加载路径env LD_PRELOAD="/usr/lib/libtcmalloc.so",关于gperftools的使用配置详细可以参考gperftools
使用工具抓取内存分配过程
-
valgrind + massif
这里很简单,使用如下命令让进程启动:
valgrind --tools=massif ./test_tools 10000000 0 256 32 100 1
关于valgrind的详细使用可以参考valgrind,这里在运行过程中massif会做很多次当前进程占用的物理内存快照,并且其中会有详细快照,即进程物理内存分配过程中的一个函数层级调用栈。valigrind默认抓取的是堆内存,如需要抓取mmap之类的匿名页分配的内存,需要指定对应的参数。运行一段时间之后终止进程,会在当前目录下生成一个.out文件,使用ms_print查看文件内容
结果类似如下

这里需要注意massif打印的并不是内存没有释放的,只是当前时刻进程物理内存的一个分布,但我们仍然能够看到一些由于的内存占用信息,一个是memtable创建的时候调用arena分配器分配的内存,还有一个是blockcache 存储解压缩数据的一个调用栈。
为了让数据更加全面准确,我们也使用gperf工具进行进程堆内存分配的一个数据收集。
-
gperf profiling + pprof数据收集
我们使用如下方式启动进程
env HEAPPROFILE=./rocksdb_profiling ./test_tools 10000000 0 256 32 100 1,此时同样会每隔一段时间会在当前文件夹下生成一个以rocksdb_profiling开头的heap文件
接下来我们使用工具pprof来查看内存占用情况
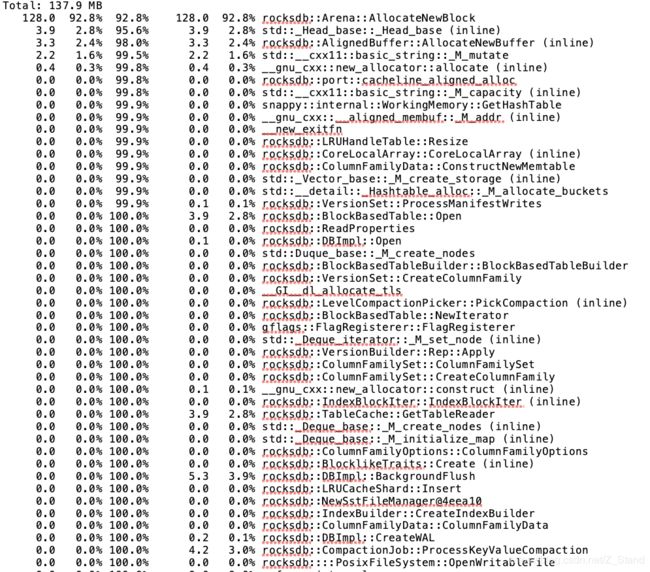
pprof --text ./test_tools ./rocksdb_profiling.0001.heap | vim -
打印如下重点关注第一列和第四列,分别表示该函数当前正在使用的内存和累计分配的内存
同样为了增加对比性,使用以下命令可视化打印以上占用内存较多的函数的calltrace
pprof --svg ./test_tools ./rocksdb_profiling.0001.heap >> rocksdb_profiling.svg
将生成的svg文件放入浏览器如下:

因为我们打印的时候没有过滤mmap以及sbrk等分配在匿名页上的内存占用情况,导致显示的数据只有16%的部分是arena分配memtable的占用,其他大都是pthread_create创建线程时使用mmap分配的内存。
可以通过如下命令过滤掉匿名页的内存统计:
pprof --svg --ignore='SbrkSysAllocator::Alloc|MmapSysAllocator::Alloc' ./test_tools ./rocksdb_profiling.0001.heap >> rocksdb_profiling.svg
在运行代码的过程中我们的二进制工具也会实时打印使用内部接口抓取到的内存占用数据以及tcmalloc的接口如下:
rocksdb.block-cache-usage : 0
rocksdb.estimate-table-readers-mem : 0
rocksdb.size-all-mem-tables : 50132416
simple_examples heap stats is : ------------------------------------------------
MALLOC: 50844816 ( 48.5 MiB) Bytes in use by application
MALLOC: + 876544 ( 0.8 MiB) Bytes in page heap freelist
MALLOC: + 341064 ( 0.3 MiB) Bytes in central cache freelist
MALLOC: + 0 ( 0.0 MiB) Bytes in transfer cache freelist
MALLOC: + 366376 ( 0.3 MiB) Bytes in thread cache freelists
MALLOC: + 2621440 ( 2.5 MiB) Bytes in malloc metadata
MALLOC: ------------
MALLOC: = 55050240 ( 52.5 MiB) Actual memory used (physical + swap)
MALLOC: + 0 ( 0.0 MiB) Bytes released to OS (aka unmapped)
MALLOC: ------------
MALLOC: = 55050240 ( 52.5 MiB) Virtual address space used
MALLOC:
MALLOC: 86 Spans in use
MALLOC: 7 Thread heaps in use
MALLOC: 8192 Tcmalloc page size
------------------------------------------------
Call ReleaseFreeMemory() to release freelist memory to the OS (via madvise()).
