大数据代表技术:Hadoop、Spark、Flink、Beam
大数据代表技术:Hadoop、Spark、Flink、Beam
Hadoop:从2005年到2015年,说到大数据都是讲hadoop。Hadoop是一整套的技术框架,不是一个单一软件,它是一个生态系统。
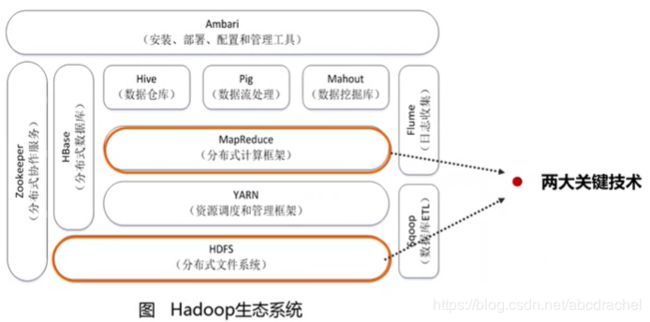
Hadoop有两大核心:第一个是它解决了分布式存储的框架叫HDFS,这是一个分布式存储系统。第二个是解决了分布式计算框架叫MapReduce。这是它的两大关键技术,除此以外,还有其他相关技术,构成了一个完整的生态系统。
HDFS:是海量分布式文件存储系统;
YARN提供资源调度和管理服务,它负责为我们的上层的计算框架MapReduce提供资源的调度和管理服务。因为计算框架MapReduce在做计算时需要CPU、内存等资源,这是需要YARN帮忙调度。它是在整个集群去进行调度,而集群可能有几千台机器,这几千台机器资源就由YARN这个框架进行统一调度;
MapReduce是一个计算框架,主要完成计算任务;
Hive:数据仓库。数据仓库跟数据库是不一样的:数据库只能保存某一时刻的状态数据,比如一个商品库存的数据库,原来有10件,卖出去一件,那个十就会被抹掉,这个库存就变成九,也就是说它不能记录其历史状态信息的;但是数据仓库一般以天为单位或以周为单位,然后每天保存一次它的镜像,其可以保存在每天某个固定时刻的库存数据,也就是说数据仓库是一个时间维度上的连续数据,比如说第一天的库存状态信息,第二天的库存状态信息,而我们的数据库只能保存某一个时刻的状态。
数据仓库是可以反映时间维度信息的数据,这样可以帮我们做一些决策分析,比如数据仓库里的OLAP分析(利用数据仓库里的数据进行多维数据分析),它可以帮忙分析商品销量走势,分析商品销量变化原因。
传统数据仓库都是构建在关系型数据库上,但是到了大数据时代,传统数据仓库已经不能满足,以为数据量太大,而关系型数据库根本就不能保存这么多数据,所以现在的大数据仓库都是构建在我们底层的HDFS的基础上,如Hive数据仓库都是保存在分布式文件系统HDFS基础上的。因此可以将Hive看着一个编程接口,它将SQL语句自动转换为对HDFS的查询分析,得到结果。
Pig 也是一个进行数据处理的框架,它提供了一个语言叫Pig Latin,该语言与SQL语言非常相似,它可以帮你把数据进行集成、转换、加载,也就是说我们在把数据保存在数据之前必须将数据进行清洗、转换,这个过程就需要使用Pig,它可以快速完成数据清洗转换工作,然后将其保存到数据仓库当中去进行分析。