Bytes released to the OS take up virtual address space but no physical memory.
源码分析
通过以上两个组合工具已经抓取到了rocksdb随机写时对应的内存占用数据以及内存分配过程,且以上过程中我们抓数据的时候也都在观察top本身统计的无力内存占用大小,经过多方数据比对且数据量也能够达到业务问题的数据量,并未出现top实际的物理内存超过rocksdb本身统计的内存占用2-3倍的情况,差异最多只有20%。
带着疑惑先分析一下两个组合工具对内存数据的统计,如果在内存管理的逻辑上确实有不合理的地方那跟着内存分配的调用栈一看源码就知道了。
valgrind和gperf都统计到了arena的内存分配占用较多的情况,我们先看一下这个逻辑是否合理。
rocksdb的写入流程图如下,详细可以参考rocksdb 写入原理:

一个put请求会先写wal,再写memtable,由以上调用栈我们知道此时是在写memtable。同时我们上层是多个线程在put,rocksdb会为每个put绑定一个writer,并指定一个主writer 在batch_size的范围内负责先写入自己以及从writer的wal,同时从writer可以直接写memtable.
memtable逻辑
写入会与自己key-value所绑定的column family对应,从而保证cf的逻辑分区功能。
此时调用到了写入对应cf的函数,并将key-value数据添加到memtable之中:
Status PutCFImpl(uint32_t column_family_id, const Slice& key,
const Slice& value, ValueType value_type) {
......
MemTable* mem = cf_mems_->GetMemTable();
auto* moptions = mem->GetImmutableMemTableOptions();
// inplace_update_support is inconsistent with snapshots, and therefore with
// any kind of transactions including the ones that use seq_per_batch
assert(!seq_per_batch_ || !moptions->inplace_update_support);
if (!moptions->inplace_update_support) {
bool mem_res =
mem->Add(sequence_, value_type, key, value,
concurrent_memtable_writes_, get_post_process_info(mem),
hint_per_batch_ ? &GetHintMap()[mem] : nullptr);
......
}
之后就是memtale的写入,在刚开始的时候会根据传入key的大小,value的大小分配指定长度的空间
bool MemTable::Add(SequenceNumber s, ValueType type,
const Slice& key, /* user key */
const Slice& value, bool allow_concurrent,
MemTablePostProcessInfo* post_process_info, void** hint) {
// Format of an entry is concatenation of:
// key_size : varint32 of internal_key.size()
// key bytes : char[internal_key.size()]
// value_size : varint32 of value.size()
// value bytes : char[value.size()]
uint32_t key_size = static_cast<uint32_t>(key.size());
uint32_t val_size = static_cast<uint32_t>(value.size());
uint32_t internal_key_size = key_size + 8;
const uint32_t encoded_len = VarintLength(internal_key_size) +
internal_key_size + VarintLength(val_size) +
val_size;
char* buf = nullptr;
std::unique_ptr<MemTableRep>& table =
type == kTypeRangeDeletion ? range_del_table_ : table_;
KeyHandle handle = table->Allocate(encoded_len, &buf);
......
}
最终会调用到arena分配器分配指定的内存空间供数据存储
inline char* Arena::Allocate(size_t bytes) {
// The semantics of what to return are a bit messy if we allow
// 0-byte allocations, so we disallow them here (we don't need
// them for our internal use).
assert(bytes > 0);
if (bytes <= alloc_bytes_remaining_) {
unaligned_alloc_ptr_ -= bytes;
alloc_bytes_remaining_ -= bytes;
return unaligned_alloc_ptr_;
}
return AllocateFallback(bytes, false /* unaligned */);
}
所以以上逻辑本身就是一个正常的内存使用逻辑,key-value写入需要写写入到memtable之中,所以会分配对应空间来保存。同时关于memtable的释放,我们并不会一直占用memtable的空间,而是当memtable写入超过以上流程图显示的write_buffer_size的大小之后,会将当前memtable标记为只读的immutable memtable,从而开始向底层固化,并且会创建一个新的memtable来继续接受key-vale
内存中能够同时存在的memtable的个数取决于参数max_write_buffer_number,也就是immutable memtable向底层固化结束之后会被删除。
到此arena的分配即为正常的逻辑处理。
table_cache逻辑
但是在valgrind之中仍然有另一个内存占用较大的函数calltrace
UncompressBlockContentsForCompressionType
仍然先看以上的流程图,我们能够看到memtable是一个rocksdb存在于内存的数据结构,除了该文件之外rocksdb还有一些其他的数据结构用来管理存储在sst之上的key-value数据,以及一些常驻于内存用于提升索引性能的数据结构,他们都被封装在了block cache之中。同时另一个cache组件 tablecache是用来管理rocksdb内部产生读数据的一个存储组件,比如compaction过程中需要挑选每一层向下一层写入的文件的时候会将改文件的一些元数据读取到table cache之中,如果有过压缩,则会进行解压。
对应的逻辑如下:
当上层触发读的时候,会下发一个key,table_cache就站出来想要对当前读的数据做一个缓存来减少磁盘IO的次数,此时读请求会先下发到table_cache之下,拿着请求的key 从tablecache中的data block中索引key对应的value存储位置,这个时候主要是调用FindTable这个函数,在该函数中调用GetTableReader函数创建用于缓存key不在的情况的handle信息。
Status TableCache::FindTable(const FileOptions& file_options,
const InternalKeyComparator& internal_comparator,
const FileDescriptor& fd, Cache::Handle** handle,
const SliceTransform* prefix_extractor,
const bool no_io, bool record_read_stats,
HistogramImpl* file_read_hist, bool skip_filters,
int level,
bool prefetch_index_and_filter_in_cache) {
PERF_TIMER_GUARD_WITH_ENV(find_table_nanos, ioptions_.env);
Status s;
uint64_t number = fd.GetNumber();
Slice key = GetSliceForFileNumber(&number);
*handle = cache_->Lookup(key); //先从cache中查找该key是否存在,并返回一个cache句柄
TEST_SYNC_POINT_CALLBACK("TableCache::FindTable:0",
const_cast<bool*>(&no_io));
/*
如果没有找到,且判读此时没有IO,那么直接返回该key不存在。
如果此时有IO,则会加锁再尝试找一次(防止先put后get这样的情况,put的IO链路还未完成)
如果还是没有找到,则新建一个用于存放hanlde的缓存table_reader,放到table cache之中,用作当前key数据的缓存
*/
if (*handle == nullptr) {
if (no_io) { // Don't do IO and return a not-found status
return Status::Incomplete("Table not found in table_cache, no_io is set");
}
MutexLock load_lock(loader_mutex_.get(key));
// We check the cache again under loading mutex
*handle = cache_->Lookup(key);
if (*handle != nullptr) {
return s;
}
//尝试新建一个table_reader,用来存放handle的缓存
std::unique_ptr<TableReader> table_reader;
s = GetTableReader(file_options, internal_comparator, fd,
false /* sequential mode */, record_read_stats,
file_read_hist, &table_reader, prefix_extractor,
skip_filters, level, prefetch_index_and_filter_in_cache);
if (!s.ok()) {
assert(table_reader == nullptr);
RecordTick(ioptions_.statistics, NO_FILE_ERRORS);
// We do not cache error results so that if the error is transient,
// or somebody repairs the file, we recover automatically.
} else {
// 如果创建成功了,就把table_reader添加到cache之中
s = cache_->Insert(key, table_reader.get(), 1, &DeleteEntry<TableReader>,
handle);
if (s.ok()) {
// Release ownership of table reader.
// 添加成功之后,就把用于缓存hanlde 的table_reader释放掉,
table_reader.release();
}
}
}
return s;
}
接下来看一下GetTableReader 函数,主要是通过NewTableReader函数来进行table_reader的创建
Status TableCache::GetTableReader(
const FileOptions& file_options,
const InternalKeyComparator& internal_comparator, const FileDescriptor& fd,
bool sequential_mode, bool record_read_stats, HistogramImpl* file_read_hist,
std::unique_ptr<TableReader>* table_reader,
const SliceTransform* prefix_extractor, bool skip_filters, int level,
bool prefetch_index_and_filter_in_cache) {
......
s = ioptions_.table_factory->NewTableReader(
TableReaderOptions(ioptions_, prefix_extractor, file_options,
internal_comparator, skip_filters, immortal_tables_,
level, fd.largest_seqno, block_cache_tracer_),
std::move(file_reader), fd.GetFileSize(), table_reader,
prefetch_index_and_filter_in_cache);
...
}
最终的calltrace就如我们之前看到的打印栈一样,核心还是在没有从table_cache之中检测到key之后想要将key所代表的hanlde添加到cache之中,这个过程在完成之后会释放掉中间生成的临时数据结构table_reader(它是用来缓存key在table_cache中的数据的)。

总结
综上的源码分析,这样的memtable和table_cache 内存分配是完全属于正常逻辑,且持续大压力put的过程中并未复现内存问题。
于是带着数据、分析过程和源码 与同事进行核对,他也百思不得其解,无奈之下只好让他重新pull 最新代码,再来一轮测试。
那么奇迹出现了,他反复得按照之前的测试方式,rocksdb内存资源依旧稳若泰山。。。。。。最终呢,之前测试的代码版本是一波异常raft的处理逻辑,正常IO的时候会在内存缓存大量的临时数据结构无法释放,且不属于raft log,属于测试代码。今天重新搞了一波最终版本,一切重归于好。
计算机系统已经不再是一套简单系统,一个微小得改动就可能耗费几个人一天的时间,而能够规避这样的问题最好的办法就是引入一套完善严谨的规则来约束,缩小复杂系统的复杂度。