Mahout组件是一个数据挖掘库,它可以实现常用数据挖掘算法,如分类、聚类、回归等。该组件是针对MapReduce写的常见的数据算法。但从2015年开始,Spark逐渐取代了MapReduce,MapReduce不再更新,而是全面转向Spark,也就是说现在的Mahout使用的算法库都是用Spark写的,而不是使用MapReduce。
HBase:因为很多数据还是需要数据库的,因此存在基于Hadoop的分布式数据库。HBase的底层数据仍是借用分布式文件存储系统进行保存的。
zookeeper:为分布式协作服务
Flune:日志采集分析,是一个分布式的采集系统
Sqoop:完成Hadoop系统组件之间的互通
Spark:它诞生于2009年,而在2015年迅速崛起,下面是Spark的架构图:

底层是Spark的核心主页Spark Core,它提供了相关的API,它提供了相关的数据抽象RDD,Spark Core可以完成RDD的各种各样的操作、开发等,在这基础上,Spark又提供了多种组件,满足我们在企业当中的不同的应用需求。
Spark SQL:处理关系型数据库
Spark Streaming:处理流技术需求,进行流计算
MLlib:封装了一些常见的机器学习算法库(采用Spark写的,提供了整套现成接口)
GraphX:满足图计算需求,编写图计算应用程序
因此Spark是一种可以满足多种企业需求的技能框架。
Spark与Hadoop的区别:
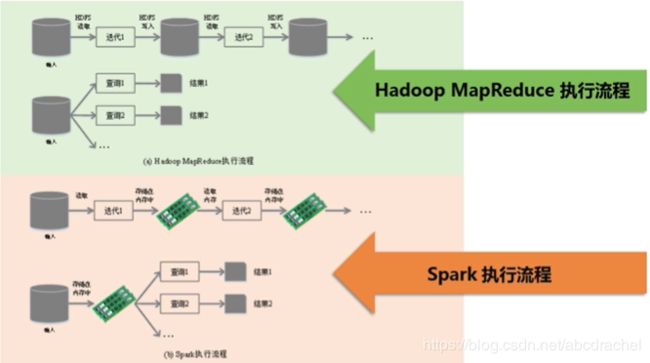
Hadoop存在一些缺陷,严格说应该是MapReduce存在缺陷,MapReduce因为分为Map和Reduce两步,非常简单,但也由于过于简单,很多方面不能进行表达,也就是说其表达能力有限;其次是因为Hadoop中的MapReduce都是基于磁盘计算,Map和Reduce之间的交互都是通过磁盘来完成的,因此磁盘IO开销非常大;另外其延迟比较高,Map和Reduce之间存在一个任务衔接,因为Map和Reduce是分阶段的,只有等所有的Map任务完成以后,Reduce任务才能开启运行,因此存在一个任务等待衔接的开销。同时多阶段迭代执行时,也会严重影响其性能。
Spark是继承了MapReduce的一些核心设计思想,对其进行改进,因此Spark本质上也属于MapReduce。Spark避免了MapReduce的一些缺陷:为了弥补表达有限,Spark不仅有Map和Reduce函数,还提供了更多比较灵活的数据操作类型,如filter、sort、groupby等,因此Spark编程模型更灵活,表达能力也更强大。另外MapRedcue是基于磁盘的计算框架,它是不断地读入磁盘、写磁盘,但Spark却提供了内存计算,可以高效地利用内存,包括很多数据交换都是在内存中完成的,因此可明显提供运行内存,尤其是进行迭代的时候,MapReduce进行迭代需要反复读写磁盘,Spark用内存去读写数据,不存在反复读写磁盘的问题。最后Spark是基于DAG(有向无环图)的任务调度执行机制,它可以进行相关优化,其可以形成流水线,通过有向无环图,就可以避免数据反复落地,不用落地就可以把它的输出直接作为另一个输入,这样形成流水线很快可以完成数据的高效处理。
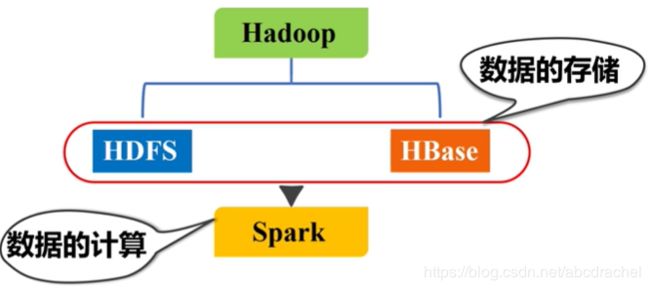
Spark替代的是Hadoop中的MapReduce,因为Spark是一个计算框架,不能进行存储
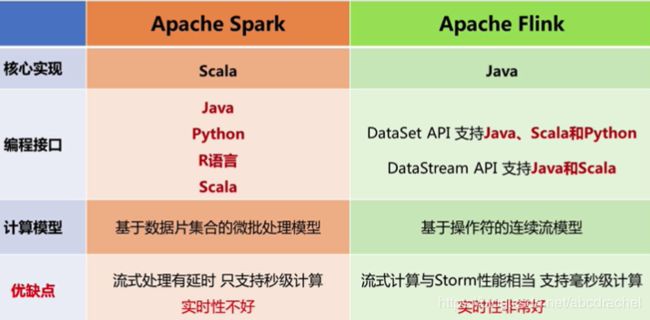
Spark可以用Scala、python、Java、R语言进行开发,但是首选是Scala语言,因为Spark这个框架本身是用Scala语言开发的,用Scala开发的应用程序才是最高校的应用程序。
Flink:与Spark功能相似
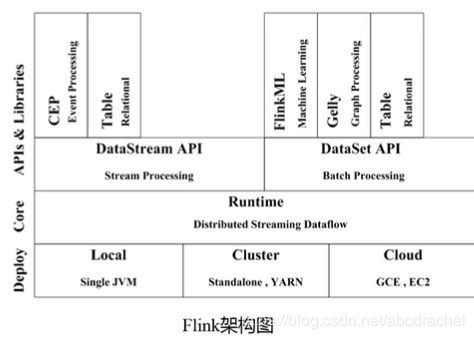
Flink是有柏林理工大学团队开发完成的,在2008年已形成雏形。Flink已形成了完备的形成,可以与Hadoop进行交互,它也是一个和Spark一样的计算框架,用Hadoop进行存储,然后用Flink进行计算。
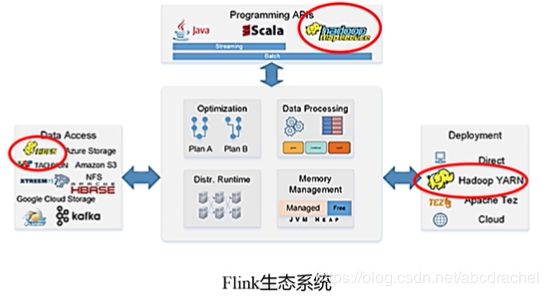
Spark与Flink的区别:
Flink以前有一部分是用Java编写的,后来一部分用Scala编写的,Spark是用Scala编写的
在接口方面,Spark提供了Java、Python、R、Scala语言,Flink也提供了相同的接口
计算模型方面,Flink是真正能满足实时性要求的计算框架,Spark是批处理的计算框架,而基于批处理的计算框架,都不能帮你真正实时响应(毫秒级),而Flink是可以的。Spark之所有能做流计算,是因为它将流切成一段一段,每一个小段做一个批处理,用每一个小段批处理去模拟批处理,而切成小段,最小的单位是秒,实现不了毫秒级。而Flink模型在设计时,是真正面向流数据的,它是以一行一行为计算单位,可以实现毫秒级计算,这个与Storm相似。
Beam:是一整套编程接口,它可以通过统一接口将程序运行到不同的平台上去
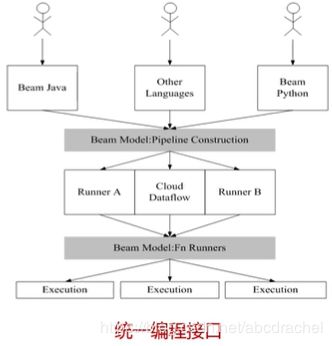
这个统一接口是基于Dataflow框架,它与其他框架不能完全兼容